在Python数据科学领域,丰富的工具库使得处理各种规模的数据变得更加便捷和高效。以下是一份详尽的Python数据科学工具大全,按照功能和用途分类整理:
数据导入/导出与预处理
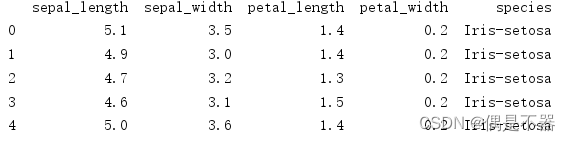
1. **Pandas** - 提供DataFrame数据结构,用于高效地处理表格型数据,支持读取CSV、Excel、SQL数据库等多种数据源,以及数据清洗、转换、合并等功能。
2. **NumPy** - 数值计算的基础包,提供了N维数组对象ndarray和大量数学运算函数,常作为Pandas和其他科学计算库的基础。
3. **pandas-profiling** - 自动化报告生成工具,快速生成数据概览报告,包含统计摘要、缺失值分析等。
4. **openpyxl** / **xlrd** / **xlwt** - Excel文件读写库。
5. **csv** / **json** / **pickle** - Python内置模块,分别用于处理CSV、JSON和序列化数据。
6. ** feather-format** / **parquet** - 高效的大数据存储格式,便于不同平台间的数据交换。
7. **sqlalchemy** - SQL工具包,用于Python程序与关系数据库交互。
数据可视化
1. **Matplotlib** - Python最基础的绘图库,可生成静态、动态、交互式的图表。
2. **Seaborn** - 建立在Matplotlib之上的统计图形库,提供了更高级别的接口和默认美学样式。
3. **Plotly** - 可生成交互式可视化图形,支持Web和Jupyter Notebook环境。
4. **Bokeh** - 用于创建交互式可视化应用和仪表板,适合大数据集展示。
5. **Altair** - 基于Vega-Lite语法的数据可视化库,强调声明式绘图。
数据分析与统计
1. **SciPy** - 科学计算库,包含了众多数学、统计和优化算法。
2. **Statsmodels** - 统计建模和推断工具包,提供经典统计测试、回归分析等功能。
3. **scikit-learn** - 机器学习库,涵盖了监督学习、无监督学习、模型评估等全面的ML算法。
4. **pandas-datareader** - 提供从Yahoo Finance、Google Finance等在线数据源获取金融数据的功能。
时间序列分析
1. **pandas-ta** - Pandas的一个扩展,提供了一系列的技术分析指标。
2. **statsmodels.tsa** - 提供时间序列分析方法,如ARIMA、季节性分解等。
大数据处理与分布式计算
1. **Dask** - 分布式计算库,能透明地处理大规模数据集,兼容NumPy、Pandas和Scikit-learn。
2. **Apache Spark with PySpark** - 分布式计算框架,用于处理大规模数据集,支持SQL查询、流处理和机器学习。
3. **Modin** - 提供了一个与Pandas API兼容的并行数据处理层。
数据科学工作流与自动化
1. **Jupyter Notebook/Lab** - 交互式开发环境,方便编写代码、文档和可视化。
2. **IPython** - 交互式Python shell,是Jupyter的基础。
3. **nbconvert** - 将Jupyter Notebook转换为其他格式(如HTML、PDF)的工具。
4. **Snakemake** / **Luigi** - 工作流管理系统,用于自动化数据处理流程。
5. **Airflow** - 用于调度、监控和管理批处理作业的工作流管理系统。
其他相关工具
1. **joblib** - 用于并行计算和内存缓存的小型实用库。
2. **sckit-image** - 图像处理库,适用于图像预处理和计算机视觉任务。
3. **gensim** / **spacy** - 文本处理和自然语言处理库。
4. **networkx** - 社交网络分析和图论研究的库。
5. **hyperopt** / **Optuna** - 超参数优化库,用于机器学习模型调优。
随着数据科学的发展,上述列表可能会有新的工具加入,因此建议定期查阅最新资料以了解最新的库和发展趋势。