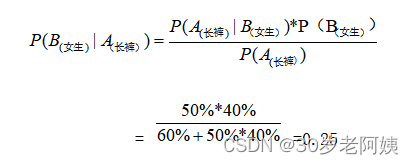统计学习方法笔记(三):朴素贝叶斯法
0.补充知识
1)贝叶斯公式
设事件
A 1 , A 2 , . . . , A n A_1,A_2,...,A_n A1,A2,...,An
为样本空间Omega中的一个划分,则在任意事件B发生的条件下,事件Ai发生的概率为
P ( A i ∣ B ) = P ( B ∣ A i ) P ( A i ) ∑ j n P ( B ∣ A j ) P ( A j ) A 1 ∪ A 2 ∪ . . . ∪ A n = Ω P(A_i|B)=\frac{P(B|A_i)P(A_i)}{\sum_{j}^nP(B|A_j)P(A_j)}\\ A_1 \cup A_2 \cup ...\cup A_n =\Omega P(Ai∣B)=∑jnP(B∣Aj)P(Aj)P(B∣Ai)P(Ai)A1∪A2∪...∪An=Ω
其中分母部分为事件B的全概率公式
2)极大似然估计法
极大似然估计是一种对给定数据代表的概率密度表达式的参数进行估计的方法,一般执行步骤为:
写出似然函数(有时还需要写出对数似然函数),以及非零区域对应的各个量的范围
L ( θ 1 , θ 2 , . . . , θ k ; x ^ ) , θ i ∈ D i L(\theta_1,\theta_2,...,\theta_k;\hat{x}),\theta_i \in D_i L(θ1,θ2,...,θk;x^),θi∈Di写出似然方程(有时是对数似然方程)
∂ L ∂ θ i = 0 \frac{\partial{L}}{\partial{\theta_i}}=0\\ ∂θi∂L=0解(对数)似然方程
经微分法检验,小写改为大写,加帽子
广义上,一般有这样的表示
θ M L E = a r g max θ P ( X ∣ θ ) \theta_{MLE}=arg\max_{\theta}P(X|\theta) θMLE=argθmaxP(X∣θ)
应用举例:
例1 求正态总体
N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2)
的未知参数
μ , σ 2 \mu,\sigma^2 μ,σ2
的极大似然估计MLE.
解
**1.**写出似然函数
L ( μ , σ 2 ) = ( 2 π σ 2 ) e − 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 − ∞ < μ < ∞ , σ > 0 L(\mu,\sigma^2)=(2\pi\sigma^2)e^{-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2} \\ -\infin <\mu<\infin,\sigma >0 L(μ,σ2)=(2πσ2)e−2σ21∑i=1n(xi−μ)2−∞<μ<∞,σ>0
注意第二行中要写出参数范围,接着写出对数似然函数
l n L ( μ , σ 2 ) = − n 2 l n ( 2 π ) − n 2 l n ( σ 2 ) − 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 lnL(\mu,\sigma^2)=-\frac{n}{2}ln(2\pi)-\frac{n}{2}ln(\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2 lnL(μ,σ2)=−2nln(2π)−2nln(σ2)−2σ21i=1∑n(xi−μ)2
**2.**参数的范围与样本无关,考虑用微分法,进而对参数求偏导构造对数似然方程
{ ∂ [ l n L ( μ , σ 2 ) ] ∂ μ = 1 σ 2 ∑ i = 1 n ( x i − μ ) = 0 ∂ [ l n L ( μ , σ 2 ) ] ∂ σ 2 = − n 2 σ 2 + 1 2 σ 4 ∑ i = 1 n ( x i − μ ) = 0 \begin{cases} \frac{\partial[lnL(\mu,\sigma^2)]}{\partial{\mu}}= \frac{1}{\sigma^2}\sum_{i=1}^n(x_i-\mu)=0\\ \frac{\partial[lnL(\mu,\sigma^2)]}{\partial{\sigma^2}}= -\frac{n}{2\sigma^2}+ \frac{1}{2\sigma^4}\sum_{i=1}^n(x_i-\mu)=0 \end{cases} { ∂μ∂[lnL(μ,σ2)]=σ21∑i=1n(xi−μ)=0∂σ2∂[lnL(μ,σ2)]=−2σ2n+2σ41∑i=1n(xi−μ)=0
**3.**解方程得到
{ μ ^ = 1 n ∑ i = 1 n x i = x ˉ σ 2 ^ = 1 n ∑ i = 0 n ( x i − x ˉ ) 2 = s n 2 \begin{cases} \hat{\mu}=\frac{1}{n}\sum_{i=1}^nx_i=\bar{x}\\ \hat{\sigma^2}=\frac{1}{n}\sum_{i=0}^n(x_i-\bar{x})^2=s_n^2 \end{cases} { μ^=n1∑i=1nxi=xˉσ2^=n1∑i=0n(xi−xˉ)2=sn2
1.概述
对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合
概率分布;然后基于此模型,对给定的输入 x ,利用贝叶斯定理求出后验概率最大的输出 y
为方便描述,进行以下设定:
设训练数据集为
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}
输入为特征向量x,输出为类标记ci,满足以下关系
x ∈ χ ⊆ R n , Γ = { c 1 , c 2 , . . . , c K } i = 1 , 2 , . . . , K x \in \chi \subseteq R^n, \Gamma=\{c_1,c_2,...,c_K\} \\ i = 1,2,...,K x∈χ⊆Rn,Γ={ c1,c2,...,cK}i=1,2,...,K
斜体X:输入空间
大写伽马:输出空间
X:定义在输入空间上的随机向量
Y:定义在输出空间上的随机向量
那么P(X,Y)则表示X和Y的联合概率分布,且数据集T由独立同分布的P(X,Y)产生
2.朴素贝叶斯模型
1)一些概率分布
先验概率:
P ( Y = c i ) , i = 1 , 2 , . . . , K P(Y=c_i), \ i=1,2,...,K P(Y=ci), i=1,2,...,K
条件概率分布:
P ( X = x ∣ Y = c i ) = P ( X ( 1 ) = x ( 1 ) , . . . , X ( n ) = x ( n ) ∣ Y = c i ) i = 1 , 2 , . . . , K P(X=x|Y=c_i)=P(X^{(1)}=x^{(1)},...,X^{(n)}=x^{(n)}|Y=c_i)\\ i=1,2,...,K P(X=x∣Y=ci)=P(X(1)=x(1),...,X(n)=x(n)∣Y=ci)i=1,2,...,K
在朴素贝叶斯法下,假设了X的每个分量是独立的,因此有
P ( X ( 1 ) = x ( 1 ) , . . . , X ( n ) = x ( n ) ∣ Y = c i ) = Π j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c i ) P(X^{(1)}=x^{(1)},...,X^{(n)}=x^{(n)}|Y=c_i)\\ =\Pi_{j=1}^nP(X^{(j)}=x^{(j)}|Y=c_i) P(X(1)=x(1),...,X(n)=x(n)∣Y=ci)=Πj=1nP(X(j)=x(j)∣Y=ci)
后验概率分布:
由贝叶斯公式,可得后验概率的表达式为
P ( Y = c i ∣ X = x ) = P ( X = x ∣ Y = c i ) P ( Y = c i ) ∑ i P ( X = x ∣ Y = c i ) P ( Y = c i ) = P ( Y = c i ) Π j P ( X ( j ) = x ( j ) ∣ Y = c i ) ∑ i P ( Y = c i ) Π j P ( X ( j ) = x ( j ) ∣ Y = c i ) P(Y=c_i|X=x)=\frac{P(X=x|Y=c_i)P(Y=c_i)}{\sum_iP(X=x|Y=c_i)P(Y=c_i)}\\ = \frac {P(Y=c_i)\Pi_jP(X^{(j)}=x^{(j)}|Y=c_i)} {\sum_iP(Y=c_i)\Pi_jP(X^{(j)}=x^{(j)}|Y=c_i)} P(Y=ci∣X=x)=∑iP(X=x∣Y=ci)P(Y=ci)P(X=x∣Y=ci)P(Y=ci)=∑iP(Y=ci)ΠjP(X(j)=x(j)∣Y=ci)P(Y=ci)ΠjP(X(j)=x(j)∣Y=ci)
2)朴素贝叶斯分类器
表达式:
y = f ( x ) = a r g max c i P ( Y = c i ) Π j P ( X ( j ) = x ( j ) ∣ Y = c i ) ∑ i P ( Y = c i ) Π j P ( X ( j ) = x ( j ) ∣ Y = c i ) y=f(x)=arg \max_{c_i}\frac {P(Y=c_i)\Pi_jP(X^{(j)}=x^{(j)}|Y=c_i)} {\sum_iP(Y=c_i)\Pi_jP(X^{(j)}=x^{(j)}|Y=c_i)} y=f(x)=argcimax∑iP(Y=ci)ΠjP(X(j)=x(j)∣Y=ci)P(Y=ci)ΠjP(X(j)=x(j)∣Y=ci)
由于上式中分母对所有ci都是相同的,则表达式可简化为
y = a r g max c i P ( Y = c i ) Π j P ( X ( j ) = x ( j ) ∣ Y = c i ) y=arg \max_{c_i} {P(Y=c_i)\Pi_jP(X^{(j)}=x^{(j)}|Y=c_i)} y=argcimaxP(Y=ci)ΠjP(X(j)=x(j)∣Y=ci)
使用argmax的原因(后验概率最大化的原因):
假设选择的损失函数为0-1损失函数(f(X)为分类决策函数)
L ( Y , f ( X ) ) = { 1 , Y ≠ f ( X ) 0 , Y = f ( X ) L(Y,f(X))=\begin{cases} 1, & Y \neq f(X) \\ 0, & Y = f(X) \end{cases} L(Y,f(X))={ 1,0,Y=f(X)Y=f(X)
则使得损失函数的期望风险最小化的过程就是对X=x逐个极小化, 推导过程表示如下:
f ( x ) = a r g min y ∈ Γ ∑ k = 1 K L ( c k , y ) P ( c k ∣ X = x ) = a r g min y ∈ Γ ∑ k = 1 K P ( y ≠ c k ∣ X = x ) = a r g min y ∈ Γ ( 1 − P ( y = c k ∣ X = x ) ) = a r g max y ∈ Γ P ( y = c k ∣ X = x ) f(x)=arg \min_{y \in \Gamma} \sum_{k=1}^KL(c_k,y)P(c_k|X=x) \\ =arg \min_{y \in \Gamma}\sum_{k=1}^KP(y \neq c_k|X=x)\\ =arg \min_{y \in \Gamma}(1-P(y=c_k|X=x))\\ =arg \max_{y \in \Gamma}P(y=c_k|X=x) f(x)=argy∈Γmink=1∑KL(ck,y)P(ck∣X=x)=argy∈Γmink=1∑KP(y=ck∣X=x)=argy∈Γmin(1−P(y=ck∣X=x))=argy∈ΓmaxP(y=ck∣X=x)
3.学习过程
朴素贝叶斯法的学习过程为对先验概率和条件概率的估计,估计值为极大似然估计得到的值
1)先验概率的极大似然估计
表达式:
P ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) N , k = 1 , 2 , . . . , K P(Y=c_k)=\frac{\sum_{i=1}^NI(y_i = c_k)}{N}, k=1,2,...,K P(Y=ck)=N∑i=1NI(yi=ck),k=1,2,...,K
简单推导过程:
假设
P ( Y = c k ) = p , P ( Y ≠ c k ) = 1 − p P(Y=c_k)=p,P(Y\neq c_k)=1-p P(Y=ck)=p,P(Y=ck)=1−p
由独立性,连续抽样N次条件抽出M次P(Y=ck)下,则有似然函数
L ( p ) = P ( Y ) = C N M p M ( 1 − p ) N − M L(p)=P(Y)=C_N^Mp^M(1-p)^{N-M} L(p)=P(Y)=CNMpM(1−p)N−M
取对数得
l n L ( p ) = l n ( C N M ) + M l n ( p ) + ( N − M ) l n ( 1 − p ) lnL(p)=ln(C_N^M)+Mln(p)+(N-M)ln(1-p) lnL(p)=ln(CNM)+Mln(p)+(N−M)ln(1−p)
对p求导得
d l n L ( p ) d p = M p − N − M 1 − p {dlnL(p) \over dp}=\frac{M}{p}-\frac{N-M}{1-p} dpdlnL(p)=pM−1−pN−M
令导数为0,解得
p = M N p={M \over N} p=NM
记
M = ∑ i = 1 N I ( y i = c k ) M=\sum_{i=1}^NI(y_i=c_k) M=i=1∑NI(yi=ck)
可得
p = P ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) N p=P(Y=c_k)=\frac{\sum_{i=1}^NI(y_i = c_k)}{N} p=P(Y=ck)=N∑i=1NI(yi=ck)
2)条件概率的极大似然估计
设第j个特征可能取值集合为
{ a j 1 , a j 2 , . . . , a j S j } \{a_{j1},a_{j2},...,a_{jS_j}\} { aj1,aj2,...,ajSj}
表达式:
P ( X ( j ) = a j l ∣ Y = c k ) = ∑ i = 1 N I ( x i ( j ) = a j l , y i = c k ) ∑ i = 1 N I ( y i = c k ) j = 1 , 2 , . . . , n ; l = 1 , 2 , . . . , S j ; k = 1 , 2 , . . . , K P(X^{(j)}=a_{jl}|Y=c_k)={\sum_{i=1}^NI(x_i^{(j)}=a_{jl},y_i=c_k) \over \sum_{i=1}^NI(y_i=c_k)}\\ j=1,2,...,n;l=1,2,...,S_j;k=1,2,...,K P(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)∑i=1NI(xi(j)=ajl,yi=ck)j=1,2,...,n;l=1,2,...,Sj;k=1,2,...,K
推导过程:与先验概率的极大似然估计推导过程类似
严谨的推导过程感兴趣可前往知乎探索
4.算法