论文标题:Inner Monologue: Embodied Reasoning through Planning with Language Models
论文作者:Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, Brian Ichter
作者单位:Robotics at Google
论文原文:https://arxiv.org/abs/2207.05608
论文出处:–
论文被引:343(01/05/2023)
项目主页:https://innermonologue.github.io/
Abstract
最近的研究表明,大型语言模型(LLM)的推理能力可以应用于自然语言处理以外的领域,如机器人的规划和交互。这些具身的问题(embodied problems)要求Agent了解世界的许多语义方面:可用技能库,这些技能如何影响世界,以及世界的变化如何映射到语言。在具身环境中进行规划的 LLM 不仅需要考虑使用哪些技能,还需要考虑如何使用以及何时使用这些技能——这些答案会随着时间的推移而变化,以响应Agent自身的选择。在这项工作中,我们研究了在这种具身环境中使用的 LLM 在多大程度上可以在没有任何额外训练的情况下,对通过自然语言提供的反馈源进行推理。我们认为,通过利用环境反馈,LLMs 能够形成内心独白,从而在机器人控制场景中进行更丰富的处理和规划。我们研究了各种反馈来源,如成功检测,场景描述和人机交互。我们发现,闭环语言反馈能显著改善三个领域的高层次指令完成情况,包括模拟和真实的桌面重新排列任务,以及真实世界厨房环境中的长距离移动操作任务。
1 Introduction
智能而灵活的具身交互(embodied interaction)要求机器人能够以适当的方式部署大量基本行为,根据长期任务的需要对这些行为进行排序,并在特定行为或规划不成功时识别何时切换到另一种方法。高层次规划(high-level planning),感知反馈(perceptual feedback)和低层次控制(low-level control)只是需要无缝结合在一起的几个子任务,要完成机器人等具身Agent在世界上智能行动所需的推理,这些子任务是必不可少的。虽然这些挑战通常都是从规划(如 TAMP [1])或分层学习(如 HRL [2])的角度来解决的,但对复杂任务进行有效的高层次推理还需要语义知识和对世界的理解。
最近的机器学习研究中一个引人注目的现象是,大型语言模型(LLMs)不仅可以生成流畅的文本描述,而且似乎还拥有丰富的关于世界的内化知识(internalized knowledge)[3, 4, 5, 6, 7]。在适当的条件下(如提示),它们甚至可以进行一定程度的推理,并回答似乎需要推理和推论的问题[8, 9, 10, 11, 12, 13]。这就提出了一个引人入胜的可能性:除了解释自然语言指令的能力之外,语言模型是否还能进一步充当推理模型,结合多种反馈来源,成为机器人操作等具身任务的交互式问题解决者?
先前的研究表明,语言有助于人类将知识内化,并通过语言思维进行复杂的关系推理[14, 15, 16, 17, 18]。想象一下当一个人试图解决某些任务时的 内心独白:“我必须打开这扇门;让我试着拿起钥匙把它插进锁里…不,等等,它插不进去,我再试试另一把…那把起作用了,现在我可以转动钥匙了”。在这种情况下,思维过程包括选择解决高层次任务的最佳即时行动(“拿起钥匙”),观察尝试行动的结果(“不合适”)以及根据这些观察结果采取纠正行动(“我再试一把”)。受人类思维过程的启发,我们认为这种内心独白是将反馈纳入 LLM 的自然框架。
我们的工作通过将 LLM 与各种文本反馈来源相结合来研究这些问题,只使用了少量的提示,而没有进行任何额外的训练。我们注意到,与最近的工作[19]类似,自然语言为模型交流的这种基础提供了一个通用和可解释的界面,并允许它们将其结论纳入由语言模型驱动的总体内心独白中。虽然之前的工作已经研究了使用语言模型作为规划器[20, 21],或通过语言纳入多模态感知[19],但就我们所知,还没有工作研究过不仅用语言规划,同时也用语言传达具身反馈,我们在这项工作中研究了这一点。
具体来说,我们研究了通过内心独白实现Agent-环境闭环的反馈方法和来源,以及这些方法和来源对下游执行成功率和这种互动产生的新能力的影响。特别是,我们将执行各种任务(如语言条件语义分类或基于语言的场景描述)的多个感知模型与机器人合作的人类用户提供的反馈结合起来。为了执行用户下达的指令,我们从一组预先训练好的机器人操作技能中选择动作,并附上可由语言模型调用的文字描述。我们提出的 内心独白 系统将这些不同的组件(感知模型,机器人技能和人类反馈)整合在一个共享的语言提示中,使其能够成功执行用户指令。
最后,我们展示了 内心独白,除了冻结的语言模型和预先训练的机器人技能外,它不需要额外的训练,就能在模拟中以及在两个真实世界的机器人平台上完成复杂,长视距和未知的任务。值得注意的是,我们展示了它能在观察到的随机失败情况下有效地重试,在系统不可行的情况下重新扫描,或在模糊查询时请求人类反馈,从而显著提高了动态环境中的性能。为了展示 LLM 和基础闭环反馈的多功能性,我们还展示了内心独白表述中出现的几种令人惊讶的功能,包括持续适应新指令,自拟目标,交互式场景理解,多语言交互等。
2 Related Work
Task and Motion Planning.
任务和运动规划(Task and Motion Planning,TaMP) [22, 23] 需要同时解决高层次离散任务规划问题 [24, 25, 26] 和低层次连续运动规划问题 [27]。传统上,这一问题是通过优化 [28, 29] 或符号推理 [24, 26] 来解决的,但最近,机器学习已通过学习表征,学习任务原型(learned task-primitives)等方式被应用于该问题的各个方面 [30, 31, 32, 33, 34, 35, 36, 37, 38]。一些研究利用语言进行规划和grounding [39, 40, 41, 42, 43, 44]。其他研究则通过分层学习(hierarchical learning)来解决这一问题 [45,46,34,47,48,49,50]。在这项工作中,我们利用预先训练好的 LLM 及其语义知识,再加上训练好的低层次技能(low-level skills),来找到可行的规划。
Task Planning with Language Models.
之前有许多研究都探索过将语言作为规划空间[51, 52, 20, 53, 21, 19]。与我们类似的是最近的任务规划方法,它们利用预训练的自回归 LLM 将抽象的高层次指令分解为一系列可由Agent执行的低层次步骤[20, 21]。具体地说,
- Huang 等人[20] 利用 GPT-3[9] 和 Codex[54] 为具身Agent生成行动规划,其中每个行动步骤都通过Sentence-RoBERTa模型[55, 56]在语义上翻译为可接受的行动。
- SayCan [21] 则是通过将每个候选行动在 FLAN [57] 下的概率与该行动的值函数相乘来确定行动的依据,而值函数则是负担能力(affordance)[34]的代表。
这两种方法都能有效地生成规划,同时假设每个步骤都能被Agent成功执行。因此,这些方法在处理动态环境中的中间故障或较差的底层策略时可能不够稳健。我们在内心独白中探索了如何在生成规划中的每一步时,将来自环境的基础反馈纳入 LLM。
Fusing Vision, Language, and Control in Robotics.
针对融合视觉,语言和控制这一具有挑战性的问题,已有多项研究成果对相关策略进行了探讨[58, 59, 60, 61, 62, 63, 64]。预训练的 LLM 通常只在文本数据上进行训练,而预训练的视觉语言模型(如 CLIP [65])则通过掩码语言建模(MLM)目标[66, 67, 68, 69],对比损失[70, 71, 65]或其他监督目标[72, 73]的变体,在联合图像和相应的文本标题上进行训练。
- CLIP 已被用于多个机器人和具身环境中,如零样本方式[74],或与 Transporter 网络[75]相结合,如 CLIPort [76]。
- Socratic 模型[19] 结合了多个基础模型(如 GPT-3 [9],ViLD [77])和语言条件策略,使用语言作为通用接口(common interface),并演示了在基于视觉的模拟机器人操作环境中操作物体。
3 Leveraging Embodied Language Feedback with Inner Monologue
在本节中,我们将介绍llm如何充当交互式问题求解器(problem solvers),并通过我们称之为内心独白(Inner Monologue)的过程将具身的环境观察纳入可执行的规划(grounded planning)。
3.1 Problem Statement
这个机器人Agent只能从以前训练过的策略库 π k ∈ ∏ π_k \in \prod πk∈∏ 中执行短视距技能(short-horizon skills),这些策略带有简短的语言描述 l k \mathscr{l}_k lk,可以通过强化学习或行为克隆来训练。规划器是经过预训练的 LLM [20, 21],它试图找到完成指令的技能序列。为了观察环境,规划器可以从环境中获取文本反馈o,这些反馈可以附加到指令中,也可以由规划器提出要求。观察o可以是成功检测,物体检测,场景描述,视觉问答,甚至是人类反馈。我们的工作是研究 LLM 规划器在多大程度上能够推理和利用这些反馈,从而与环境形成 “闭环” 并改进规划。
3.2 Inner Monologue

在机器人与环境交互的过程中,我们不断将各种反馈来源的信息注入 LLM 的规划语言提示中,从而形成 内心独白。虽然 LLM 已证明其具有出色的规划能力,可用于具身控制任务[20],但之前的研究发现,LLM 预测必须以外部组件为基础,如负担能力(affordance)[21],才能产生机器人可执行的有用规划。然而,迄今为止,在这种情况下使用的 LLM 仍然是单向的,即提供一个技能列表,而不进行相应的修正或利用机会重新规划。相比之下,内心独白所研究的是以闭环方式直接向 LLM 提供基础环境反馈的环境。这有助于提高 LLM 在复杂的长视距环境中的推理能力,甚至在应用任何基于外部负担能力的可执行的方法之前就能做到这一点。
我们的分析假定向规划器提供了文本反馈,但并不假定将 LLM 规划与低层次机器人控制相融合的单一特定方法,也不假定将环境反馈提取为语言的特定方法。我们的目标不是关注特定的算法实现,而是提供一个案例研究,说明将不同类型的反馈纳入基于 LLM 的闭环规划的价值。因此,第 4 节中的内心独白在不同的系统中使用了语言反馈,这些系统包含不同的 LLM,不同的规划与控制融合方法,不同的环境和任务以及不同的控制策略获取方法。在内心独白的具体实现中,我们使用预先训练好的 LLMs 进行规划,这些 LLMs 并未经过微调,而是仅通过少量提示进行评估;完整的提示可在附录中找到。
3.3 Sources of Feedback
理论上,任何类型的环境反馈都可以为 LLM 规划器提供信息,只要这些反馈可以通过语言表达出来。我们将重点放在图 2 所示的具体反馈形式上,这些反馈可细分为特定任务反馈(如成功检测),以及描述了场景的特定场景反馈(“被动” 或 “主动”)。每种反馈类型的具体实例和实现细节详见第 4.1,4.2 和 4.3 节。

Success Detection.
语义成功检测(Semantic success detection)是一个关于低层次技能 π k π_k πk 是否成功的二分类问题。工程成功检测器(Engineered success detectors)可以在模拟的 ground-truth state 上运行,而学习成功检测器则可以在现实世界中成功和失败的真实例子上进行训练[78, 79, 80, 81, 82]。我们使用语言形式的成功检测器输出,我们称之为成功反馈。
Passive Scene Description.
虽然描述场景语义的方法有很多,但我们使用被动场景描述(Passive Scene Description)来广泛描述持续提供并遵循某种结构的场景反馈源。被动场景描述包括所有自动提供并注入 LLM 提示的环境可执行的(grounding)反馈源,而无需 LLM 规划器进行任何主动提示或查询。此类反馈的常见类型之一是物体识别 [83, 84, 85, 86]——我们将此类物体识别器的文本输出称为物体反馈。我们还演示了在模拟桌面重排(rearrangement)环境中使用任务进程场景描述的情况,我们将其称为场景反馈。
Active Scene Description.
作为与被动场景描述相对应的主动场景描述,主动场景描述包括直接响应 LLM 规划器主动查询而提供的反馈源。在这种情况下,LLM 可以直接提出一个关于场景的问题,而这个问题可以由人回答,也可以由另一个经过预训练的模型回答,例如 VQA 模型 [87,88,89,90]。前几种类型的反馈都是严格结构化的,范围较窄,而在主动场景描述设置中,LLM 可以接收开放式问题的非结构化答案,从而主动收集与场景,任务甚至用户偏好相关的信息(在由人工提供答案的情况下)。我们发送给 LLM 规划器的综合输出包括 LLM 生成的问题和回答。由于我们的目标是研究 LLM 规划器是否以及如何纳入此类反馈,并希望同时研究结构化 VQA 风格的人类反馈和非结构化的人类偏好反馈,因此我们在本工作中只考虑人类提供的回复,我们将其称为人类反馈。
4 Experimental Results
为了研究不同来源的环境反馈如何支持丰富的内心独白,从而实现复杂的机器人控制,我们分析了模拟和现实世界中的各种长视距操作和导航任务。由于内心独白不依赖于特定的 LLM 或可执行的反馈类型,因此我们在三种环境中研究了不同的内心独白实现方法,并采用了不同的 LLM 规划方法和不同的环境反馈来源。下面,我们将展示模拟(第 4.1 节)和真实(第 4.2 节)桌面操作环境以及真实(第 4.3 节)移动操作环境的结果。有关实验设置和结果的详细信息,请参阅附录。
4.1 Simulated Tabletop Rearrangement
我们在基于 Ravens 的模拟环境[75]中进行了基于视觉的积木操作任务实验,以评估我们的方法与几种基线方法的对比情况,并对不同数量的文本反馈进行消融。给定桌子上的一些积木和碗,包含抓手的机械臂的任务是按照自然语言指定的某种所需配置(例如,将积木放入颜色匹配的碗中)重新排列这些物体。我们在四个可见任务和四个未见任务上对每种方法进行评估,其中可见任务可用于训练(在有监督基线的情况下),也可用作 LLM 规划器的少量提示。
这个内心独白实例使用:
- (i) InstructGPT [9, 91] 作为多步骤规划的 LLM [20, 21]
- [(ii) 脚本模块以物体识别(Object),成功检测(Success)和任务或压力场景描述(Scene)的形式提供语言反馈
- (iii) 预训练的语言条件取放基元(类似于 CLIPort [76] 和 Transporter Nets [75])。
物体反馈会告知 LLM 规划器场景中存在的物体,在这种环境下,仅使用物体反馈的变体与 [19] 中演示的示例类似。成功反馈会告知规划器最近一次行动的成功/失败。然而,在存在许多物体和测试时间干扰的情况下,复杂的组合状态空间要求规划器对整体任务进度进行额外推理(例如,如果目标是堆叠多个积木,未完成的积木塔可能会被机器人撞倒)。因此,任务进度场景描述(Scene)描述了 LLM 为完成高层指令而推断出的语义子目标,这些子目标目前已由Agent完成。对于使用 “物体+场景” 反馈的变体,由于推理复杂度增加,我们发现添加思维链[10, 12, 13]可以提高推断目标与实现目标之间的一致性。
此外,我们还将 CLIPort 策略与直接根据长视距任务指令(即不使用 LLM 进行规划)训练的多任务 CLIPort 策略进行了比较。由于 CLIPort 是一种单步策略,不会在策略推出过程中自发终止,因此我们在报告 CLIPort 评估结果时,同时采用了Oracle终止(即重复直到Oracle指示任务完成)和固定步终止(即重复 k 步)。虽然 Inner Monologue 会在 LLM 停止生成新步骤时终止,但出于实际考虑,我们同样将最大步骤数设为 k。我们使用 k =15。为了模拟现实世界中的干扰并评估系统对干扰的鲁棒性,我们在测试时向系统的多个层级添加高斯噪声:N (0,3)用于像素观测,N (0,2.5)用于策略基元(即选取位置像素热图),N (0,0.02m)用于位置定位。

结果如表1所示,示例提示可以在图3中找到。
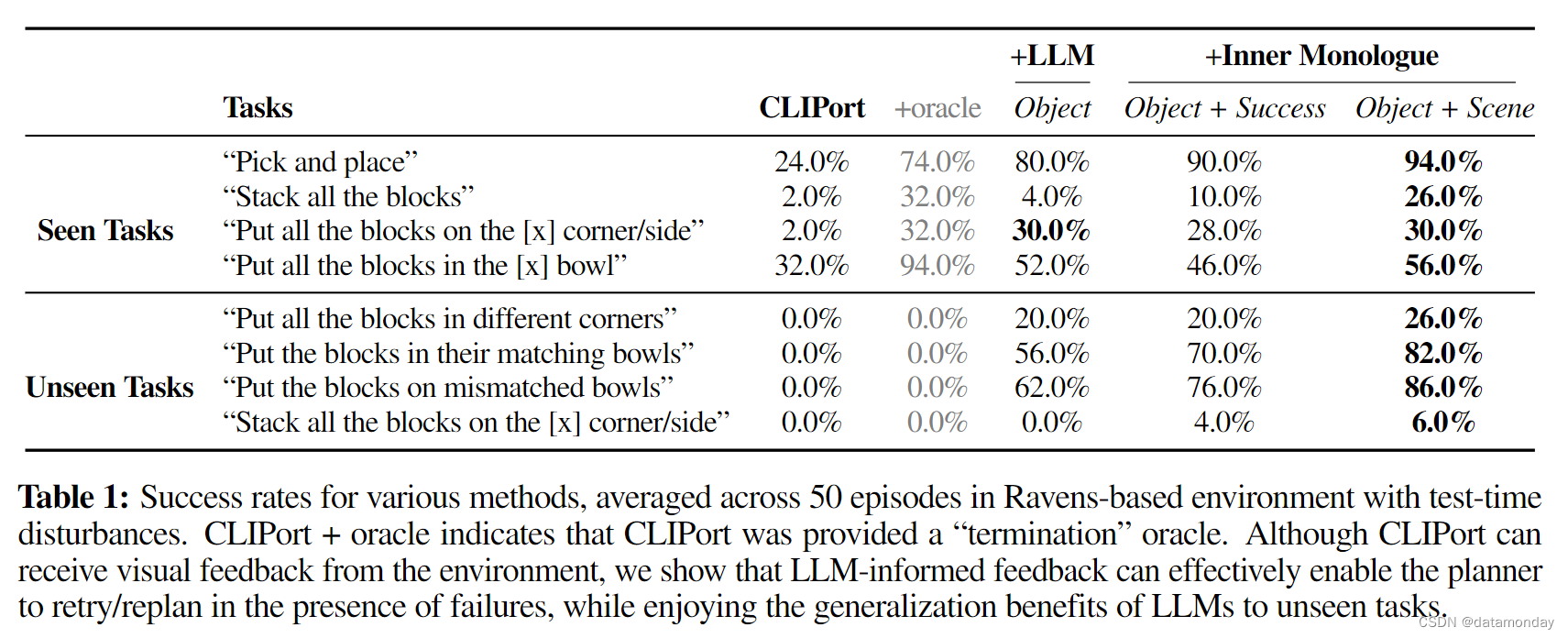
Analysis.
如表 1 所示,内心独白的所有变体都在可见任务中表现出色,而且通过利用预先训练的 LLM 中丰富的语义知识,其表现可以直接转换到未可见任务中,而无需进一步训练。此外,与我们的假设一致,带有 “物体+场景” 的内心独白表现最佳,因为它能够跟踪所有目标条件和当前已实现的目标。最后,我们观察到,像 CLIPort 这样的非层级式孤岛系统(i)在测试时间干扰下很难泛化到未见的长视距任务中,(ii)在训练任务中,为了获得良好的性能,通常还需要一个 oracle 来指示任务完成情况。
4.2 Real-World Tabletop Rearrangement
我们在真实世界的机器人平台上对 Inner Monologue 进行了评估,该平台的设计类似于第 4.1 节中介绍的模拟实验,使用了桌面取放的运动基元。实验装置包括一个 UR5e 机械臂,该机械臂配备了一个安装在手腕上的英特尔 RealSense RGB-D 摄像头,可以俯瞰一个由各种物体组成的工作区——从玩具积木到食品,再到调味品(如图 3 所示)。我们使用 Inner Monologue 的一个实例:
- (i) InstructGPT [9, 91] 作为多步骤规划的 LLM;
- (ii) 使用 MDETR [92] 进行预训练的开放词汇物体识别,生成当前可见物体列表和之前可见但现在不再可见的物体列表(物体);
- (iii) 使用 MDETR 的物体边界框预测启发式方法进行成功检测(成功);
- (iv) 零样本拾取和放置策略,其使用LLM从语言命令(例如由规划器给出)解析目标对象,然后在目标物体的边界框的中心执行基于脚本的拾取和放置基元。除了 LLM 和 MDETR 的预训练(开箱即用)外,该系统不需要对模型进行任何微调,即可执行新物体的拾取和放置任务。
我们研究了两个任务:
- (i) 一个简单的 3 块堆叠任务,其中 2 块已预先堆叠好;
- (ii) 一个更复杂的长视距分类任务,即把食物放在一个盘子里,把调味品放在另一个盘子里(其中食物与调味品的分类由 LLM 规划器自主完成)。
由于系统的默认取放性能通常很高,我们人为地在策略操作中注入了高斯噪声(即添加标准偏差 σ=4mm,clipped at 2σ),以压力测试通过可执行的闭环反馈重新规划从故障中恢复的能力。结果见表 2。需要注意的是,由于现实世界的感知和杂波带来的额外挑战,该系统在检测物体和成功率时也会出现噪声。

Analysis.
我们比较了内心独白的不同变体与不同的 LLM 闭环反馈,以及仅在任务开始时运行一次物体识别的开环变体(类似于 [19] 中演示的系统)。部分 3 块堆叠任务凸显了这一基线的直接失败模式,即初始场景描述难以捕捉到完整的场景表示(由于杂乱和遮挡),无法作为多步骤规划器的输入。因此,系统只能执行一次取放操作,无法从错误中恢复。为了解决这些缺陷,Inner Monologue(物体+成功)利用闭环场景描述和每一步后的成功检测,使其能够成功地重新规划并从策略错误中恢复。
使用 Inner Monologue 进行的其他消融还表明:
- (i) 缺乏闭环场景描述所导致的常见失败主要是:由于最初被遮挡的物体不在 LLM 生成的规划中;
- (ii) 由于缺乏成功检测而导致的失败来自于:没有重试由于策略噪声而失败的拾取和放置操作。
总之,我们发现这两个部分在为实际重新排列任务保持稳健的恢复模式方面具有互补性和重要性。
4.3 Real-World Mobile Manipulator in a Kitchen Setting
我们利用 SayCan [21] 中描述的厨房环境和任务定义,在机器人系统中实现了 内心独白。Everyday Robots 机器人是一个具有 RGB 观察功能的移动机械手,它被放置在一个办公室厨房中,利用并发[93]连续闭环控制与常见物体进行交互。
基准方法 SayCan [21] 是一种通过将 LLM 与底层控制策略的值函数相结合,在现实世界的各种场景中进行规划和行动的方法。SayCan 根据值函数的承受能力制定规划,但 LLM 预测从未获得任何闭环反馈。
我们使用了内心独白的一个实例,该实例使用:
- (i) PaLM [8] 作为多步骤规划的 LLM;
- (ii) 来自预训练控制策略的值函数,用于负担能力基础[21];
- (iii) 学习的视觉分类模型,用于成功检测反馈(Success);
- (iv) 人类提供的物体识别反馈(Object);
- (v) 预训练控制策略,用于场景中的相关技能。
我们还进行了一项案例研究,允许Agent直接提问并获得人类反馈;结果见图 5a 和附录。

我们对三个任务系列的 120 项评估方法进行了评估:
- 1)4 项操作任务;
- 2)2 项利用抽屉的灵巧操作任务;
- 3)2 项长视野操作和导航组合任务。
为了更好地研究内心独白如何在特别具有挑战性的场景中提高推理能力,我们考虑了一种实验变体,即在控制策略执行过程中添加对抗性干扰,导致技能策略推出失败。这些干扰可能相当简单,只需要策略重新尝试,也可能足够复杂,以至于策略需要重新扫描并选择全新的技能。虽然即使没有扰动,这些失败也会自然发生,但对抗性扰动会造成方法之间的一致性比较,需要重试或重新规划才能完成原始指令。
Analysis.

真实机器人实验结果如表 3 所示。在没有对抗性干扰的情况下,基线方法 SayCan 在所有三个任务系列中的表现都还算不错,但是,结合 LLM 对技能成功/失败和物体存在的反馈,内心独白可以在自然失败的情况下有效地重试或重新规划,从而进一步改进基线方法。最显著的区别在于,在有对抗性干扰的情况下,策略会被迫失效。在没有任何 LLM 信息反馈的情况下,SayCan 的成功率接近 0%,因为它没有明确的高层次重试行为。由于 Inner Monologue 能够根据环境反馈调用适当的恢复模式,因此其性能明显优于 SayCan。对失败原因的深入分析表明,Successand Object 反馈可以有效减少 LLM 规划失败,从而降低总体失败率,但代价是为系统引入新的失败模式。
4.4 Emergent Capabilities
虽然 LLM 可以从提示的例子中生成流畅的续篇,但我们意外地发现,在获得环境反馈信息后,内心独白在提示中给出的例子之外,还表现出了许多令人印象深刻的推理和重新规划行为。以预先训练的 LLM 为骨干,该方法还继承了其多功能性和通用语言理解能力的许多吸引人的特性。在本节中,我们将展示其中一些新出现的能力。
Continued Adaptation to New Instructions.
虽然没有明确提示,但 LLM 规划器可以对任务中期改变高层次目标的人机交互做出反应。图 5a 展示了一个具有挑战性的案例,即在规划执行过程中,人的反馈改变了目标,然后通过说 “finish the previous task” 再次改变了目标。我们可以看到,规划器通过两次切换任务正确地吸收了反馈信息。在另一种情况下,尽管在人类说 “请停止” 后没有明确提示终止,但 LLM 规划器仍能概括这种情况,并预测出 “完成” 操作。
Self-Proposing Goals under Infeasibility.
内心独白不会无意识地听从人类的指令,它还可以充当交互式问题求解器,在前一个目标变得不可行时提出替代目标。在图 5b 中,为了解决 “把任意两个积木放进紫色碗里” 的任务,内心独白首先尝试了拿起紫色积木的动作,但由于紫色积木对机器人来说太重,所以这个动作失败了。在得到 “紫色积木太重” 的提示后,它提出 “找一个轻一点的积木”,最终成功地完成了任务。
Multilingual Interaction.
众所周知,经过预先训练的 LLM 能够在不进行任何微调的情况下从一种语言翻译成另一种语言。我们注意到,这种多语言理解能力也适用于本研究中的具身环境。具体来说,在图 5c 中,人类提供的新指令是用中文书写的,但 LLM 可以正确地解释它,并将其重新叙述为一个用英文执行的具体目标,并相应地重新规划其未来的行动。有时,我们会发现这种能力甚至可以扩展到符号和表情符号。
Interactive Scene Understanding.
我们还观察到,内心独白以过去的动作和环境反馈为背景,展示了对场景的交互式理解。在图 5d 中,任务指令执行完毕后,我们转而提出有关场景的问题,这也是提示中没有出现过的结构。令人惊讶的是,我们发现它经常能正确回答这些需要时间推理和具身推理(embodied reasoning)的问题。
Robustness to Feedback Order.
在本文的主要实验中,我们按照一定的惯例提示语言模型。例如,在模拟桌面领域中,约定为[机器人行动,场景和机器人思考]。在实践中,我们发现 LLM 规划器对偶尔调换反馈顺序很有信心。在附图 9a 中,一条新的人类指令在规划执行过程中注入,但这种结构在示例提示中并没有出现过。然而,规划器识别到了这一变化,并生成了新的 "机器人思考:目标状态是… " 语句,使其能够解决新任务。
Robustness to Typos.
如附图 9b 所示,我们的方法继承了 LLM 骨干,对人类指令中的错别字具有很强的鲁棒性。
尽管这些新兴能力的研究结果很吸引人,但我们注意到,当提示中没有提供类似的例子时,这些能力的一致性水平参差不齐,这可能是受语言模型当前能力的限制。不过,我们相信,对这些行为的进一步研究以及解决它们的局限性都将为我们带来令人兴奋的未来发展方向。
5 Limitations
Limiting assumptions and failure modes.
在第 4.1 节和第 4.3 节中,我们假定可以通过人类观察者或脚本系统获取Oracle场景描述符,从而向 LLM 规划器提供文本描述。我们在附录表 5 中研究了学习系统场景描述和物体识别的可行性。至于失败模式,内心独白可能会因以下几种错误而失败:
- 1)成功检测
- 2)LLM 规划错误
- 3)控制错误
成功检测器的假阴性预测会导致额外的重试尝试,而假阳性预测则会增加环境的对抗性部分可观测性。在某些情况下,我们发现 LLM 规划器忽略了环境反馈,仍然提出了涉及场景中不存在的物体的策略技能。
Limitations of results and future work.
低层次控制策略的性能不仅限制了高层次指令的整体完成性能,也限制了 LLM 能够推理的任务范围:无论 LLM 的推理能力如何提高,它仍然会受到低层次控制策略所能实现的目标的瓶颈制约。未来的工作仍有几个方面。首先,随着图像/视频描述和可视化问题解答技术的进步,完全自动化的内心独白系统已经可以实现,而不需要人类作为Oracle参与其中。其次,还可以改进如何汇总可能不准确的信息来源,例如使用文本来描述反馈模块的不确定性,或为规划增加安全和道德反馈模块。
6 Conclusion
在这项工作中,我们研究了环境反馈在涉及机器人规划和交互的任务中对 LLM 的推理所起的作用。我们提出了一种通用的内心独白(Inner Monologue)表述方式,它将不同来源的环境反馈与 LLM 规划和机器人控制策略相结合。然后,我们研究了这些方法如何在模拟和真实世界中扩展到三种不同的机器人操作设置。我们发现,环境反馈大大提高了高层次指令的完成度,尤其是在具有对抗性干扰的挑战性场景中。最后,我们分析了内心独白的新兴功能,这些功能凸显了闭环语言反馈是如何在复杂的未知环境中实现重新规划的。
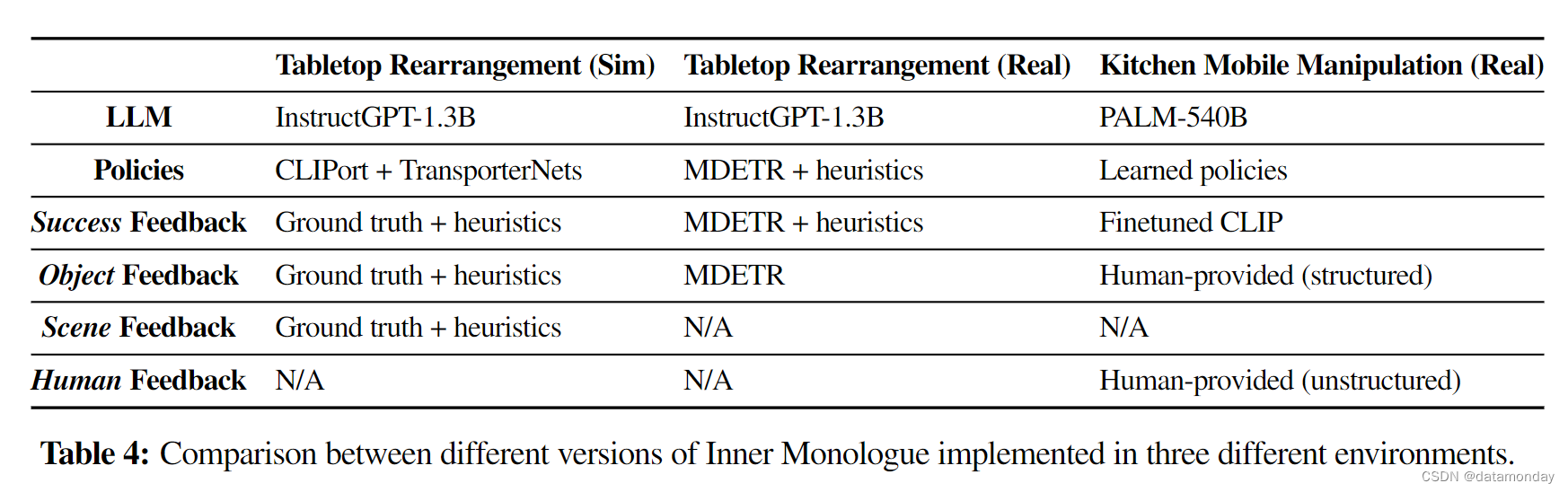
A Inner Monologue Implementation Details
我们针对每种实验设置研究了三种不同的内心独白实现方式。如表 4 所示,虽然每个版本都将文本环境反馈纳入了规划,但每个系统的内部组件都有所不同。
A.1 Inner Monologue for Simulated Tabletop Rearrangement
A.2 Inner Monologue for Real-World Tabletop Rearrangement
A.3 Inner Monologue for Real-World Mobile Manipulation in a Kitchen Setting
Large Language Model
We use PALM [8], a 540B parameter language model trained on a large datasets that include high-quality web documents, books, Wikipedia, conversations, and GitHub code.

B Experiment Details
B.1 Simulated Tabletop Rearrangement Environment
B.2 Real Tabletop Rearrangement
B.3 Real Kitchen Mobile Manipulation

C Additional Results

D Prompts

…


![[图解]SysML和<span style='color:red;'>EA</span>建模住宅安全系统-<span style='color:red;'>01</span>](https://img-blog.csdnimg.cn/direct/59826ffa10204d389f2a0ade13c2ee51.png)
![[图解]SysML和<span style='color:red;'>EA</span>建模住宅安全系统-<span style='color:red;'>02</span>](https://img-blog.csdnimg.cn/direct/f656beefe0d24490b599f3b71a9d7922.png)




















![[网鼎杯 2020 朱雀组]phpweb](https://img-blog.csdnimg.cn/direct/ae975de37fd54acf966a632a62f3c868.png)