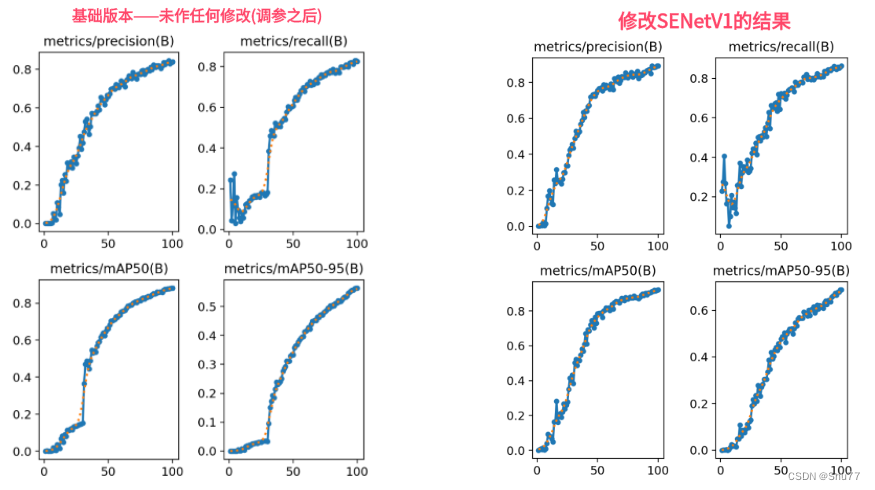
DQN的理论研究回顾
1. DQN简介
强化学习(RL)(Reinforcement learning: An introduction, 2nd, Reinforcement Learning and Optimal Control)一直是机器学习的一个重要领域,近几十年来获得了大量关注。RL 关注的是通过与环境的交互进行连续决策,从而根据当前环境制定指导行动的策略,目标是实现长期回报最大化。
Q-learning 是 RL 中最重要的学习策略之一,自它被 Watkins 1992 提出以来,就一直受到了深入的研究。 详情请参见:Bu et al (2009)。它旨在通过行动价值函数做出最优决策,该函数被定义为在给定状态下采取某种行动的预期累积奖励。传统的 Q-learning 在应用于以大尺度和连续状态空间为特征的环境时会遇到困难。 在这种情况下,管理和更新每个状态-行动对的 Q 值在计算上变得不可行。为了克服这一限制,人们开发了深度神经网络,将行动值函数表示为深度神经网络,例如 掌握围棋、机器人运动控制和自动驾驶等领域。
深度Q-learning需要通过观察数据训练神经网络,由于RL应用场景中这些数据具有很强的相关性,标准算法如随机梯度下降(SGD)往往并不稳定。Mnih et al. (2015) 的开创性工作中引入的深度Q-网络(DQN)取得了突破性进展,在玩Atari游戏时与人类专家相比表现出了卓越的性能。
除了将 Q-learning 与深度神经网络相结合,DQN 还提出了两个新颖而关键的技巧:经验重放和目标网络。这一开创性的成就推动了深度强化学习领域的进一步探索,从而发展出了Double DQN、Dueling DQN)、EBQL、Logistic Q-learning和Neural Episodic Control等方法。
尽管 DQN 的实践取得了巨大成功,但人们对其基本机制的了解仍然非常有限。
2. 文献回顾
自从Q-learning以及进一步突破的DQN被提出以来,深度Q-learning算法的相关理论分析就备受关注。
Fan et al. (2020) 重点研究了具有稀疏ReLU网络的拟合Q-迭代算法 (Munos and Szepesvári (2008),而Cai et al. (2019) 则研究了基于双层神经网络的具有i.i.d.观测模型和动作值函数逼近的Q-learning算法的全局收敛性。Xu and Gu (2020) 研究了非 i.i.d. 观测下神经 Q-learning 算法的非渐近收敛性. Du et al. (2020) 分析了确定性系统中带有函数逼近的不可知论 Q-learning 算法。更多收敛速率和探索分析的相关内容请参考Bai et al. (2019); Even-Dar et al. (2003)。
上述工作的主要局限在于缺乏对原始 DQN 算法作用的分析,尤其是对经验重放和目标网络机制的分析。
- 一些文献基于特定条件分析了 DQN 算法的经验重放机制。例如, Szlak and Shamir (2021) 提供了带经验重放的Q-learning在表格设置下的收敛率保证。Ramaswamy and Hüllermeier (2022) 从动力系统的角度出发,在现实和可验证的假设条件下,对带有经验重放的深度Q-learning的一个流行版本进行了理论分析。
- 同时,一些文献分析了目标网络机制。Carvalho et al. (2020) 建立了DQN中目标网络与线性函数逼近相结合的Q-learning的收敛性。但同时对其两种机制的理论解释仍然缺乏。
最近有许多同时研究两种机制的理论结果是基于函数逼近器的线性性的。虽然这些初步的结果是重要的和有趣的,但由于不切实际的简化和限制性的假设,它们并不能立即适用于在实践中实施的深度Q学习。
- Agarwal et al. (2021) 介绍了一种带有经验重放和在线目标学习等 "启发式 "修正的Q-learning算法。
- Andrea et al. (2022) 设计了一种Q-learning算法的变体,其中包含目标网络和一种称为策略重放的重放机制。
- Nagaraj et al. (2022) 将Q-learning与在线目标学习和反向经验重放相结合,提出了Q-Rex算法。
近年来,也有研究考虑了DQN非线性函数逼近,即神经网络。
- Liu et al. (2022) 重点研究了通过 α α α平滑Q函数进行 ε \varepsilon ε贪婪探索的DQN算法。
- Zhang et al. (2023) 解决了前者对稀疏神经网络的限制,提供了DQNs实际设置的理论收敛性和样本复杂度分析。
虽然目前有很多关于DQN算法的理论研究,但我们没有发现从随机动力学角度分析这两种机制的工作。