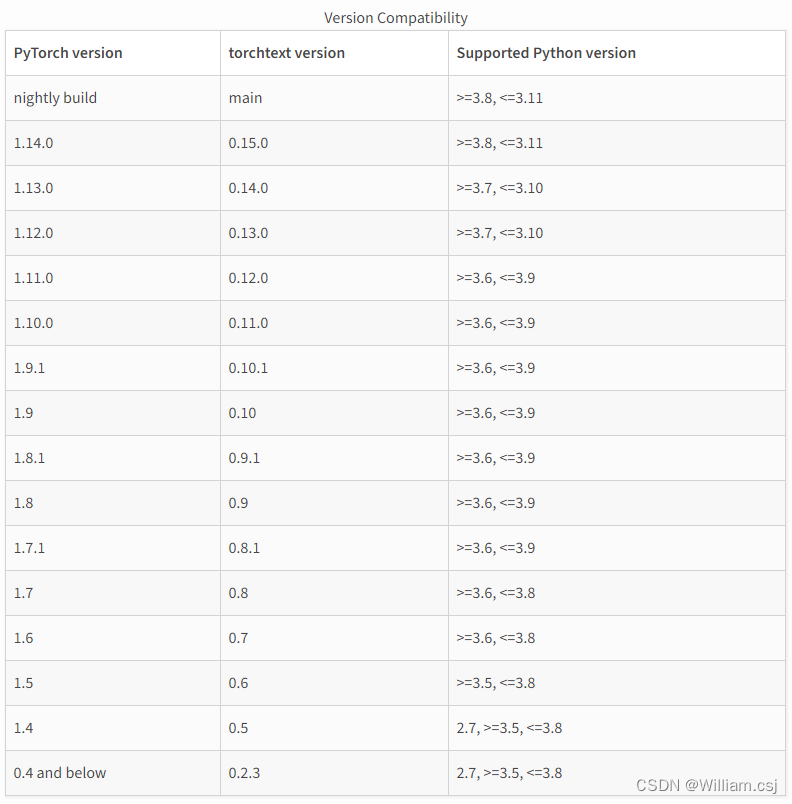
TorchText基本使用方法
TORCHTEXT.NN
MultiheadAttentionContainer:多头注意力容器
torchtext.nn.MultiheadAttentionContainer(nhead, in_proj_container, attention_layer, out_proj, batch_first=False)参数 作用 nhead 多头注意力模型中的头数 in_proj_container 投影线性层中的多头容器 attention_layer 自定义注意力层 out_proj 多头投影层 batch_first 批次是否在第一维度 例子:
import torch from torchtext.nn import MultiheadAttentionContainer, InProjContainer, ScaledDotProduct # 词嵌入维度 embed_dim = 10 # 头的数量 num_heads = 5 # 一批处理数据量 batchSize = 64 in_proj_container = InProjContainer(torch.nn.Linear(embed_dim, embed_dim), torch.nn.Linear(embed_dim, embed_dim), torch.nn.Linear(embed_dim, embed_dim)) multiheadAttentionContainer = MultiheadAttentionContainer(num_heads, in_proj_container, ScaledDotProduct(), torch.nn.Linear(embed_dim, embed_dim)) query = torch.rand((21, batchSize, embed_dim)) key = value = torch.rand((16, batchSize, embed_dim)) attn_output, attn_weights = multiheadAttentionContainer(query, key, value) print(attn_output.shape)
TORCHTEXT.DATA.FUNCTIONAL
generate_sp_model:生成model
torchtext.data.functional.generate_sp_model(filename, vocab_size=20000, model_type='unigram', model_prefix='m_user')参数 作用 filename 用于训练 SentencePiece 模型的数据文件 vocab_size 词汇量(默认值:20,000) model_type SentencePiece 模型的类型,包括 unigram, bpe、char、word model_prefix 保存模型和词汇的文件的前缀 例子:
from torchtext.data.functional import generate_sp_model generate_sp_model('test.csv', vocab_size=23456, model_prefix='spm_user')load_sp_model:加载model
参数 作用 spm 保存句子模型的文件路径或文件对象 例子:
from torchtext.data.functional import load_sp_model sp_model = load_sp_model("m_user.model") sp_model = load_sp_model(open("m_user.model", 'rb'))sentencepiece_numericalizer:用于将文本句子数值化的句子模型
例子:
from torchtext.data.functional import sentencepiece_numericalizer sp_id_generator = sentencepiece_numericalizer(sp_model) list_a = ["picked up a book", "they could be a tool"] list(sp_id_generator(list_a))sentencepiece_tokenizer:将文本句子转换为模型所需的输入格式
例子:
from torchtext.data.functional import sentencepiece_tokenizer sp_tokens_generator = sentencepiece_tokenizer(sp_model) list(sp_tokens_generator(list_a))custom_replace:文本字符串的转换
例子:
from torchtext.data.functional import custom_replace custom_replace_transform = custom_replace([(r'S', 's'), (r'\s+', ' ')]) list_a = ["Sentencepiece encode aS pieces", "exampleS to try!"] list(custom_replace_transform(list_a))simple_space_split:按空格拆分文本字符串的转换
例子:
from torchtext.data.functional import simple_space_split list_a = ["Sentencepiece encode as pieces", "example to try!"] list(simple_space_split(list_a))numericalize_tokens_from_iterator:将token转换为id
参数 作用 vocab 将token转换为 ID 的词汇表 iterator 迭代器生成一个token列表 removed_tokens 从输出数据集中删除的标记 例子:
from torchtext.data.functional import simple_space_split from torchtext.data.functional import numericalize_tokens_from_iterator vocab = { 'Sentencepiece' : 0, 'encode' : 1, 'as' : 2, 'pieces' : 3} ids_iter = numericalize_tokens_from_iterator(vocab, simple_space_split(["Sentencepiece as pieces","as pieces"])) for ids in ids_iter: print([num for num in ids])
TORCHTEXT.DATA.METRICS
用于计算和处理文本数据集中的指标。它提供了一些用于评估模型性能的函数和类,可以帮助您在训练和测试模型时度量和监控模型的性能。
bleu_score:计算候选翻译语料库和参考文献之间的 BLEU 分数
参数 作用 candidate_corpus 候选翻译的可迭代对象 references_corpus 参考翻译的可迭代对象 max_n 使用n-gram weights 用于每个 n-gram 类别的权重列表(默认统一) 例子:
from torchtext.data.metrics import bleu_score candidate_corpus = [['My', 'full', 'pytorch', 'test'], ['Another', 'Sentence']] references_corpus = [[['My', 'full', 'pytorch', 'test'], ['Completely', 'Different']], [['No', 'Match']]] bleu_score(candidate_corpus, references_corpus)
TORCHTEXT.DATA.UTILS
处理文本数据集和模型训练过程中的一些常见任务。
get_tokenizer:为字符串语句生成分词器函数
参数 作用 tokenizer 如果为 None,则返回 split()函数,它按空格拆分字符串句子。如果basic_english,则返回 _basic_english_normalize()函数,首先规范化字符串并按空格拆分。如果可调用的函数,它将返回函数。如果 tokenizer库 (例如 spacy、moses、toktok、revtok、subword),它返回相应的库。 language 默认 en 例子:
from torchtext.data import get_tokenizer tokenizer = get_tokenizer("basic_english") tokens = tokenizer("You can now install TorchText using pip!")ngrams_iterator:返回一个迭代器,该迭代器生成给定的标记及其 ngram
参数 作用 token_list token列表 ngrams ngram的值 例子:
from torchtext.data.utils import ngrams_iterator token_list = ['here', 'we', 'are'] list(ngrams_iterator(token_list, 3))
TORCHTEXT.VOCAB
用于创建将标记映射到索引的 vocab 对象的工厂方法。
请注意,在构建词汇时,将遵循在ordered_dict中插入键值对的顺序。 因此,如果按token频率排序对用户很重要,则应以反映这一点的方式创建ordered_dict。
vocab
参数 作用 ordered_dict 有序字典将标记映射到其相应的出现频率 min_freq 在词汇表中包含标记所需的最低频率 specials 要添加的特殊符号。所提供token的顺序将被保留 special_first 指示是在开头还是结尾插入符号 例子:
from torchtext.vocab import vocab from collections import Counter, OrderedDict # 计数 counter = Counter(["a", "a", "b", "b", "b"]) # 按频率降序 sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True) ordered_dict = OrderedDict(sorted_by_freq_tuples) # 转换为vocab v1 = vocab(ordered_dict) print(v1['a']) # 不存在的会出错 # print(v1['out of vocab']) tokens = ['e', 'd', 'c', 'b', 'a'] # 添加 <unk> token 和默认index unk_token = '<unk>' default_index = -1 v2 = vocab(OrderedDict([(token, 1) for token in tokens]), specials=[unk_token]) v2.set_default_index(default_index) print(v2['<unk>']) print(v2['c']) # 输出-1 不会报错 print(v2['out of vocab']) # 设置默认index为unk_token的index v2.set_default_index(v2[unk_token]) #prints True v2['out of vocab'] is v2[unk_token]build_vocab_from_iterator
参数 作用 iterator 用于构建 Vocab 的迭代器。 必须产生token的列表或迭代器 min_freq 在词汇表中包含标记所需的最低频率 specials 要添加的特殊符号。所提供token的顺序将被保留 special_first 指示是在开头还是结尾插入符号 max_tokens 如果提供,则从max_tokens - len(specials)最常见的标记创建词汇 例子:
import io from torchtext.vocab import build_vocab_from_iterator file_path = "D:/CodeSave/miniCondaCode/deepLearnBase_pytorchpy39/MyProjects/深度学习基础入门_BO/专项练习/TorchTextLearn/otherFile/testPessage.csv" def yield_tokens(file_path): with io.open(file_path, encoding = 'utf-8') as f: for line in f: yield line.strip().split() vocab = build_vocab_from_iterator(yield_tokens(file_path), specials=["<unk>"])Vectors、get_vecs_by_tokens
Vectors:
参数 作用 name 包含向量的文件的名称 cache 缓存向量的目录 url 如果在缓存中找不到矢量,则下载的 URL unk_init 默认情况下,初始化词汇外的词向量 到零向量;可以是任何接受张量并返回相同大小的张量的函数 max_vectors 这可用于限制 加载预训练向量。 大多数预训练的向量集都经过排序 按词频降序排列。 因此,在整组无法放入内存的情况下, 或者由于其他原因不需要,传递max_vectors可能会限制加载集的大小 get_vecs_by_tokens:
参数 作用 tokens token或token列表。如果tokens是一个字符串, 返回形状为self.dim的一维张量。如果tokens是字符串列表,返回 shape=(len(tokens), self.dim) lower_case_backup 否以小写形式查找token。如果为 False,则将查找原始情况下的每个token。如果为True,则将首先查找原始情况下的每个token, 如果在属性stoi的键中找不到,则将查找小写字母。默认值:False。 例子:
import torchtext examples = ['chip', 'baby', 'Beautiful'] vec = torchtext.vocab.GloVe(name='6B', dim=50, cache="path") ret = vec.get_vecs_by_tokens(examples, lower_case_backup=True)词表的使用
# 查看词表 vocab.get_stoi()输出:{‘function’: 7, ‘’: 0, ‘’: 1, ‘pip’: 2, ‘!’: 3, ‘a’: 4, ‘can’: 5, ‘for’: 6, ‘torchtext’: 14, ‘generate’: 8, ‘install’: 9, ‘now’: 10, ‘sentence’: 11, ‘string’: 12, ‘tokenizer’: 13, ‘using’: 15, ‘you’: 16}
# 词表的键 vocab.get_itos()输出:[‘’, ‘’, ‘pip’, ‘!’, ‘a’, ‘can’, ‘for’, ‘function’, ‘generate’, ‘install’, ‘now’, ‘sentence’, ‘string’, ‘tokenizer’, ‘torchtext’, ‘using’, ‘you’]
# 词表长度 vocab.__len__() # 查看是否存在词表内 返回True 或者 False vocab.__contains__("pip") # 返回全部对应索引 vocab.forward(["pip", "a", "for", "function", "generate"]) vocab.lookup_indices(["pip", "a", "for", "function", "generate"]) # 默认索引 vocab.get_default_index() # 查看某个词的索引 vocab["pip"] vocab.__getitem__("pip") # 查看值对应的键 vocab.lookup_token(5) # 查看值列表对应的键 vocab.lookup_tokens([2, 4, 6, 7, 8])
TORCHTEXT.UTILS
download_from_url:从网络下载
参数 作用 url 下载地址 path 保存文件的路径 root 用于存储文件的下载文件夹 overwrite 是否覆盖现有文件 默认False hash_value 可选参数 hash_type 介于sha256和md5之间 默认sha256 例子:
import torchtext url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz' torchtext.utils.download_from_url(url) url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz' torchtext.utils.download_from_url(url) '.data/validation.tar.gz'extract_archive:提取本地存档
参数 作用 from_path 存档的路径 to_path 解压文件的根路径 overwrite 是否覆盖现有文件 例子:
import torchtext url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz' from_path = './validation.tar.gz' to_path = './' torchtext.utils.download_from_url(url, from_path) torchtext.utils.extract_archive(from_path, to_path) torchtext.utils.download_from_url(url, from_path) torchtext.utils.extract_archive(from_path, to_path)