目录
堆一般,是将数组看作一颗完全二叉树
小堆要求:任意一个父亲<=孩子
大堆要求:任意一个父亲>=孩子
有序数组一定是堆
但是堆不一定有序
注意:此“堆”是一个数据结构,用来表示完全二叉树
还有另外一个“堆”,是内存区域的划分,是我们动态申请内存的内存区域,属于操作系统的概念
属于不同学科中的同名概念而已
堆的意义是什么?
1、堆排序,O(N*logN)(在一堆数据中找到某个数据)
2、top K问题(一堆数据中找到前K个最大或者最小的数据)
堆二叉树插入值:向上调整,和其祖先进行比较
数组可以建立堆的核心是,利用完全二叉树的父子和左右孩子下标的关系特点
同时,在实际的物理存储中是数组,但是想象中,我们处理的是逻辑结构中的完全二叉树
建堆:
传入数组,堆数组下标进行控制,一个一个数据进堆,根据大堆还是小堆进行相应的向上调整
free就算传入的是空,也没有问题,因为free对空进行了检查
正数数据类型:size_t
调试:结构体内部情况struct.a,8(这个8代表的是a中的8个数据值)
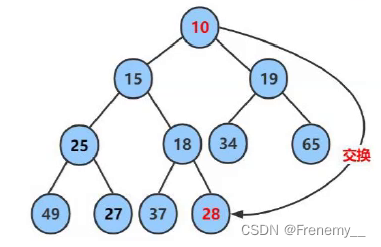
堆的删除默认是删除堆顶
向下调整算法:删除堆顶元素,数组尾和堆顶元素交换,删除尾巴,然后交换过去的堆顶又向下调整
堆排序:
插入主要是向上调整
与父节点比较
主要的核心逻辑是向下调整以及向上调整
我们建堆,是将数组的数组插入一个新的空间堆,空间复杂度是O(n),本质意义上不是排序,只是当删除堆的时候会把最大或者最小的数据放出来
所以,输出删除的数据会呈现升序或者降序的形式,但是本质上并不是排序,因为数组本身并没有什么变化
而排序是要在数组本身位置堆数组进行排序
所以堆排序,需要对数组本身进行排序,也就是对数组本身进行建堆
如果使用堆进行排序,当pop出最小或者最大的一个数时,那么按照堆排序的逻辑,要选出次小的数据,就需要剩下的数据也是一个小堆
但是,事实上,当把二叉树的根删除,剩下的数据我们并不能保证还是一个堆,那么,如果按照此思路走下去,就需要对剩下的数据重现建堆
那么显然,为了选出一个数据,要对整体的数据进行建堆,代价太大了。
我们对数据进行堆排序,如果是升序,建大堆
如果是降序,建立小堆
为什么?
例如升序:
建立大堆
将最后的数据头尾交换,size--
此时i相当于最大的数据放在了最后面子
之后再队下一次的堆进行向下调整,得到当前堆的最大值,也就是整体的次大值
然后再头尾交换,如此反复,就是依次得到次小的数据
降序也是这个逻辑
产生随机值:
srand(time(0));
int x = rand() % 100;//产生100以内的随机数
随机数在库里面只能产生3万多个数据
所以,如果要产生超过10万随机数据,那么就会有7万个数据是重复的
所以,(rand()+i) % 100000;就会减少很多重复的数据
写文件 :fprintf(文件地址,数据类型,数据值);
读取文件数据:fsacnf
取前K个最大的值
建立一个K的小堆
如果遇到一个比小堆根还大的值,交换,然后向下调整
为什么建立小堆?
因为这样保证比较大值都会调整到堆的底部,不会挡住其他值进入堆
如果是找到前K个最小的值呢?
反过来,就是建立大堆,只要比大堆根值大的值就替换堆的根
然后向下调整,一样的逻辑
调试可以使用条件式
调试技巧:设置一个条件断点
空语句不能设置断点
当数据量特别大的时候,我们只想看某些特定数据,就可以使用条件断点
scanf默认换行和空格是读取数据的分割结束
建堆的第二种方式:保证根的左右子树都是堆,然后根向下进行调整
怎么保证根的左右子树都是堆?从倒数的第一个非叶子,也就是最后一个节点的父亲进行逐上进行向下的堆调整
这种方式建堆效率更高,O(N),而且只需要写一个向下调整函数即可
向下调整建堆:因为是向下调整,所以最后一层是叶子节点,叶子节点是不需要向下调整的,只有有叶子节点的节点才需要向下调整
所以,向上调整需要从第二层的最后一个节点开始向下调整,如果是满二叉树,那么二叉树的倒数第二层的最后一个节点,就是最后一个叶子节点的父亲节点。
从这个节点开始,逐个往前开始向下调整,
倒数第二层是第h-1层,需要向上调整h-1次,就算每一个都需要调整,也就是调整2^(h-1)次
如此推之,直到算出最后的调整次数,即时间复杂度
向上调整建堆:因为是向上调整,我们就需要保证上面的节点已经满足堆的,所以我们是从上往下遍历向上调整,逐个进行调整建堆
从第一层开始,往上调整,2^0个节点,调整高度-1次,即0次
第二层开始,往上调整,2^1个节点,调整高度-1次,即1次
第三层开始,往上调整,2^1个节点,调整高度-1次,即2次
依次推之,直到最后一层
最后一层开始,向上调整,2^(h-1)个节点,调整高度-1次,即h-1次数
所有次数相加,算出结果。
其实很明显,向上调整需要对最后一层节点个数最多的层数进行向上调整,而且次数也是最多的,而向下调整并不需要像这样处理最后一层的节点。
因此,即使不用计算出准确的时间复杂度,也能知道向下调整的时间复杂度要比向上调整的要好一些。
源码
测试:
#include"Heap.h"
int main ()
{
int a[] = {9,5,3,2,8,0,1,3,5};
Heap hp;
HeapInit(&hp);
int n = sizeof(a) / sizeof(int);
HeapCreate(&hp,a,n);
for (int i = 0;i<n;++i)
{
printf("%d ",hp._a[i]);
}
HeapPush(&hp,100);
HeapPush(&hp,900);
printf("\n");
for (int i = 0; i < n+2; ++i)
{
printf("%d ", hp._a[i]);
}
printf("\n");
HeapPop(&hp);
HeapPop(&hp);
for (int i = 0; i < n; ++i)
{
printf("%d ", hp._a[i]);
}
printf("\n");
printf("%d\n",HeapTop(&hp));
HeapPop(&hp);
printf("%d\n", HeapSize(&hp));
HeapDestory(&hp);
return 0;
}头文件:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
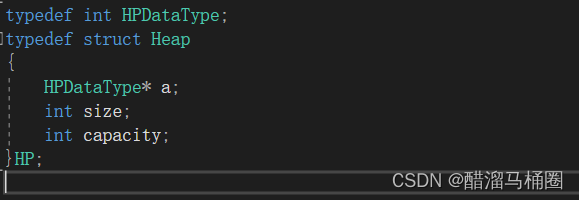
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
//交换函数
void Swap(HPDataType* a, HPDataType* b);
//向下调整
void AdujustDown(HPDataType* a, int size,int parent);
//向上调整
void AdujustUp( HPDataType* a, int child);
//初始化堆
void HeapInit(Heap* hp);
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
.c文件:
#include"Heap.h"
//大堆
//初始化堆
void HeapInit(Heap* hp)
{
assert(hp);
hp->_a = NULL;
hp->_capacity = hp->_size = 0;
}
void Swap(HPDataType* a, HPDataType*b)
{
HPDataType tmp = *a;
*a = *b;
*b = tmp;
}
//向下调整
void AdujustDown(HPDataType* a, int size, int parent)
{
//假设左孩子比较大
int child = parent * 2 + 1;
while(child < size)
{
if (child + 1 < size && a[child + 1] > a[child])
{
//更改比较大孩子
++child;
}
if (a[parent] < a[child])
{
Swap(&a[parent],&a[child]);
parent = child;//更新父节点
child = parent * +1;//依旧将孩子更新为左孩子
}
else
{
break;
}
}
}
//向上调整
void AdujustUp(HPDataType* a, int child)
{
//从孩子位置开始向上调整
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
Swap(&a[child],&a[parent]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);
HPDataType* tmp = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (tmp ==NULL)
{
perror("malloc fail");
exit(-1);
hp->_a = tmp;
hp->_size = n;
hp->_capacity = n;
}
//每插入一个值,就调整一个值
for (int i = 0;i<n;++i)
{
AdujustUp(a,i);
}
for (int i = 0;i<n;++i)
{
HeapPush(&hp->_a,a[i]);
}
}
// 堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);
hp->_a = NULL;
hp->_capacity = 0;
hp->_size = 0;
printf("Destory Succeed\n");
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
//扩容
if (hp->_capacity == hp->_size)
{
int newCapacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(hp->_a,sizeof(HPDataType) * newCapacity);
if (tmp == NULL)
{
perror("realloc fail ");
exit(-1);
}
hp->_a = tmp;
hp->_capacity = newCapacity;
}
hp->_a[hp->_size] = x;
hp->_size++;
//插入后向上调整
AdujustUp(hp->_a,hp->_size - 1);
}
// 堆的删除
void HeapPop(Heap* hp)
{
assert(hp);
assert(hp->_size > 0);
//先交换,再向下调整
Swap(&hp->_a[0],&hp->_a[hp->_size - 1]);
hp->_size--;
AdujustDown(hp->_a,hp->_size,0);
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(hp->_size > 0);
return hp->_a[0];
}
// 堆的数据个数
int HeapSize(Heap* hp)
{
assert(hp);
return hp->_size;
}
// 堆的判空
int HeapEmpty(Heap* hp)
{
assert(hp);
return hp->_size == 0;
}




































![[VulnHub靶机渗透] WestWild 1.1](https://img-blog.csdnimg.cn/direct/099d1841a1064f5ab4289251c7f68ca2.png)