前言
爬网页又遇到一个坑,老是出现â乱码,查看html出现的是&#数字;这样的。
网上相关的“Python字符中出现&#的解决办法”又没有很好的解决,自己继续冲浪,费了一番功夫解决了。
这算是又加深了一下我对这些iso、Unicode编码的理解。故分享。
问题
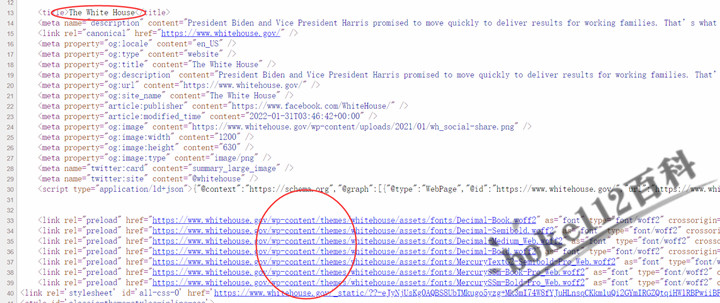
用Python的lxml解析html时,调用text()输出出来的结果带有â这样的乱码:

网页原页面展示:

爬取代码:
url = "xxx"
response = requests.request("GET", url)
html = etree.HTML(response.text)
# 直接调用text函数
description = html.xpath('//div[@class="xxx"]/div/div//text()')
# 直接打印
for desc in description:
print(desc)原因
不用说自然是编码的问题。下面教大家排查和解决。
排查与解决
首先查看返回的响应是如何编码的:
response = requests.request("GET", url, proxies=proxy)
# 得到响应之后,先检查一下它的编码方式
print(response.encoding)结果如下:

然后根据这个编码的方式再来解码:
html = etree.HTML(response.text)
description = html.xpath('//div[@class="xxx"]/div/div//text()')
for desc in description:
# print(desc)
# 根据上面的结果,用iso88591来编码,再解码为utf-8
print(desc.encode("ISO-8859-1").decode("utf-8"))
结果如下:

完整代码:
url = "xxx"
response = requests.request("GET", url)
print(response.encoding)
html = etree.HTML(response.text)
description = html.xpath('//div[@class="xxx"]/div/div//text()')
for desc in description:
print(desc.encode("ISO-8859-1").decode("utf-8"))
# print(desc)总结
网上有用python2流传下来的HTMLParser的,还有用python3的html包的,效果都不好。
不过也有改response的编码方式的,就是这样:
url = "xxx"
response = requests.request("GET", url)
# html = etree.HTML(response.text)
html = etree.HTML(response.content) # 改用二进制编码
# 直接调用text函数
description = html.xpath('//div[@class="xxx"]/div/div//text()')
# 直接打印
for desc in description:
print(desc)也能成功解析。
参考文章: