三分钟学会使用系列(YOLOv5)|SA注意力机制,涨点神器!
- 原文地址:《SA-NET: Shuffle attention for deep convolutional neural networks》
- 代码地址:《**SA-Net/models/sa_resnet.py at main · wofmanaf/SA-Net **》
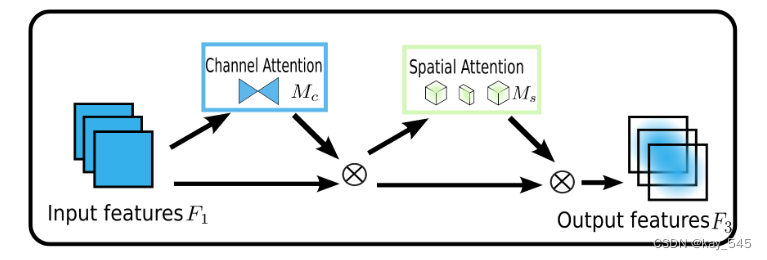
1. SA注意力导读
SA-Net发表于ICASSP 2021,是由南京大学杨育彬等人提出了一种新的注意力机制:置换注意力机制(shuffle attention)。它是一种引入了特征分组与通道置换的超轻量型空间-通道注意力机制。在ImageNet与MS-COCO数据集上取得了优于SE、SGE等性能,同时具有更低的计算复杂度和参数量。

2. 代码
SA代码。
class sa_layer(nn.Module):
"""Constructs a Channel Spatial Group module.
Args:
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, groups=64):
super(sa_layer, self).__init__()
self.groups = groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.cweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sigmoid = nn.Sigmoid()
self.gn = nn.GroupNorm(channel // (2 * groups), channel // (2 * groups))
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.shape
x = x.reshape(b * self.groups, -1, h, w)
x_0, x_1 = x.chunk(2, dim=1)
# channel attention
xn = self.avg_pool(x_0)
xn = self.cweight * xn + self.cbias
xn = x_0 * self.sigmoid(xn)
# spatial attention
xs = self.gn(x_1)
xs = self.sweight * xs + self.sbias
xs = x_1 * self.sigmoid(xs)
# concatenate along channel axis
out = torch.cat([xn, xs], dim=1)
out = out.reshape(b, -1, h, w)
out = self.channel_shuffle(out, 2)
return out
3. 使用教程
以YOLOv5为例,加入SA注意力机制。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[ -1, 1, sa_layer, []],
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4. 参考
- 原文地址:《SA-NET: Shuffle attention for deep convolutional neural networks》
- 代码地址:《**SA-Net/models/sa_resnet.py at main · wofmanaf/SA-Net **》




















![[Linux]动静态库(什么是动静态库,怎么生成动静态库,怎么使用(连接)动静态库)](https://img-blog.csdnimg.cn/direct/e35412390d444735abe788c70ac5f6ca.png)





![Orion-14B-Chat-Plugin [model server error]解决方案](https://img-blog.csdnimg.cn/direct/abf0798c05de447882c36b305a8b6697.png#pic_center)