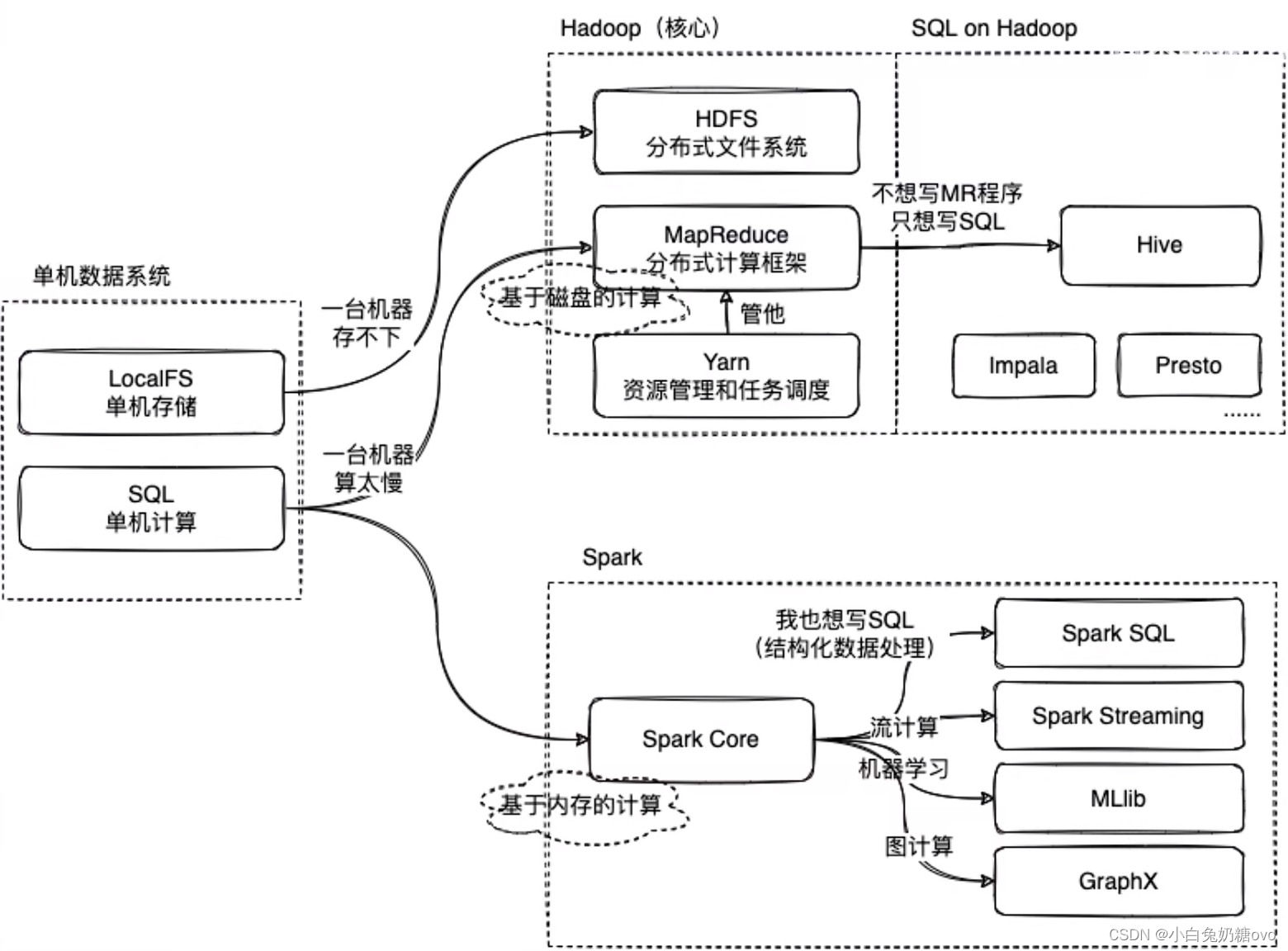
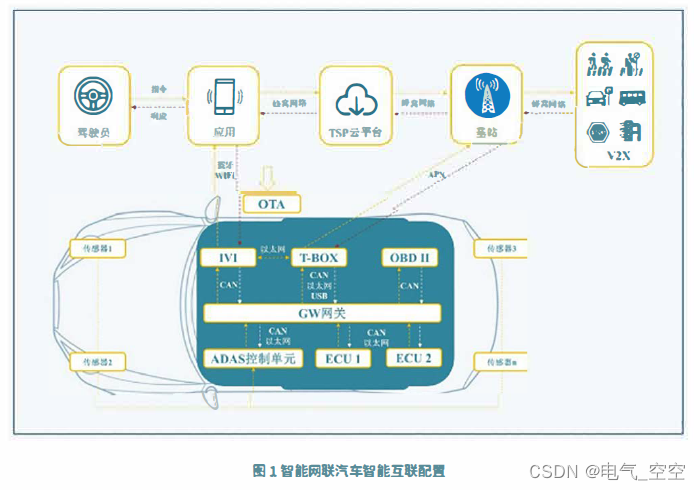
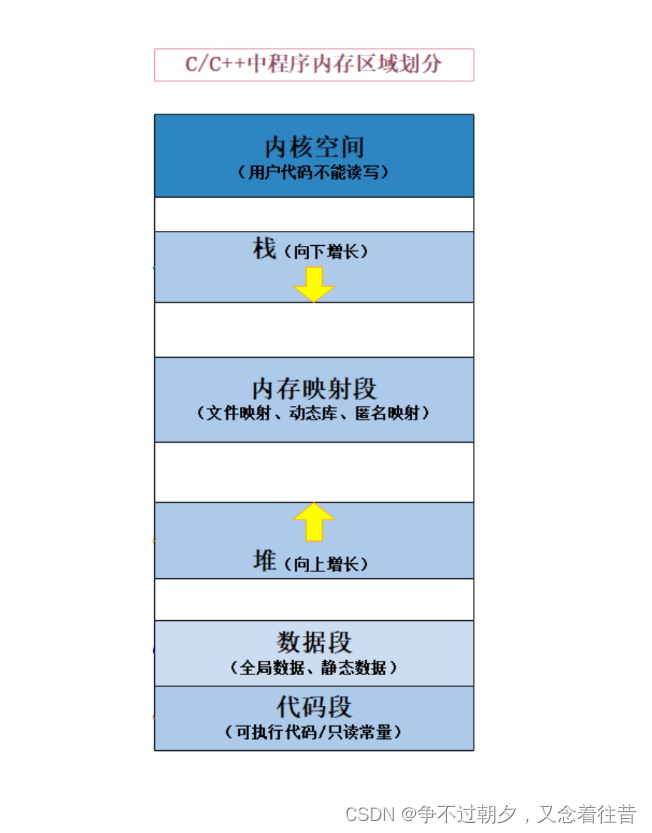
大数据∈数据管理系统的范畴
- 数据管理系统:
- 数据怎么存?
- 数据怎么算?
单机数据管理时代下,
- 数据处理的任务:IO密集型;
数据存不下?- HDFS用于存放多机器的数据并提供相关Api接口。
HDFS中引入了一个模块:MapReduce(基于磁盘计算)。
MapReduce:提供了一个任务并行的框架,通过它的Api抽象让用户把这个并行程序分成两个阶段,即Map阶段(分工),Reduce阶段(汇总)。
- HDFS用于存放多机器的数据并提供相关Api接口。
Hive:在Hadoop上写SQL,进行结构化处理的解决方案(类似的方案还有impala,presto等)
- SQL中的S就是结构化处理的意思。
- 核心模块:metastore,用于存储结构化的信息
Spark:计算框架(基于内存计算)
- 提供了streaming的模块,用于写流处理的程序;
- 提供了Mlib的模块,用于写机器学习的程序;
- 提供了GraphX的模块,用于写图处理的程序。