先补充一些小知识:
dfs和回溯的区别
深度优先搜索(DFS)和回溯是两种常用的算法思想,它们在解决问题时有一些相似之处,但也有一些不同之处。
深度优先搜索(DFS)是一种 用于遍历或搜索图、树或其他数据结构的算法。 它从一个起始节点开始,沿着一条路径尽可能深地搜索,直到无法继续或达到目标节点。然后,它回溯到之前的节点,并尝试其他的路径。DFS 是一种 递归的算法,通过调用自身来实现深度搜索。DFS 的特点是先深度后回溯。
回溯算法是一种解决问题的通用算法,它通过尝试不同的选择来找到解。回溯算法通常用于组合问题、排列问题、搜索问题等。 在回溯算法中,我们逐步构建解,并在每一步尝试不同的选择,如果当前的选择导致无法找到解,那么我们回溯到上一步并尝试其他的选择。回溯算法通常使用 递归 来实现。回溯的特点是试错和撤销。
总结来说,DFS 是一种用于遍历或搜索特定数据结构的算法,而回溯是一种通用的解决问题的算法思想。DFS 可以看作是一种特殊的回溯算法,它在实现过程中使用了回溯的思想。
在实际应用中,DFS 和回溯通常会结合使用。例如,在图的深度优先搜索中,可以使用回溯来记录访问过的节点,并在回溯时撤销访问过的节点。在排列组合问题中,也可以使用回溯来生成所有可能的组合,并在回溯时撤销选择。
因此下面这两道单词搜索的题目,因为是图的形式,因此使用DFS
- 单词搜索
中等
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
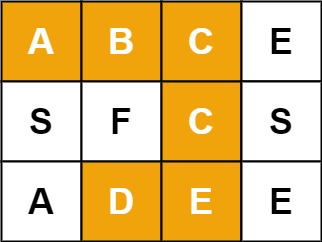
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCCED”
输出:true
示例 2:
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “SEE”
输出:true
示例 3:
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCB”
输出:false
//使用DFS算法(特殊的回溯算法)
func exist(board [][]byte, word string) bool {
rows, cols := len(board), len(board[0])
var dfs func(row, col, index int) bool
dfs = func(row, col, index int) bool {
// 边界条件检查
if row < 0 || row >= rows || col < 0 || col >= cols || board[row][col] != word[index] {
return false
}
// 如果已经匹配到最后一个字符,返回 true(因为在board[row][col] != word[index]已经对字母进行判断)
if index == len(word)-1 {
return true
}
// 保存当前字符,避免重复使用
temp := board[row][col]
// 标记当前字符已使用
board[row][col] = '.'
// 递归调用上下左右四个方向
if dfs(row-1, col, index+1) || dfs(row+1, col, index+1) || dfs(row, col-1, index+1) || dfs(row, col+1, index+1) {
return true
}
// 恢复原始字符,进行回溯(主要是当网格中存在字母相同时,最开始选到的字母并不符合条件,只能跳出递归,从新选择起点)
board[row][col] = temp
return false
}
// 遍历整个二维网格(目的是选择起点位置,如果在index=0时返回false,那么就不是起点,继续遍历)
for i := 0; i < rows; i++ {
for j := 0; j < cols; j++ {
if dfs(i, j, 0) {
return true
}
}
}
return false
}
- 单词搜索 II
困难
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
输入:board = [[“o”,“a”,“a”,“n”],[“e”,“t”,“a”,“e”],[“i”,“h”,“k”,“r”],[“i”,“f”,“l”,“v”]], words = [“oath”,“pea”,“eat”,“rain”]
输出:[“eat”,“oath”]
示例 2:
输入:board = [[“a”,“b”],[“c”,“d”]], words = [“abcb”]
输出:[]
func findWords(board [][]byte, words []string) []string {
rows, cols := len(board), len(board[0])
result := []string{
}
// 定义一个辅助函数,用于进行深度优先搜索
var dfs func(row, col, index int, word string)
dfs = func(row, col, index int, word string) {
// 边界条件检查
if row < 0 || row >= rows || col < 0 || col >= cols || board[row][col] == '#' || board[row][col] != word[index] {
return
}
// 如果已经匹配到最后一个字符,将当前单词添加到结果列表中
if index == len(word)-1 {
result = append(result, word)
return
}
// 保存当前字符,避免重复使用
temp := board[row][col]
// 标记当前字符已使用
board[row][col] = '#'
// 递归调用上下左右四个方向
dfs(row-1, col, index+1, word)
dfs(row+1, col, index+1, word)
dfs(row, col-1, index+1, word)
dfs(row, col+1, index+1, word)
// 恢复原始字符,进行回溯
board[row][col] = temp
}
// 遍历单词列表
for _, word := range words {
// 遍历整个二维网格,以每个位置作为起点位置调用 dfs 函数
for i := 0; i < rows; i++ {
for j := 0; j < cols; j++ {
dfs(i, j, 0, word)
}
}
}
// 去重结果列表中的重复单词
uniqResult := make(map[string]bool)
for _, word := range result {
uniqResult[word] = true
}
finalResult := []string{
}
for word := range uniqResult {
finalResult = append(finalResult, word)
}
return finalResult
}
//但是时间超出限制,因此需要添加trie树
虽然上述的代码过程是正确的,仅使用到DFS,和第一题的解法类似,但是超出了时间限制,因此需要减少遍历的时间,引入Trie树(前缀树)
- Trie 树(也称为前缀树)是一种用于高效存储和搜索字符串的数据结构。 在这个问题中,使用 Trie 树的原因是为了加速单词的匹配。
- 在给定的二维网格中,需要搜索是否存在给定的单词。如果使用简单的暴力搜索方法,对于每个单词都需要遍历整个二维网格,时间复杂度将非常高。
- 而 使用 Trie 树可以极大地减少搜索的时间复杂度。 通过构建 Trie 树,我们可以将单词的前缀存储在 Trie 树中,然后在搜索过程中,只需要在 Trie 树中进行匹配即可,避免了不必要的遍历操作。
- 具体来说,在构建 Trie 树时,我们可以将所有的单词插入到 Trie 树中,每个节点表示一个字符。然后,在搜索过程中,我们可以根据当前位置的字符在 Trie 树中进行匹配,如果匹配成功,则继续搜索下一个字符;如果匹配失败,则可以直接返回,无需继续搜索。
- 通过使用 Trie 树,可以将搜索的时间复杂度降低到 O(n),其中 n 是所有单词的总长度。
type TrieNode struct {
children [26]*TrieNode
word string
}
func findWords(board [][]byte, words []string) []string {
rows, cols := len(board), len(board[0])
result := []string{
}
root := buildTrie(words)
var dfs func(row, col int, node *TrieNode)
dfs = func(row, col int, node *TrieNode) {
// 边界条件检查
if row < 0 || row >= rows || col < 0 || col >= cols || board[row][col] == '#' {
return
}
// 获取当前字符
ch := board[row][col]
// 检查当前字符是否在 Trie 树中
node = node.children[ch-'a']
if node == nil {
return
}
// 更新结果列表
if node.word != "" {
result = append(result, node.word)
node.word = "" // 避免重复添加单词
}
// 保存当前字符,避免重复使用
board[row][col] = '#'
// 递归调用上下左右四个方向
dfs(row-1, col, node)
dfs(row+1, col, node)
dfs(row, col-1, node)
dfs(row, col+1, node)
// 恢复原始字符,进行回溯
board[row][col] = ch
}
// 遍历整个二维网格,以每个位置作为起点位置调用 dfs 函数
for i := 0; i < rows; i++ {
for j := 0; j < cols; j++ {
dfs(i, j, root)
}
}
return result
}
func buildTrie(words []string) *TrieNode {
root := &TrieNode{
}
for _, word := range words {
node := root
for _, ch := range word {
index := ch - 'a'
if node.children[index] == nil {
node.children[index] = &TrieNode{
}
}
node = node.children[index]
}
node.word = word
}
return root
}
//使用了 Trie 树(前缀树)来加速单词的匹配。首先,我们先构建一个 Trie 树,将所有的单词插入到 Trie 树中。然后,我们遍历整个二维网格,以每个位置作为起点位置调用深度优先搜索(DFS)。
//在 dfs 函数中,我们首先检查当前位置是否越界,如果越界则直接返回。然后,我们获取当前位置的字符,并检查该字符是否在 Trie 树中。如果不在,则直接返回。
//如果当前位置的字符在 Trie 树中,我们将当前位置的字符标记为已使用(例如用 #),然后递归调用 dfs 函数,继续在上、下、左、右四个方向上进行搜索。
//在递归调用之前,我们需要更新 Trie 树的节点,将其移动到下一层节点。如果移动后的节点表示一个单词,则将该单词添加到结果列表中,并将该节点的 word 字段置为空字符串,以避免重复添加单词。
//在递归调用之后,我们需要恢复当前位置的字符,进行回溯。
//最后,在主函数中,我们遍历每个起点位置,并调用 dfs 函数进行搜索。将找到的单词添加到结果列表中,并返回结果列表。