前言
在 源码篇–Redis 底层数据结构 章节中介绍了redis 底层的数据结构,而底层的数据结构又是为了数据存储而设计的,那么redis 中我们都可以存入哪些数据类型呢?
一、 字符串类型:
在redis 中我们可以直接将字符串,作为key 或者value 进行存储,它的底层 就是使用了 SDS 进行实现的;
1.1 字符串的编码格式:
1.1.1 raw 编码格式:
基于动态字符串(sds) 实现,存储数据的最大上限为512mb;
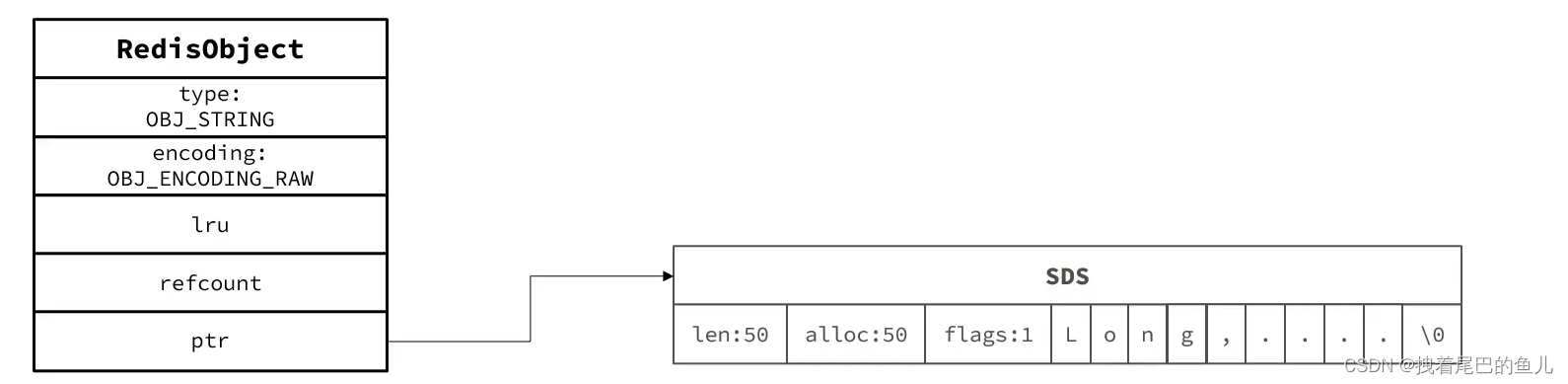
- 此时 ptr 是指向 sds 数据对象的指针; sds 对象指向独立的内存空间,使用raw 存储时需要分别申请redisobject 和sds 的内存空间;
1.1.2 empstr编码格式:
当字符串的长度小于44 字节 总的redisobject 的长度占用是最多是64字节(redis 分配内存时不会产生内存碎片),会使用empstr 编码,此时object head 与sds 是连续的内存空间,申请内存时 可以一次性申请所需要内存,效率更高;如果超过 44 字节会转为 raw 编码格式;

可以看到存入的如果是字符串最终都是通过SDS 实现的,如果我们存储的虽然是字符串,但是它实际上是一个正数值,那么redis 底层会采用 int 的编码;
1.1.3 int 编码格式:
当存储的字符串是一个整数值,大小在LONG_MAX 范围内,使用 int 编码,将redisobject 的 ptr 指针位置(刚好8字节64 位)直接存储数据,不需要在使用sds 部分:

1.1.4 字符串存储结构展示:
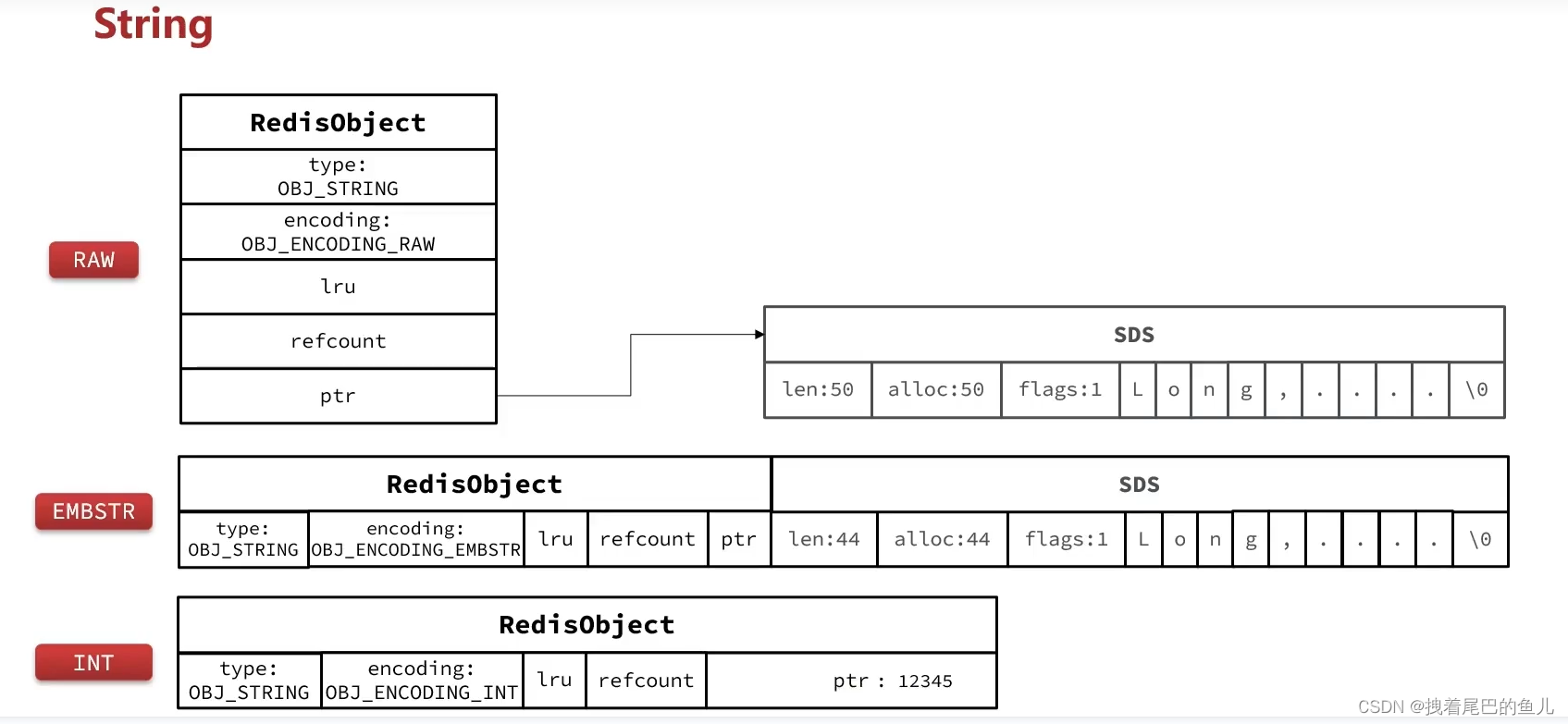
所以我们在向redis存入字符串时,其底层使用的数据 结构并不是一成不变的,加入一开始存入 一个‘100’ 的整数字符串,其使用int 编码;
如果我们此时进行修改为 ‘name’ 因为其只有4个字符,所以此时编码是 empstr,如果我们存储的字符串超过 44个字节 又会变成raw 格式;我们在存储字符串尽量不要超过44个字节,如果可以使用整数,尽量使用整数;
二、 list类型:
2.1 List 底层数据支持:
list 集合,我们可以从首尾进行元素的插入和读取;
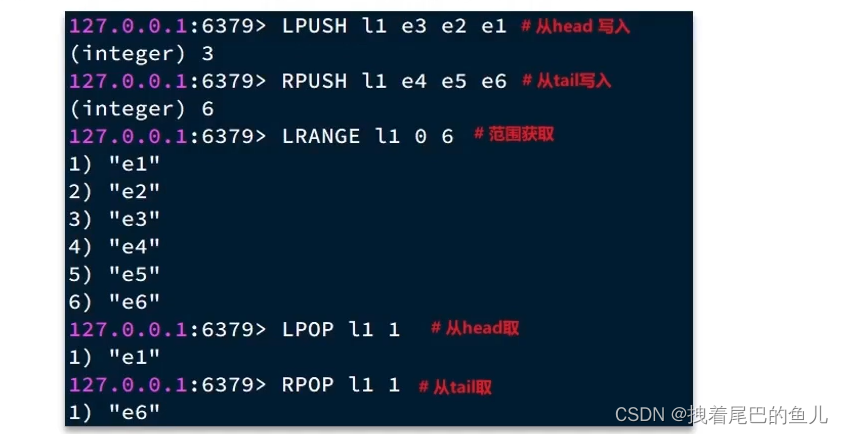
显然链表结构就可以完美支持:
- LinkedList:普通链表,可以从双端访问,内存占用较高,内存碎片较多;
- zipList: 压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList: LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高;
2.2 List 源码实现:
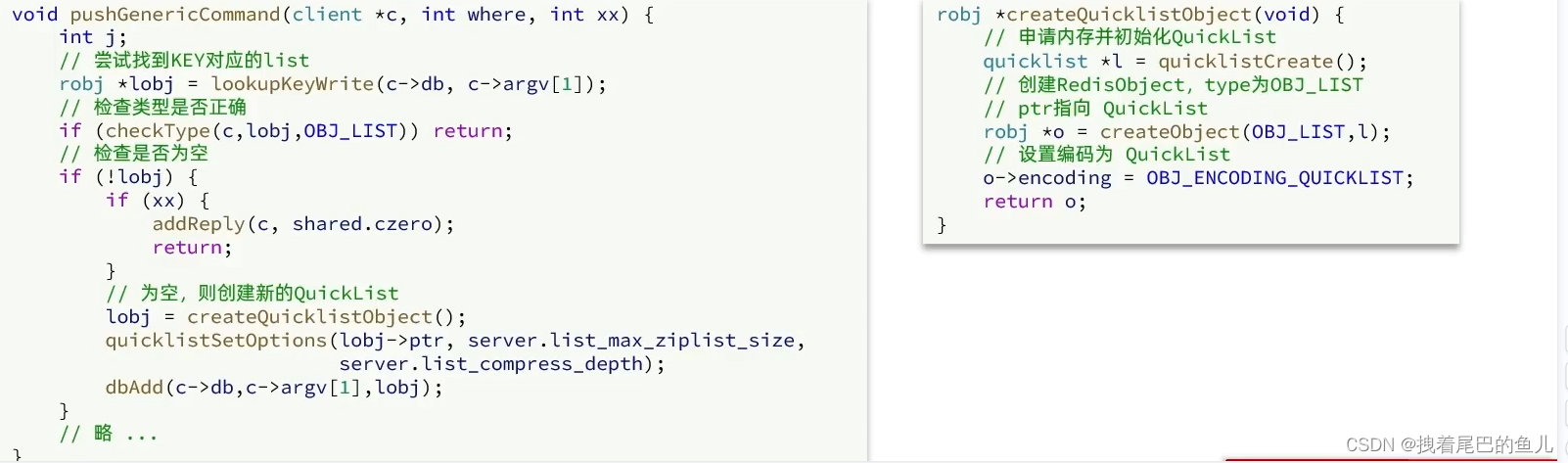
先根据list 的key 找对应的链表 如果找到则直接插入,如果没有找到 在进行链表的创建,然后插入;在3.2版本之前,Redis采用ZioList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。在3.2版本之后,Redis统一采用QuickList来实现List;
2.3 List 结构展示:
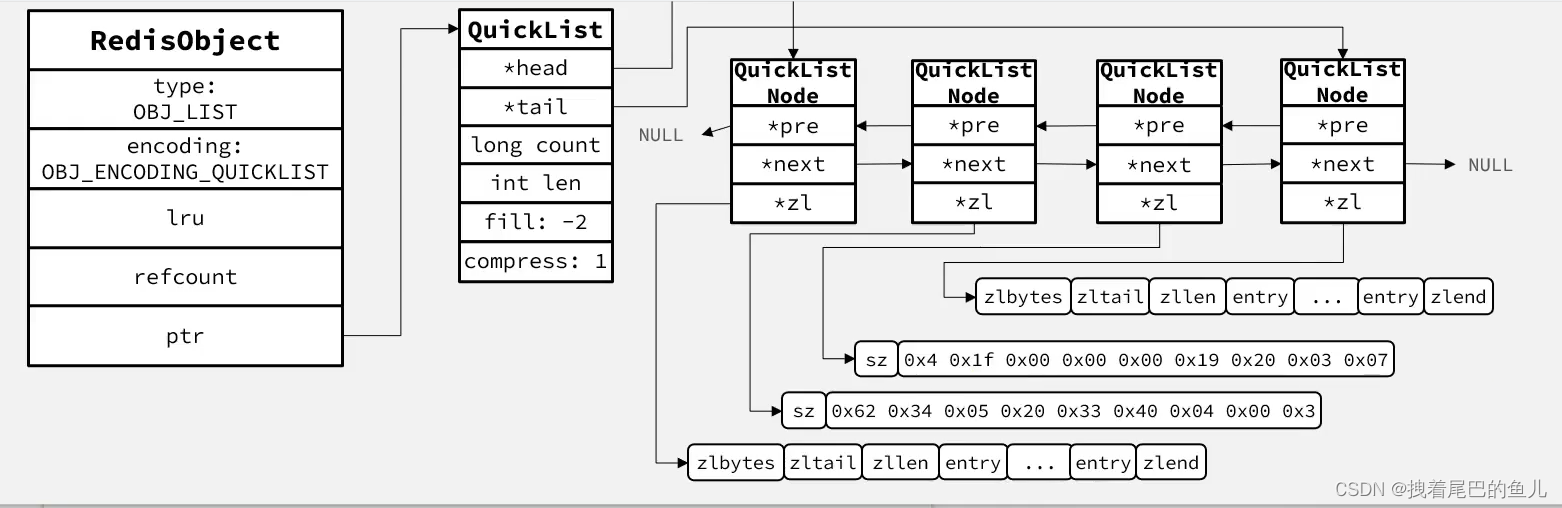
可以看到 redisobjec 内部使用 quicklist 进行存储,而quicklist 链表内部又使用了zipList;
三、set类型:
3.1 set 数据特点:
set 数据类型,需要保证存入元素的唯一性,可以不要求其有序性:
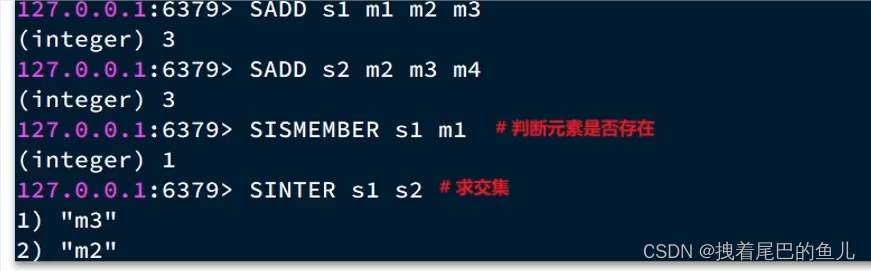
怎么保证以上特点的前提下,实现高速的查询?
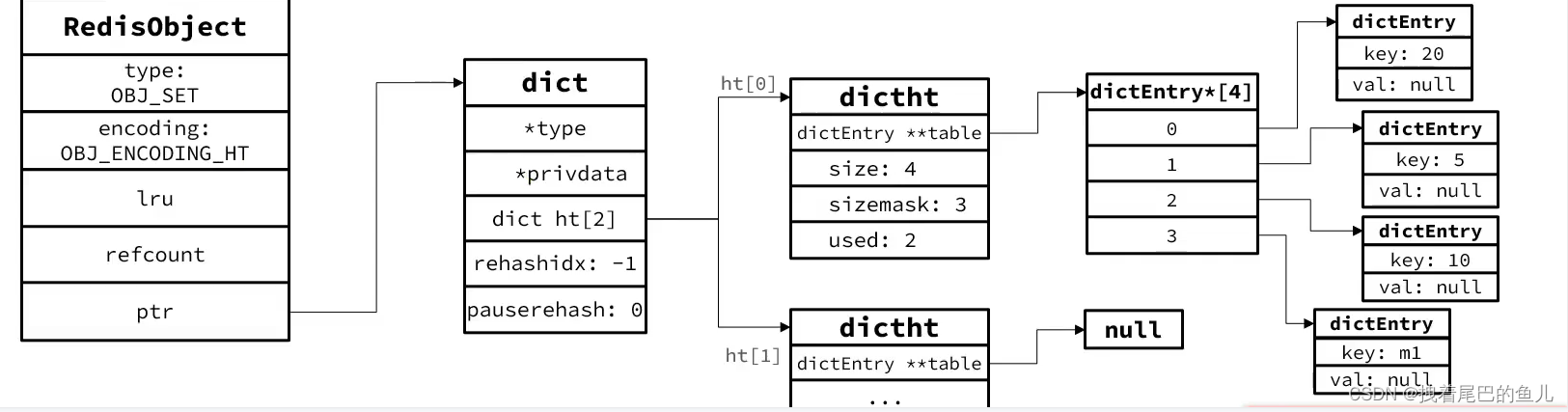
hash(dict) 通过key 定位数组下标,快速定位; 采用dict 编码,dict 的key 来存储元素,value 统一为null;
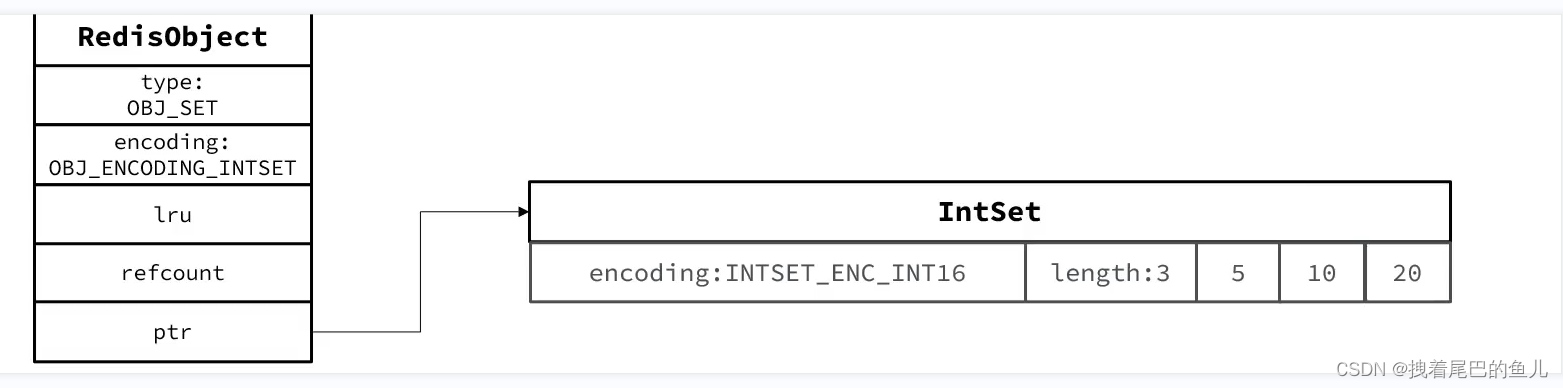
当存储的所有数据都是整数,并且元素数量不超过 set-max-inset-entries (默认值512 )时 set 使用inset 编码,节省内存,当超过set-max-inset-entries 时 是用dict 编码;
3.2 set 底层源码实现:
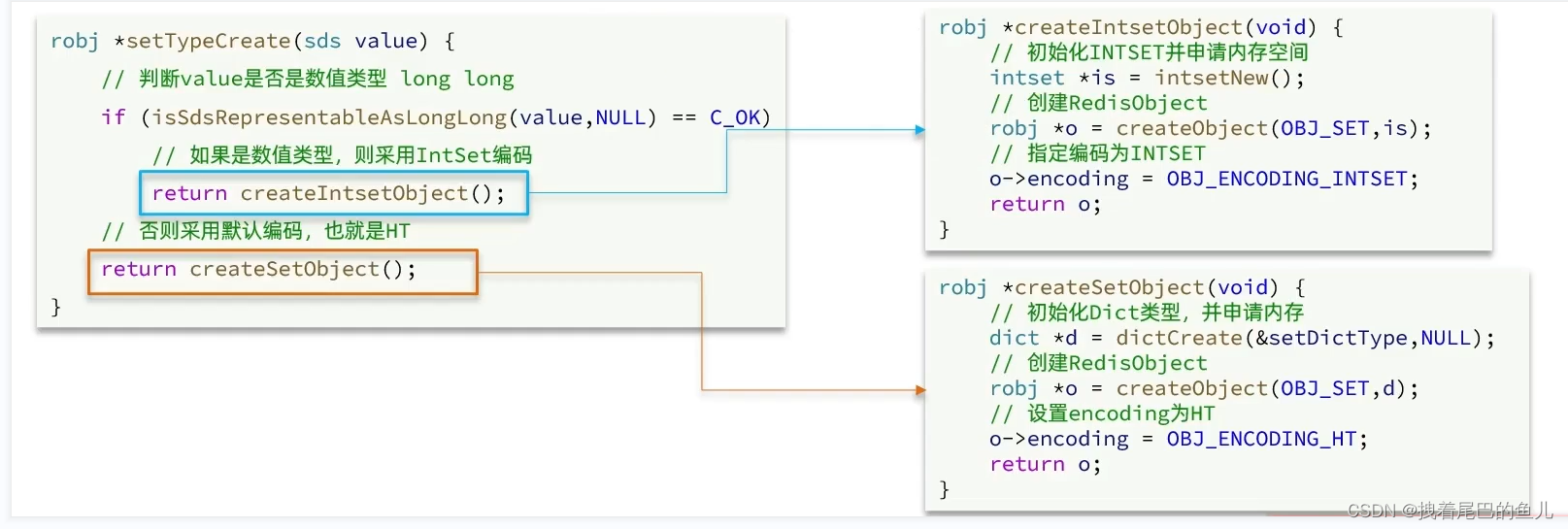
可以看到每次在掺入是,如果发现插入的是数字类型则先使用 intset 编码,如果不是数字类型则使用dict;
inset 编码数据结构:
dict 编码数据结构:
因为set 底层使用了两种编码inset 和dict ,所以也是会存在 编码的转换的,当每次插入的都是整数,并且集合中的元素不超过 set-max-inset-entries(设置的最大值不能超过 2^30 如果超过则直接取2^30,默认值512 ) 则使用dict ,一旦不满足则会转换为dict;
四、zset类型:
4.1 zset类型特点:
zset数据类型需要保证 元素唯一性的前提下,还要保证其有序性;

可排序的集合,每个元素都要指定一个score 值和member 值;可以根据score 信息排序;member 必须唯一,重复插入后插入覆盖之前插入的元素;根据member 查询分数:
对于以上的特点现有的任何一种单独的数据类型都不支持,所以此时就需要考虑组合类型了,使用skiplist 和 dict 结合的方式,使用skiplist 来支持排序,使用dict 存k-v的存储;
4.2 zset源码实现:
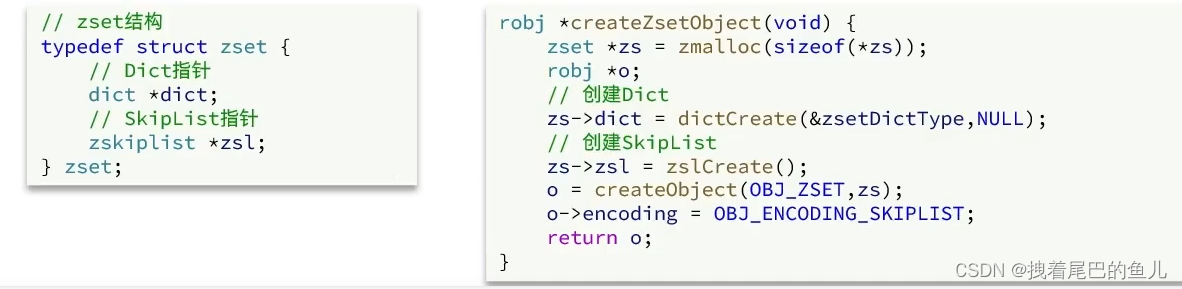
- skipList: 可以排序,并且可以同时存储score和ele值 (member);
- HT(Dict):可以键值存储,并且可以根据kev找value;
4.3 zset结构展示:
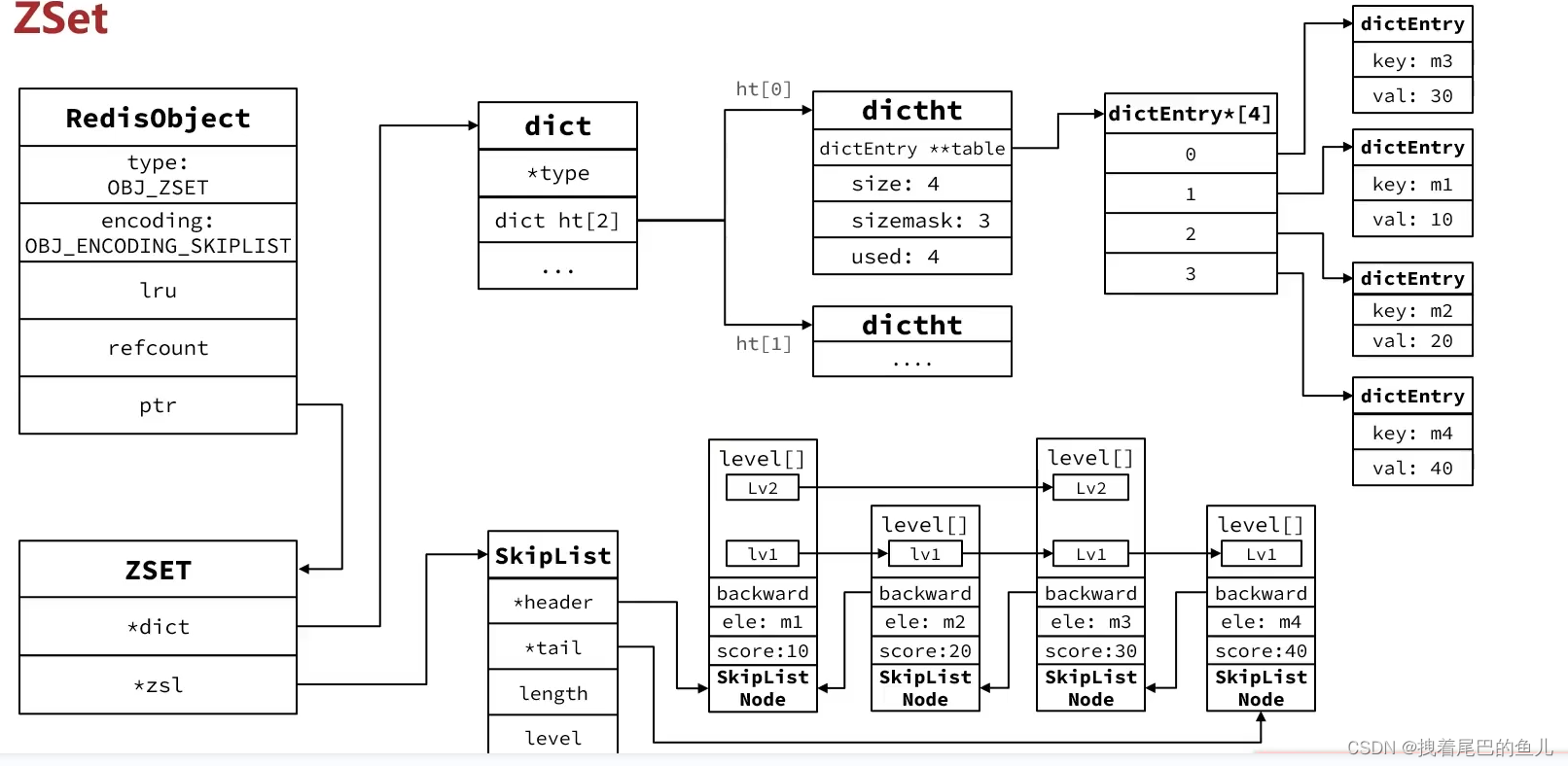
此种结构功能强大,性能非常好技能支持排序又能支持根据key 找value 但是内存占用很大;所以redis 并不是一开始就直接使用这种组合结构,;当元素数量少时 使用zipList 来进行存储;
使用zipList 存储的条件:
- 元素数量小于zset max ziplist entries,默认值128
- 每个元素都小于zset max ziplist value字节,默认值64
zset 初始化:先判断元素数量和插入元素大小,如果不满足则适应 dict + skiplist 编码,否则使用ziplist:

这里就设计到了编码转换,如果最开始是ziplist 但是随着元素数量的增加 元素数量和插入元素大小 超过128 活元素大小超过64;则进行编码转换:

ziplist本身没有排序功能,而且没有键值对的概念 它是怎么做到,key 唯一,并且可以排序:答案是使用业务代码进行支持:
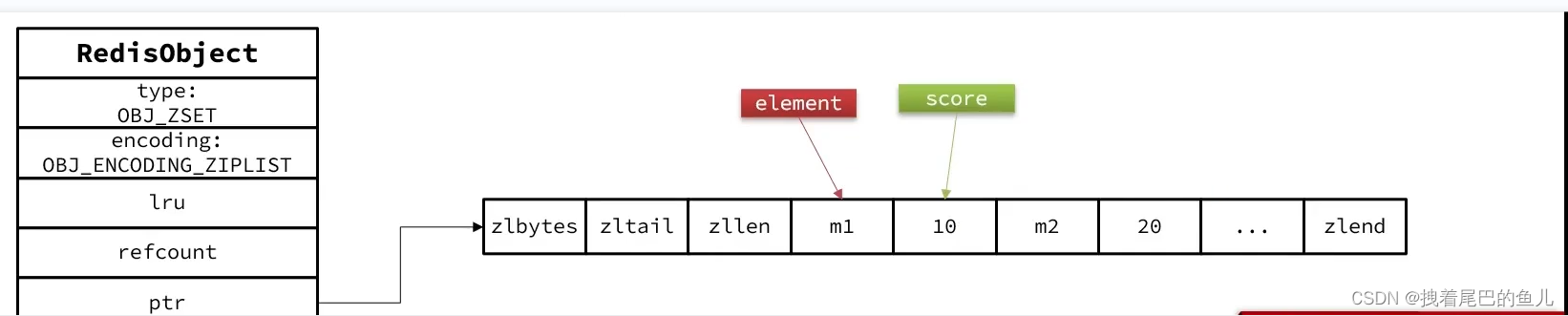
ZipList是连续内存,因此score和element是紧挨在一起的两个entry,element在前,score在后,score越小越接近队首,score越大越接近队尾,按照score值升序排列;在通过key 查找是因为元素较少直接进行遍历查找;
五、hash类型:
5.1 hash 数据特点:
hash 数据的 键值key 是 唯一的,可以根据key 获取到value 值;
5.2 hash 数据结构的实现:
当元素较少时 使用zipList 编码,节省内存,ziplist 相邻的entry 分别 保持field 和 value:
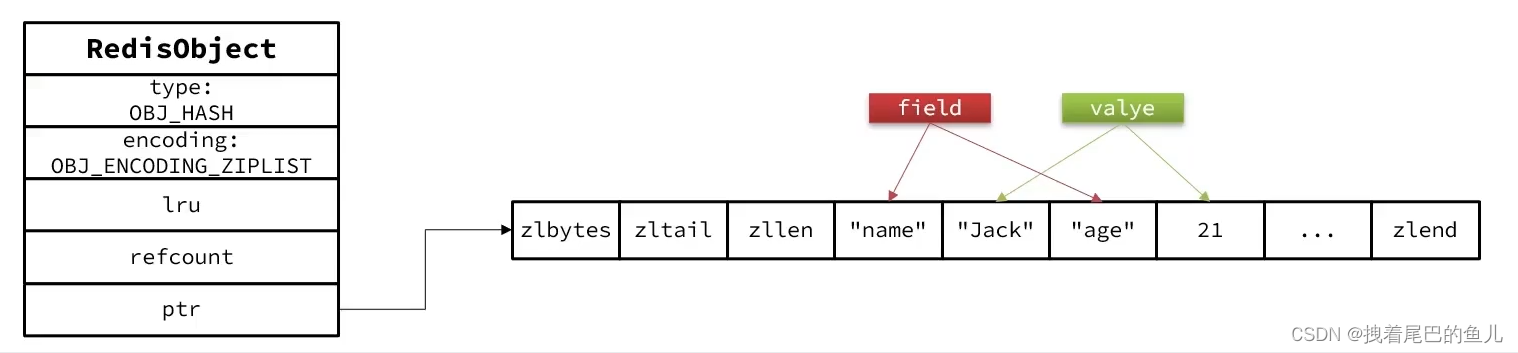
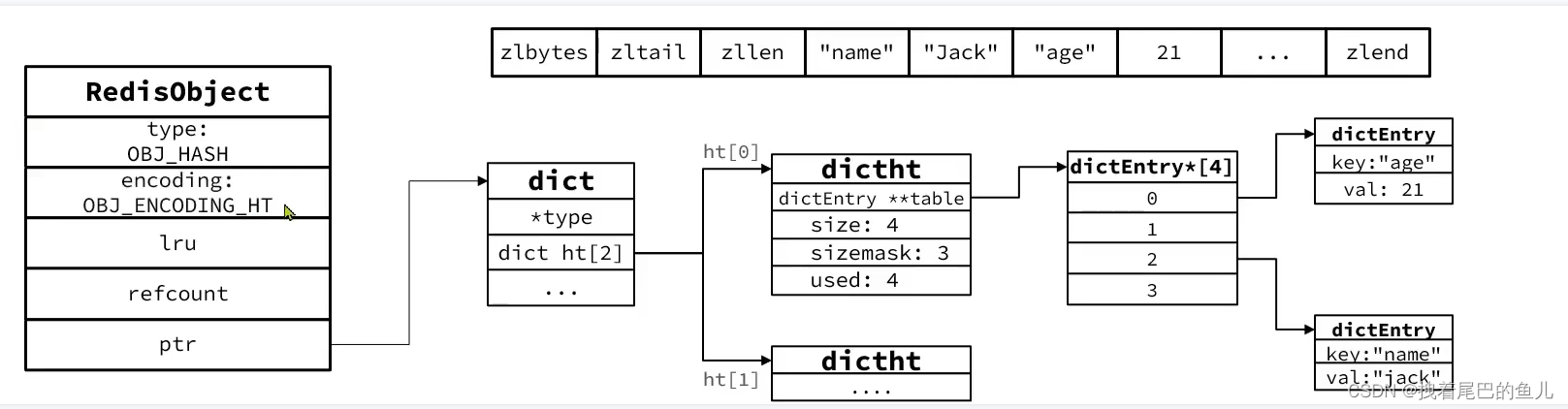
当超过一定的条件:当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了hash-max-ziplist-entries (默认512)
- ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
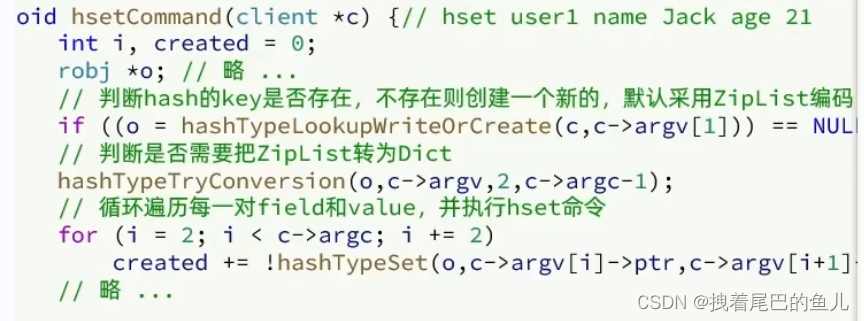
5.3 hash源码实现:
- 先根据key : user1 判断可以是否存在,不存在则创建一个新的与key 对应的ziplist :

- 判断ziplist 的元素个数,和每个元素的大小,来判断是否需要转换 dict;
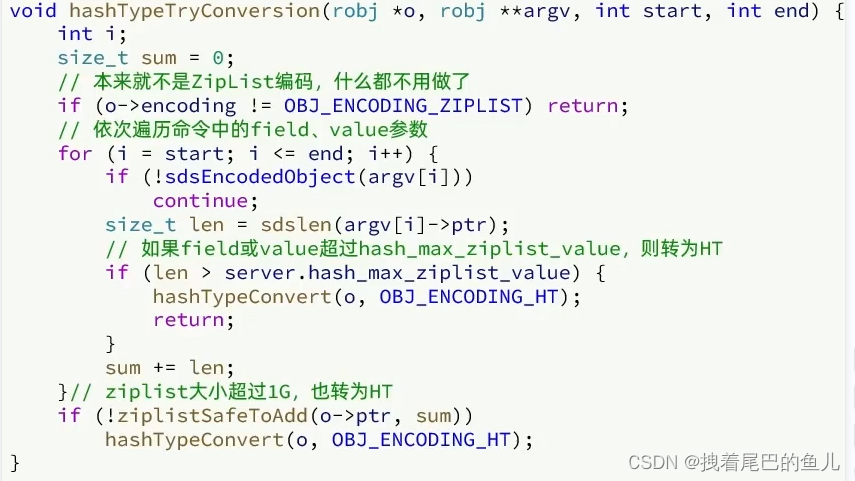
- for 循环 遍历将对应改key 的 filed 和value 进行设置;

六、Redis 数据中key和value 的对应:
6.1 redisObject key 和value 的对应:
我们知道 redis 内部 会将key 以及value 封装成为一个对应的 redisobject 对象,那么它们直接是怎么关联的,它怎么知道某一个key 对应到对应的value 值;
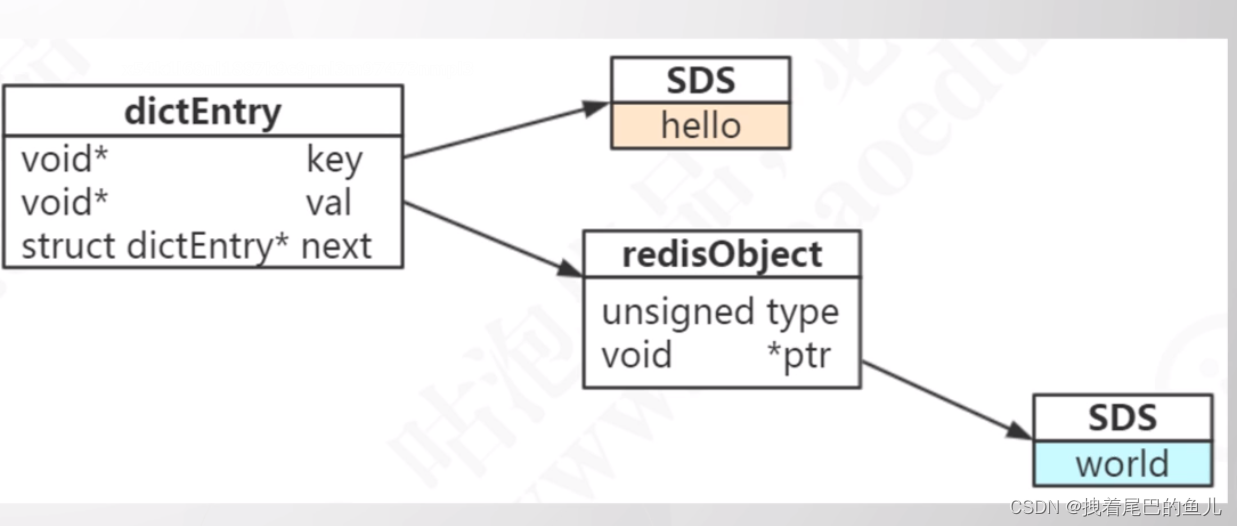
在Redis中,key和value是通过哈希表进行关联的。每个哈希表都有一个键值对,其中key是唯一的,并且与对应的value相关联。
当我们执行例如SET命令来设置一个key和value时,Redis会将key和value都封装为RedisObject对象,并将它们插入到相应的哈希表中。通过哈希函数,Redis能够根据key计算出一个哈希值,然后将其映射到一个槽位上。
Redis内部会维护一个哈希表数组,每个槽位上都有一个链表,链表上存储了具有相同哈希值的键值对。当插入一个新的键值对时,Redis会根据哈希值找到对应的槽位,然后将该键值对插入到链表的头部。这样,通过哈希表的索引结构,Redis能够快速定位到指定key的value。
当我们执行例如GET命令来获取一个key对应的value时,Redis会根据key计算出哈希值,并在对应的槽位上的链表中顺序查找,找到匹配的键值对后返回对应的value。
通过哈希表的索引结构,Redis能够高效地关联和查找key和value的对应关系。这种设计使得Redis在大规模数据集情况下也能保持很好的性能表现。
6.2 不同数据的对应:
- 对于key 和value 都是字符串来说,value 对应的redisobject 内部使用sds 来进行数据存储;
- List和Set类型的数据结构都是通过哈希表进行关联的,类似于字符串类型的键值对关系。不同之处在于,List和Set的value是一个有序(List)或无序(Set)的集合。
- 对于has 类型数据结构key 和value 也是通过哈希表进行关联的,只不过value 对应的redisobject 内部使用 zipList 或者dict 进行存储;在进行hash 存储时 hset user:1 name Jack age 21 ,它 的key filed 和value 对应如下
Key: “user:1”
Field 1: “name”
Value 1: “Jack”
Field 2: “age”
Value 2: 21 - 对于zset 类型数据结构key 和value 也是通过哈希表进行关联的,只不过value 对应的redisobject 内部使用 zipList / siplist + dict 实现;
总结
Redis 会根据不同数据类型底层采用不同的 数据结构进行保存,对于key 和value 来说,都会被封装成为一个redisobject 对象,key 是一个字符串的redisobject 对象其内部主要通过sds 实现,value 会根据存储的数据不同而在redisobject 对象内部 使用hash/ziplist/quicklist/sds/skiplist 进行实现;而 key 和value 的对应关系 可以通过哈希表进行关联的,每次都对key 做hash 计算从而得到 hash 槽位的下标进而找到 对应的value 链表;





















![[docker] Docker的数据卷、数据卷容器,容器互联](https://img-blog.csdnimg.cn/direct/bae83321c9d6445eb4382afbc47c2b88.png)


![[Go]认识Beego框架](https://img-blog.csdnimg.cn/direct/131e995daf374bb18b5c5347b4a07d26.jpeg#pic_center)





![前端[新手引导动画]效果:intro.js](https://img-blog.csdnimg.cn/direct/dc667f64cef048358d6736642e1dfdc5.png)