目录

前言
随着网络数据的爆炸式增长,爬虫成为了获取和处理数据的重要工具。而Python,作为一门灵活且易于上手的编程语言,拥有众多高效的爬虫框架,使得我们能够更加高效地进行数据抓取和处理。
本文将介绍几个常用的高效Python爬虫框架:Scrapy、Beautiful Soup和Requests库。这些框架各自有其独特的特点和使用场景,能够满足不同类型的爬虫需求。
一、Scrapy框架
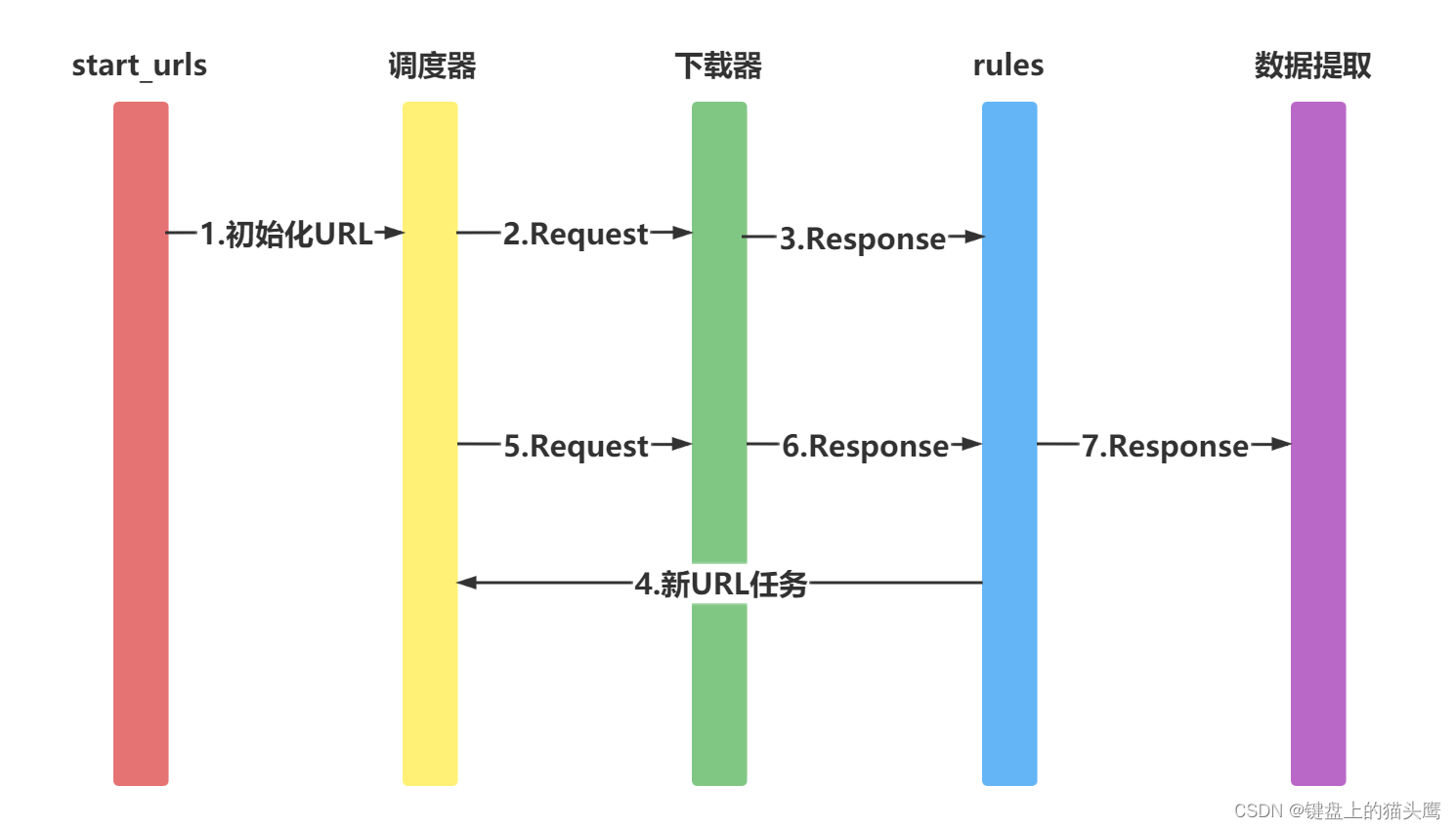
Scrapy是一个功能强大的Python爬虫框架,被广泛用于大规模数据抓取。它具有高度可配置性和可扩展性,并且提供了一整套用于处理数据的工具和组件。
1. 安装Scrapy
在命令行中使用pip工具安装Scrapy:
pip install scrapy2. Scrapy示例代码
下面是一个使用Scrapy框架编写的简单爬虫示例,在终端中运行该代码将会抓取指定网站的标题和链接:
import scrapy
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = [
"http://example.com",
]
def parse(self, response):
for title in response.css('h1::text'):
yield {
'title': title.get(),
'link': response.url,
}
for next_page in response.css('a::attr(href)'):
yield response.follow(next_page, self.parse)3. 运行Scrapy爬虫
在命令行中运行以下命令来启动Scrapy爬虫:
scrapy runspider myspider.py -o output.json上述命令将会将抓取到的数据保存到`output.json`文件中。
二、Beautiful Soup库
Beautiful Soup是一个用于解析HTML和XML文档的Python库,它提供了简单且灵活的方式来提取和处理数据。
1. 安装Beautiful Soup
在命令行中使用pip工具安装Beautiful Soup:
pip install beautifulsoup42. Beautiful Soup示例代码
下面是一个使用Beautiful Soup库编写的简单爬虫示例,它将抓取指定网页的所有标题和链接:
from bs4 import BeautifulSoup
import requests
url = "http://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for title in soup.find_all('h1'):
print(title.text)
print(title.a['href'])3. 运行Beautiful Soup代码
在命令行中运行以上代码,你将能够看到抓取到的标题和链接的输出结果。
三、Requests库
Requests是一个简单且优雅的Python库,用于发送HTTP请求和处理响应。它是使用Python进行网络抓取和数据处理的重要工具。
1. 安装Requests库
在命令行中使用pip工具安装Requests库:
pip install requests2. Requests示例代码
下面是一个使用Requests库编写的简单爬虫示例,它将抓取指定网页的所有标题和链接:
import requests
from bs4 import BeautifulSoup
url = "http://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for title in soup.find_all('h1'):
print(title.text)
print(title.a['href'])3. 运行Requests代码
在命令行中运行以上代码,你将能够看到抓取到的标题和链接的输出结果。
总结
本文介绍了几个常用的高效Python爬虫框架:Scrapy、Beautiful Soup和Requests库。这些框架各具特色,能够满足不同类型的爬虫需求。
使用Scrapy框架可以实现大规模数据抓取,并且具有高度可配置性和可扩展性。此外,Beautiful Soup库提供了简单灵活的方式来解析HTML和XML文档,并提取所需的数据。而使用Requests库可以方便地发送HTTP请求和处理响应。
根据实际需求选择合适的框架,并结合示例代码,读者能够快速入门和使用这些框架,从而进行高效的Python爬虫开发。