多元信息
1.遗传算法的运算步骤中包含选择运算、( B )运算、变异运算。
A.遗传运算 B.交叉运算 C.乘法运算 D.数乘运算
2.遗传算法的算子不包括:( B )
A.选择 B.进化C.交叉 D.变异
5、模糊集合的两要素是论域和(B)B:隶属函数
多源遥感影像数据融合的主要优点是(B)。可以充分发挥各种传感器影像自身的特点
基于规则的融合方法包括多种组合多模态信息的基本规则。如果不同模态之间具有较好的( B ),那么基于规则的融合方法通常能取得较好的表现效果
D-S理论中,可信度和似真度都不能囊括的区间用来表示 所有反对假设的证据的总和
EM算法中包含哪些数据(C)C.隐含变量
基于估计的融合方法不包括 D隐马尔可夫模型
基于分类的融合方法不包括: 拓展卡尔曼滤波器
模糊集的运算不包括 、加法运算
线性支持向量机分类方法不包括 B、最邻近分类
线性加权融合是一种最简单、应用最广泛 基于规则的融合方法
支持向量机是一种(B)B.基于分类的融合方法
图像融合的层次不包括 数据级融合
不属于变换域融合方法的是 B.线性加权融合
以下选项哪个不是证据理论的主要特点 C.基于贝叶斯法则
隶属函数具有主观性,来源于个人感受和表达抽象概念上的差异 B、模糊性
多模态数据融合传统方法中不是基于估计的方法是(D) D.线性加权融合
卡尔曼滤波器允许对(A)数据进行实时处理 动态
基于分类的融合方法不包括 线性加权融合
. 多模态数据融合技术的应用不包括(C) 多模态搜索引擎
多模态数据融合的方式不包括 前期融合
00 “开”门大吉
判断题:
1.遗传算法模拟了自然界中的生物进化过程适用于解决全局优化的问题。 (正确)
2.异构融合处理的数据通常具有更强的多样性和互补性,但相比同构数据融合,异构融合也需解决数据配准,归一化等新的问题。 (正确)
3.遗传算法是模仿达尔文进化论的自然选择和遗传学机理的计算模型。 ( 正确 )
4.遗传算法的构成要素没有个体适应度评价(错误)
5.遗传算法一些主要应用领域为函数优化和组合优化(正确)
6、蚂蚁算法可以用来求最优解(对)
7、加权平均图像融合需要像素大小一致(对)
8、模糊集的表示方式中,若论域是连续的,模糊集也不可以用实函数表示。(错)
9. 线性加权融合方法是一种简单的融合方法,在适当地确定不同模态的权重时,该方法表现良好,但也是使用该方法的一个主要问题(对)
10. 贝叶斯推理允许使用主观概率,这些主观概率包括假设事件发生的先验概率,以及在假设事件发生的条件下出现证据的概率(对)
11.卡尔曼滤波算法与蚂蚁算法的区别是蚂蚁算法可以找到全局最优解,卡尔曼滤波算出来的是误差最小解(✓)
12.卡尔曼滤波算法是一种时间域滤波方法,采用状态空间描述系统(✓)
13.粗糙集理论可以解决所有含糊的、模糊的不确定性问题。(×)
14.一个概念越粗糙,其分类能力越差,分类得到的对象组的颗粒越大(越粗),对象之间的可辨识性越差。相反地,一个概念越精细,其分类能力越强,分类所得的对象组的颗粒越小,对象之间的可辨识性越好。( √ )
15. 粗糙集理论的主要优势就在于它不需要关于数据的任何预备的或额外的信息。(√)
16.模糊理论中,隶属度为1的元素的集合称为核。 (√)
17.模糊理论中,隶属度不为0的元素的集合称为支集。 (√)
18.D-S推理系统是基于“识别框架”的基本概念的,该框架包含着一个具有所有可能的相互排斥的假设的集合Θ。 (√)
19.一般而言,线性加权融合要经历两个步骤:分数标准化和分数加权。 (√)
20.证据理论要求证据来源必须是独立的。 (√)
21. 最大熵模型学习最终都归结为以似然函数为目标函数的最优化问题(对)
22. 最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。(对)
23.基于概率原理的贝叶斯推断融合方法提供了对新观测的简单集成和先验信息的使用。但是它们不适合处理相互排斥的假设。(✓)
24. 贝叶斯推断中,朴素贝叶斯最核心的假设是局部独立性假设(对)
25. D-S证据法主要应用于不确定性信息的融合(对)
26. 高斯金字塔的组成元素是通过高斯平滑以及向下采样依次对图像处理得到的(对)
27. EM的数学推理涉及到贝叶斯,最大似然估计等概率公式,是一种有效的迭代算法。(√)
28. EM算法可用于解决存在隐含变量的优化问题(√)
29.贝叶斯推理属于统计融合算法。(正确)
30.粒子群优化算法中,个体认知分量表示粒子本身的思考,它是在对粒子现有的位置和群体经历过的最优位置进行比较后得到的(错误 )
31.粒子群优化算法将每个个体看作n维搜索空间中一个没有体积质量的粒子,在搜索空间中以一定的速度飞行(正确 )
32.模糊现象与随机现象没有区别(错误 )
33.SVM机器学习模型能执行线性或非线性分类任务,从多模态融合角度,可用于解决模式分类问题(正确)
34、动态贝叶斯网络被广泛应用于处理时间序列数据(√)
35卡尔曼滤波器不需要保存观测历史,只依赖于前一时间戳的状态估计数据(√)
36.用模糊集合能够比较准确地、真实地描述人们头脑中的原有概念。(√)
37. 多模态融合是通过联合多个模态的信息,进行目标预测(分类或回归)任务。(√)
38. 贝叶斯推断方法根据概率论的规则对多模态信息进行组合,既可以应用于早期融合,也可以应用于后期融合。(√)
39.从多模态融合的角度,支持向量机用于解决模式分类问题。(√)
40.支持向量机通过非线性映射把数据从低维空间向高维空间映射,在高维空间为低维空间数据构造线性分离超平面(对)
41.贝叶斯推理允许使用主观概率,因此不需要各传感器的概率密度函数(对)
42.贝叶斯推断方法根据概率论的规则对多模态信息进行组合。(对)
43:今天天气很热是模糊现象(✔)
44:贝叶斯网络对丢失数据有很好的鲁棒性,可以很好融合信息(√)
45:贝叶斯网络是无向有环图,它用来表示变量间依赖关系的概率图模型。(x)
46.图像融合技术目前已经在机器智能,安全防范等领域获得日益广泛的应用。(√)
47.加权平均法是一种常见的图像融合方法。(√)
48.不确定性分为随机性、模糊性和认识不确定性三种。(√)
49.图像融合的层次分为像素级融合、特征级融合和决策级融合三种。(√)
50.多模态学习可以应用于语音识别和生成、图像识别、事件监测、情感分析等方面。(√)
51、数据融合的目的是:一致性解释与描述,获取更为充分的信息。(√)
52、异构多模态数据是由不同的媒介产生的模态数据,包括文字、图像、照片、声音、动画和影片。(√)
53、下雨与不下雨,是随机现象,事件发生存在一定的概率;下雨的大小,如小雨、小到中雨、中到大雨、大到暴雨等是模糊现象,概念没有明确的外延。(√)
54.支持向量机是一个功能强大并且全面的机器学习模型,它能够执行线性或非线性分类、回归等任务。答案:正确
55、信息融合只适用于图像的融合,对于数据集的融合却不适用(×)
56、信息融合一般分为4个阶段,分别是:信息源收集整理阶段、信息源处理阶段、分析决策阶段和融合结论输出阶段。(✓ )
57、线性加权融合是一种最简单、应用最广泛的融合方法。在该方法中,从不同的模态中得到的信息是通过线性的方式进行组合的。这些信息可以是底层视频特征,也可以是高层语义级决策。(正确)
58. 贝叶斯融合在应用时不需要先验概率。(x)
59. 神经网络的实现是基于数据的,最终的规则对用户是不透明的。(x)
60. 支持向量机不能解决异或问题。(x)
61. 模糊集合理论:用“隶属度”来表示 “非此即彼”的关系。(x)
62. 数据融合处理不能弥补数据处理过程中造成的信息损失。(√)
63. 多传感器数据融合结果能够代替单一高精度传感器测量结果。(x)
64. 图像融合的前提是图像的像素点数目必须相同。(√)
1.人类识别咖啡的过
视觉:
触觉:
人类识别咖啡的过程,用眼睛、鼻子和舌头来获取观察对象的信息,分别用来看对象的颜色、闻气味、尝味道。对这三种信息分别进行分析与判别,最后综合这几种信息,对观察对象进行分析判断
2. 数据融合的目的
对多源知识和多个传感器所获得的信息进行综合处理,消除多传感器信息之间可能存在的冗余和矛盾,利用信息互补来降低不确定性,以形成对系统环境相对完整一致的理解,从而提高系统智能规划和决策的科学性、反应的快速性和正确性,进而降低决策风险。
(1)随着系统的复杂性日益提高,依靠单个传感器对物理量进行监测显然限制颇多。
(2)因此在故障诊断系统中使用多传感器技术进行多种特征量的监测(如振动、温度、压力、流量等),并对这些传感器的信息进行融合,以提高故障定位的准确性和可靠性。
(3)通过信息融合将多个传感器检测的信息与人工观测事实进行科学、合理的综合处理,可以提高状态监测和故障诊断智能化程度。
(4)另外,现在战略监测和自主武器系统的性能及部署速度都要求开发全新的数据处理技术。现代战争威胁的多样化和复杂化导致对传统数据和信号处理系统提出了更高的要求。
(5)因此必须从大量的可移动的和活动的传感器台站收集数据并加以融合,将人工方法不能进行检测的和提出的微弱信号进行多元信息融合处理。
3. 数据融合的定义
技术定义:充分利用不同时间与空间的多传感器数据资源,采用计算机技术按时间序 列获得多传感器的观测数据,在一定准则下进行分析、综合、支配和使用。获得对被 测对象的一致性解释与描述,进而实现相应的决策和估计,使系统获得比它各组成部 分更为充分的信息。
该定义的重点:方法:分析、综合、支配、使用; 目的:一致性解释与描述、更为充分的信息。
人是一个最复杂的且自适应性极强的信息融合系统。人身上有许多功能不同的传感器。实际上,人的眼睛、耳朵、鼻子、 舌头和四肢,就是视觉、听觉、嗅觉、味觉和触觉传感器。
①从军事应用的角度看,多传感器数据融合可以这样来定义: 所谓多传感器数据融合就是人们通过对空间分布的多源信息——各种传感器的时空采样,对所关心的目标进行检测、 关联(相关)、跟踪、估计和综合等多级多功能处理,以更高的精度、较高的概率或置信度得到人们所需要的目标状态和身份估计,以及完整、及时的态势和威胁评估,为指挥员提供有用的决策信息。
②功能定义: 将来自多个信息源的数据进行相关、整合,以获得目标精确的位置、身份,最后对目标进行完整精确的评价
该定义的重点: 多个传感器对同一目标进行测量 重点是融合:相关、整合 目的:状态、身份、威胁估计等
4.多模态数据融合
(1)模态:不同形式、不同来源的数据。
模态与数据产生的方式息息相关,
不同模态的数据具有不同的接收方式。
模态是指信息接收的特定方式。
(2)异构多模态数据:由不同的媒介产生的模态数据,包括文字、图像、照片、声音、动画和影片。
(3)异源多模态数据:来自不同传感器的同一类媒介产生的数据。
(4)多模态数据融合:利用计算机技术对多模态信息进行综合处理。主要思想是对不同种类的多模态数据进行集成整合,联合学习各模态数据的存在共享信息,以获取对客观物体的状态与环境信息更为准确的描述与判断,进而提升对事物表达的精确性。
7. 经典证据理论基本概念
设θ/D是一个识别框架,或称样本空间(假设空间)。
设 D是变量 x所有可能取值的集合,且 D中的元素是互斥的,在任一时刻 x都取且只能取 D中的某一个元素为值,则称 D为 x的样本空间。D的任何一个子集A都对应于一个关于x的命题,称该命题为”x的值是在 A中”。
举例①:
x:击中的环数
D={6,7,89,10}
A={6}:“x是6”或“击中6环”
A={6,7,8}:“击中的环数是6,7,8中的一个”
举例②:
x:信号灯的颜色
D={红,黄,绿}
A={红}:“ x是红色”
A={红,黄):“x或者是红色,或者是黄色”
8. m(A)、Bel(A) 和Pl(A)的意义
(1)m(A)反映了对A本身的信任度大小
(2)Bel(A)是分配到A上的总信任度
支持度:传感器直接分配给该命题证据所对应的概率分配值的和。这里传感器直接分配给该命题的证据是指,该命题及组成该命题的子命题的某些并命题的集合,这些并命题是指被传感器赋予一定概率分配值的并命题。
(3)Pl(A)是所有与A相容的命题本身的信任度之和
似然度:所有没有分配给这个命题的反命题的概率分配值的和。换句话说,一个命题的似然度等于只要能在某方面支持该命题的所有概率分配值的和。
(4)不确定区间:以支持度为下界,似然度为上界,构成的区间称为不确定区间,也称信任区间。
0-Bel:支持区间
Bel-Pl:信任区间
PL-1:拒绝区间
6.贝叶斯推理适用于:
先验知识了解充分且证据信息获取充分时的信息融合,例如,掷均匀骰子,
根据不同来源的信息,推测掷出的点数;
7.证据理论适用于:
当知识了解不充分,或证据获取不充分时,即对识别框架里各命题的先验概
率存在由不知道而引起的不确定时,对于不确定信息的融合,例如,掷不均
匀的骰子,不同点数出现的概率未知,根据不同来源的信息,推测掷出的点
数
8. 模糊理论适用于:
外延不分明的概念,即模糊概念的信息融合,例如,对于“年轻”、“年
老”的不同来源的信息融合。
9.深度学习核心思想:表示学习/特征学习;非线性函数逼近;端到端学习
9.Dempster合成规则
例设 D = {黑,白},且设
M1({黑},{白},{黑,白},Φ) = (0.3,0.5,0.2,0)
M2({黑},{白},{黑,白},Φ) = (0.6,0.3,0.1,0)
则:
K = 1 -∑x∩y=ΦM1(x)M2(y)=0.61
M({黑}) = K-1∑x∩y={黑} M1(x)M2(y)
= 1/0.61 [M1({黑})M2({黑})+M1({黑})M2({黑,白})+M1({黑,白})M2({黑})]
= 1/0.61 [0.3*0.6+0.3*0.1+0.2*0.6]
= 0.54
同理可得M(白})=0.43, M({黑,白})=0.03
组合后得到的概率分配函数:
M({黑},{白},{黑,白},Φ) = (0.54,0.43,0.03,0)
10.抢劫案例子-Dempster合成规则
发生抢劫案,警方判定罪犯肯定是嫌疑人A、B、C中的一个,但不知道是哪一个。两个证人张三、李四只是看到了部分过程,有不同的判断,用概率表示。共三种情况:A作案,B作案,C是作案,具体如下:
_______________________________
假设 张三认为 李四认为
A作案 0.86 0.02
B作案 0.13 0.90
C作案 0.01 0.08
_______________________________
(1)计算归一化常数K。
K = ∑B∩C≠∅ m1(B)·m2(C)
= m1(A)m2(A) + m1(B)m2(B) + m1(C)m2(C)
= 0.86*0.02 + 0.13*0.9 + 0.01*0.08
= 0.0172 + 0.117 + 0.0008
= 0.135
(2) 利用Dempster合成规则计算。
m1⊕m2(A)= ∑B∩C={A} m1(B)·m2(C)/k
=1/K*m1(A)m2(A)
=0.86*0.02/0.135
=0.12740741
同理计算:
m1⊕m2(B) = 0.13*0.9/0.135 = 0.866666
m1⊕m2(C) = 0.01*0.08/0.135 = 0.00592593
_______________________________________________
假设 张三认为 李四认为 DS融合
A作案 0.86 0.02 0.12740741
B作案 0.13 0.90 0.866666
C作案 0.01 0.08 0.00592593
_______________________________________________
则用D-S融合的最终结果如下,B作案的可能性很大达到0.86666
11.基于DS理论的信息融合计算举例-Dempster合成规则
假设在2001年美国发生“911事件”之前,布什总统分别接到美国中央情报局(CIA)和国家安全局(NSA)两大情报机构发来的绝密情报,其内容是关于中东地区的某些国家或组织企图对美国实施突然的恐怖袭击。CIA和NSA得到的证据如表1所示。
试计算并回答下列问题:
请直接利用Dempster证据合成公式计算表1中的所有“?”内容。
恐怖分子\情报部门 中央情报局(CIA) 国家安全局(NSA) 布什政府根据DS理论计算后的结果
{本·拉登}(简称“本”) 0.40 0.20
{萨达姆}(简称“萨”) 0.30 0.20
{霍梅尼}(简称“霍”) 0.10 0.05
{本·拉登,萨达姆} 0.10 0.50
θ = {本, 萨, 霍} 0.10 0.05
(1)首先,计算归一化常数K。
K = ∑B∩C≠∅ m1(B)·m2(C)
= 1-[m1({本})m2({萨}) + m1({本})m2({霍}) +…+ m1({本,萨})m2({霍})]
= 1 – (0.4*0.2+0.4*0.05+…+0.1*0.05)
= 1 - 0.27
= 0.73
(2)计算关于本拉登(“本”)的组合mass函数
(3)同理可得:
m1⊕m2({本})= 1/k * ∑B∩C={本} m1(B)·m2(C)
=1/K * [m1({本}) * m2({本}) + m1({本}) * m2({本,萨})
+ m1({本,萨})·m2({本}) + m1({本}) * m2({θ}) + m1({θ}) * m2({本})]
= 1/0.73 (0.4*0.2+0.4*0.5+0.1*0.2+0.4*0.05+0.1*0.2)
= 1/0.73 (0.08 + 0.2 + 0.02 + 0.02 + 0.02)
= 0.4658
m1⊕m2({萨}) = 1/k * ∑B∩C={萨} m1(B)·m2(C)
= 1/0.73 (0.3×0.2+0.3×0.5+0.2×0.1+0.3×0.05+0.2×0.1)
= 1/0.73 (0.06+0.15+0.02+0.015+0.02)
=0.363
m1⊕m2({霍}) = 1/k * ∑B∩C={霍} m1(B)·m2(C)
= 1/0.73 (0.1×0.05+0.1×0.05+0.1×0.05)
= 1/0.73 (0.005+0.005+0.005)
= 0.0205
m1⊕m2(∵) = 1/k * ∑B∩C=∵ m1(B)·m2(C)
= 1/K [m1(∵)·m2(∵)]
= 1/0.73 (0.1*0.05)
= 1/0.73 * 0.005
= 0.0068
恐怖分子\情报部门 中央情报局(CIA) 国家安全局(NSA) 布什政府根据DS理论计算后的结果
{本·拉登}(简称“本”) 0.40 0.20 0.4658
{萨达姆}(简称“萨”) 0.30 0.20 0.3630
{霍梅尼}(简称“霍”) 0.10 0.05 0.0205
{本·拉登,萨达姆} 0.10 0.50 0.1438
θ = {本, 萨, 霍} 0.10 0.05 0.0068
12.不确定性分类
(1)贝叶斯推理适用于先验知识了解充分且证据信息获取充分时的信息融合,例如,掷均匀骰子,根据不同来源的信息,推测掷出的点数;
(2)证据理论适用于当知识了解不充分,或证据获取不充分时,即对识别框架里各命题的先验概率存在由不知道而引起的不确定时,对于不确定信息的融合,例如,掷不均匀的骰子,不同点数出现的概率未知,根据不同来源的信息,推测掷出的点数;
(3)模糊理论适用于外延不分明的概念,即模糊概念的信息融合,例如,对于“年轻”、“年老”的不同来源的信息融合。
不确定性可以分为随机性、模糊性和认识不确定性三种。
随机性:在自然界中客观存在,可根据历史资料得到的统计数字来描述,常用概率论和数理统计来解决这方面问题。
模糊性:通常指发生在概念上的模糊,如大、中、小界限的模糊等。模糊理论是处理此问题的有力工具。
认识的不确定性:是由于人们认识水平的局限以及知识缺乏所造成的。
随机性和模糊性是客观的不确定性,认识的不确定性是主观的不确定性。
三、深度学习及其在数据融合中的应用
13.深度学习的核心思想
(1)表示学习/特征学习
(2)非线性函数逼近
(3)端到端学习
14.机器学习 vs 深度学习
数据->特征:特征工程
特征->智慧:机器学习
数据->特征->智慧:深度学习
15. 机器学习 vs 深度学习之特征的重要性
机器学习:需要人工选取特征
深度学习:自动学习有用特征
16. 特征学习:图像识别为例
深度学习通过层次化的学习方式得到图像的特征,解决图像识别问题
输入层(像素)->隐层1(边缘)->隐层2(轮廓)->隐层3(物体部件)->输出层(物体类别)
非线性函数逼近
(1)深度学习通过一种深层网络结构,实现复杂函数逼近
(2)万能逼近原理: 当隐层节点数目足够多时,具有一个隐层的神经网络可以以任意精度逼近任意具有有限间断点的函数
(3)网络层数越多,需要的隐含节点数目指数减小
简单函数->复杂函数
复杂函数->简单函数
端到端学习
端到端学习:从原始输入直接学习到目标,中间的函数和参数都是可学习的
从输入端到输出端,中间的神经网络自成一体,这是端到端的
19.什么是图像融合
图像融合(Image Fusion)即是指将不同方式、不同设备、不同时间等摄取的同一景物的图像经过分析后,根据一定的准则加以合成,使得最终得到的图像能最大程度地利用各幅图像的互补信息,克服单个图像在光谱、空间分辨率、几何等诸多方面的缺陷,全面准确地反映被摄景物的实际情况,从而有利于对客观事物的准确定位、识别和理解。现在该项技术已在机器智能、安全防范、稽毒、安检等领域获得日益广泛的应用。
图像融合(Image Fusion)是用特定的算法将两幅或多幅图像综合成一幅新的图像。融合结果由于能利用两幅(或多幅) 图像在时空上的相关性及信息上的互补性,并使得融合后得到的图像对场景有更全面、清晰的描述,从而更有利于人眼的识别和机器的自动探测。
20. 图像融合的分类
(1)像素级融合:像素级图像融合首先对源图像进行预处理和空间配准,然后对处理后的图像采用适当的算法进行融合,得到融合图像并进行显示和相关后续处理。像索级融合最大限度地保留了源图像的信息,在多传感器图像融合三个层次中精度最高,同时它也是特征级和决策级融合的基础。像素级融合的缺点是处理的数据量较大、实时性差。
(2)特征级融合:特征级融合是一种中等水平的融合。特征级融合是先将各图像数据进行特征提取,产生特征矢量;然后对这些特征矢量进行融合;最后,利用融合特征矢量进行属性说明。其优点是实现了可观的信息压缩,有利于实时处理,并且提供的特征直接与决策分析相关;其缺点是精度比像素级融合差。
(3)决策级融合:决策级融合是一种高水平的融合。决策级融合首先对每一数据进行属性说明,然后对结果加以融合,得到目标或环境的融合属性说明。决策级融合的优点是具有良好的容错性和开放性,处理时间较短。
21.图像融合的基本流程
图像融合的主要步骤归纳如下:
(1)预处理:对获取的两种图像数据进行去噪、增强等处理,统一数据格式、图像大小和分辨率。对序列断层图像作三维重建和显示,根据目标特点建立数学模型。
(2)进行图像配准:使两幅待融合的图像对应点或对应区域在空间上对齐。
(3)融合图像创建:配准后的两种模式的图像在同一坐标系下将各自的有用信息融合,表达成一幅新的图像。
22. 图像融合方法
常见的融合规则:
(1)加权平均法
加权法是将两幅输入图像g1(ij)和g2(ij)各自乘上一个权系数,融合成新的图像F(i,j)。
F(i,j)=ag1(i,j)+(1-a)g2(i,j)
其中,a为权重因子,且0≤a≤1,可以根据需要调节a的大小。
该算法实现简单,其困难在于如何选择权重系数,才能达到最佳的视觉效果。
(2)RGB-IHS变换法
IHS变换首先将RGB颜色空间的三个波段的多光谱(TM)图像转化为IHS空间的三个量,然后将高空间分辨率(SPOT)图像进行对比度拉伸,使它和亮度分量I有相同的均值和方差,最后用拉伸后的高空间分辨率图像代替亮度分量I,把它同色度H和饱和度S进 IHS变换得到融合图像。
RGB ---IHS变换---> HIS ---Ip'代替I---> HIp'S ---IHS逆变换---> R'G'B' ---> 彩色合成
23.融合效果评价
图像融合实例
——不同小波,采用能量法:
(a) 可见光图像(b) 红外图像(c) Haar小波(d) W5/3小波(e)Daubechies9/7小波
图(a)为一幅花丛可见光图像,没有目标;图(b)是该场景的红外图像,一支隐藏的手枪(目标)清晰可见,融合的目的是提高图像的信息量。从图 (c),(d),(e)可以看到,融合后,目标和目标的背景都得到了很好的保留。
四、基于模糊集合论的信息融合技术
24.模糊数据融合在天然气瓦斯检测中的应用:
瓦斯检测系统中传感器集S={S1, S2, S3}分别代表甲烷,温度,一氧化碳传感器。状态集U={安全,危险},且根据经验三个传感器的权值分配策略A={a1, a2,a3}={0.6, 0.3, 0.1}。已知两个状态下单传感器的测量结果分别是:
状态1 安全 危险
CH4: 0.69 0.31
Temp: 0.81 0.19
CO: 0.53 0.47
_______________________________
状态1 安全 危险
CH4: 0.69 0.31
Temp: 0.81 0.19
CO: 0.53 0.47
设当综合评危险度大于0.5时危险,求两个状态下的安全性(Max -Min交并符合原则)。
(1)因素集:S={S1, S2, S3}
(2)决策集:U={安全,危险}
(3)评价关系矩阵,由单因素决策组成
R1 =
[0.69 0.31
0.81 0.19
0.53 0.47]
R2 =
[0.38 0.62
0.49 0.51
0.70 0.30]
(4)权重矩阵
A={a1,a2,a3}={0.6, 0.3, 0.1}
(5)最大最小合成
B1 = A·R1 = (0.6, 0.31)
B2 = A·R2 = (0.38, 0.6)
它表示状态1的评价是:“安全”的程度为0.6;“危险”的程度为0.31。
状态2“安全”的程度为0.38;“危险”的程度为0.6>0.5。因此,状态2的安全性为“危险”。
五、多源属性融合原理
25. 基于Bayes统计理论的信息融合(贝叶斯统计理论)
网络攻击
在网络攻击分析中,需要确定网络攻击的源头美O1 -日O2 -台O3 。不同的情报机构ESM、 IFFN根据数据结构确定路由路径的方法不相同 ,设路径有2条,分别用0,1表示,条件概率已知,
PESM(1|O1) = 0.8
PESM(1|O2) = 0.1
PESM(1|O3) = 0.3
PESM(1|O1) = 0.9
PESM(1|O2) = 0.05
PESM(1|O3) = 0.2
PESM(1|O1)表示ESM分析到O1发动攻击时在1路径上检测到攻击数据包的概率,其它概率表达的意义类似。
已知P(O1)=0.2, P(O2)=0.3, P(O3)=0.5。对于得到的观测值为(1,0)(即,路径1有攻击数据包,路径0无攻击数据包),请判断攻击源头。
解:对于(1,0),有
P(1,0|O1) = PESM(1|O1) PIFFN(0|O1) = 0.8*0.1=0.08
P(1,0|O2) = PESM(1|O2) PIFFN(0|O2) = 0.1*0.95=0.095
P(1,0|O3) = PESM(1|O3) PIFFN(0|O2) = 0.3*0.8=0.24
基于信息源的融合似然为
P(Oi|z) = P(z|Oi) P(Oi) / n∑i=1 P(z|Oi) P(Oi) , i=1,2,…,n
从而:
P(O1|1,0) = (0.08*0.2)/(0.08×0.2+0.095×0.3+0.24×0.5) = 0.097
P(O2|2,0) = (0.095*0.3)/(0.08×0.2+0.095×0.3+0.24×0.5) = 0.173
P(O1|3,0) = (0.24*0.5)/(0.08×0.2+0.095×0.3+0.24×0.5) = 0.73
26.先验概率与后验概率:甲袋、乙袋、白球
甲袋中有5只白球, 7 只红球;乙袋中有4只白球, 2只红球.取甲、乙两袋的概率相同, 现在任取一袋,从所取到的袋子中任取一球
(1)、甲袋中取出白球的概率多少?
(2)、问此球是甲袋中白球的概率是多少?
(3)、发现是白球,问此白球是从甲袋中取出来概率多少?
先验概率
(1)、P(C|A) = P(取到白球|取到甲袋) = 5/12
(2)、P(AC)=P(取到甲袋中的球并且是白球)=5/24
(3)、P(C|B)=P(取到白球|取到乙袋) = 4/6
而由A+B=Ω,根据贝叶斯全概率公式
P(C)=P(AC)+P(BC)=P(A)P(C|A) + P(B)P(C|B)
=(1/2)(5/12) + (1/2)(4/6)=13/24
上式概率就是先验概率。
后验概率
解:首先看样本空间。一共有18个球。样本空间为18个点。代表着取到的每个球。
先求两种情况的条件概率。
设: 事件A={取到甲袋中球},
事件B={取到乙袋中球}。且A+B=Ω.
事件C={取到白球}
所以,此白球从甲袋取出的概率为 P(A|C)=P(取到甲袋中的球|取到白球)=P(AC)/P(C)=5/13
上式概率就是后验概率,
另外P(C|A)为似然度。
六、基于模糊集合论的信息融合技术
27.模糊数学基础-随机现象和模糊现象的区别
随机事件本身有着明确的含义, 只是由于条件不充分, 使得在条件与事件之间不能出现决定性的因果关系, 从而在事件的出现与否上表现出不确定的性质。 然而, 模糊概念本身就没有明确的外延, 一个对象是否符合这个概念是难以确定的, 因此造成了划分的不确定性。 其主要不同在于,随机的事件定义是明确的,其不确定性体现在对事件是否发生的刻画。模糊性恰恰相反,其不确定性体现在对事件的定义是不明确的。
举例:下雨与不下雨,是随机现象,事件发生存在一定概率;雨的大小,如小雨、小到中雨、中雨、中到大雨、大雨、大到暴雨等,是模糊现象,概念没有明确的外延。
28.模糊集合的运算
例:已知论域U={u1,u2,u3,u4}
Ac = 0.3/u1+0.5/u2+0.7/u3+0.4/u4,
Bc = 0.5/u1+1/u2+0.8/u3
A∪B = 0.3∨0.5/u1 + 0.5∨1/u2 + 0.7∨0.8/u3 + 0.4∨0/u4
=0.5/u1 + 1/u2 + 0.8/u3 + 0.4/u4
A∩B = 0.3∧0.5/u1 + 0.5∧1/u2 + 0.7∧0.8/u3 + 0.4∧0/u4
=0.3/u1 + 0.5/u2 + 0.7/u3
29.验证分解定理
设U={1,2,3,4,5,6} ,A={0.1, 0.4, 0.8, 1, 0.8, 0.4},根据分解定理,A可分解为:
A=1 A1 ∪ 0.8A0.8 ∪ 0.4 A0.4 ∪0.1 A0.1。
写出A0.1、A0.4、A0.8、A1
A0.1={1,2,3,4,5,6},
A0.4={2,3,4,5,6},
A0.8={3,4,5},
A1={4}
因而,
Uλ∈[0,1]λAλ=1A1U0.8A0.8U0.4A0.4U0.1A0.1
= 1/x4 U (0.8/x3+0.8/x4+0.8/x5)
U (0.4/x2+0.4/x3+0.4/x4+0.4/x5+0.4/x6)
U (0.1/x2+0.1/x3+0.1/x4+0.1/x5+0.1/x6)
= 0.1/x1 + 0.4/x2 + 0.8/x3 + 1/x4 + 0.8/x5 + 0.4/x6
= A
30.模糊数学模型举例1
例:评价某种牌号的手表,U={x1,x2,x3,x4},其中x1表示外观式样,x2表示走时准确,x3表示价格,x4表示质量。
评语集为V={y1,y2,y3},其中y1表示很满意,y2表示满意,y3表示不满意。
对外观式样有70%的顾客很满意,20%的顾客满意,10%的顾客不满意,那么
f(x1) = 0.7/y1 + 0.2/y2 + 0.1/y3
同理,有
f(x2) = 0.6/y1 + 0.3/y2 + 0.1/y3
f(x3) = 0.5/y1 + 0.3/y2 + 0.2/y3
f(x4) = 0.5/y1 + 0.4/y2 + 0.1/y3
单因素矩阵R
R =
[0.7 0.2 0.1
0.6 0.3 0.1
0.5 0.3 0.2
0.5 0.4 0.1]
由于各个因素在综合评价中的作用不同,为此给出一个U的模糊集合,A={a1,a2,a3,…,an},满足条件∑ai=1,在综合评价中,将A称为综合评价的权重向量,对于给定的权重,综合评价就是 的一个模糊变换U →V。
假设如果某类顾客评价手表的权重为0.4,0.2,0.3,0.1 ,即对四个方面的重视程度为40%,20%,30%,10%。
由max-min复合:(先选小的再选大的)
B = A·R = (0.4, 0.2, 0.3, 0.1) · [0.7 0.2 0.1
0.6 0.3 0.1
0.5 0.3 0.2
0.5 0.4 0.1]
=(0.4,0.3,0.2)
说明很满意,满意,不满意的隶属度依次是0.4,0.3,0.2,根据最大隶属原则,可以认为这类顾客对这种手表“很满意”
图像部分
1.低通滤波全流程
1.载入图片
2.对图像进行格式转换
3.对图像进行快速傅里叶变换,得到频谱图
4.将频谱图中的低频部分转移到中间部分
5.设置矩形窗口遮罩,设为1,过滤高频,实现低通滤波
6.将频谱图中的低频部分转移回图像的原先位置
7.对图像进行傅里叶的反变换
8.得到低通滤波后的图像
1.人脸重构
大大复原了嫌疑人的面部特征,有利于之后的侦查破案
将技术推广后可以大大减轻人脸画像师的工作压力,提高工作效率和办案效率
促进智慧警务的建设,为警务视频侦查增添技术支持,实现全时段、全方位等人员的识别跟踪
实现人脸局部特征的重构,不需要全貌一致,提高重构效率
1.直方图均衡化
首先通过各像素值出现的次数其次将统计结果进行归一化处理然后统计各像素值的累计直方图最后将各像素值的累计直方图百分比乘以像素范围的最大值
总像素点个数:12+1+21+45+15+30+3+1=128
计算各灰度级出现的概率:[0,1,2,3,4,5,6,7]-->[0.09,0.01,0.16,0.35,0.12,0.23,0.02,0.01]
计算累计结果为:[0.09,0.1,0.26,0.61,0.73,0.96,0.98,0.99]
像素范围的最大值乘以累加后的结果(四舍五入):[1,1,2,4,5,7,7,7]
输出图像的分布数据(各灰度级上的像素数)
第二个表
输出图像的分布数据(各灰度级上的像素数)1 2 4 5 7
像素个数 ni 13 21 45 15 34
=
首先通过各像素值出现的次数,
其次将统计结果进行归一化处理,
然后统计各像素值的累计直方图,
最后将各像素值的累计直方图百分比乘以像素范围的最大值。
3.图像增强
空域图像增强:亮度调整:对比度增强直方图均衡化:
频域图像增强:傅里叶变换
高通滤波:增强图像中的高频细节。
低通滤波:平滑图像并减少噪音。
锐化和模糊:
图像锐化:突出图像中的边缘和细节。
图像模糊:平滑图像以减少噪音或减弱细节。
形态学处理:膨胀和腐蚀
多尺度增强:小波变换
深度学习方法:卷积神经网络(CNN)
1.高斯平滑
f(x+1,y+1)=(3*0.05+1*0.1+5*0.05)+(4*0.1+8*0.4+1*0.1)+(1*0.05+4*0.1+0*0.05)=4.65=4
1.平均滤波
求像素点(x+1,y+1)的3*3 方形中值滤波后的结果:
(1)以像素点(x+1,y+1)为中心的9个相邻点为:3,1,5,4,8,1,1,4,0
(2)对以上9个像素值按从小到大顺序排序:0,1,1,1,3,4,4,5,8
(3)以上9个像素值的中位数为3,因此点1(8)进行3*3 方形中值滤波后的结果是3
2.soble
Gx=1*f(x+2,y)+2*f(x+2,y+1)+1*f(x+2,y+2) -1*f(x,y)-2*f(x,y+1)-1*f(x,y+2)
Gy=f(x,y)+2*f(x+1,y)+f(x+2,y) -f(x,y+2)-2*f(x+1,y+2)-f(x+2,y+2)
Sobel边缘算子处理后的值=abs(Gx)*0.5+abs(Gy)*0.5=89*0.5+23*0.5=56
3.robet
解:r1=abs(f(x,y)-f(x,y-1))=abs(161-110)=51
r2=abs(f(x-1,y)-f(x,y-1)=abs(118-110)=8
经过Roberti边缘算子处理后的值=0.5*51+0.5*8=33.5
#旋转
src=cv2.imread('xianyiren.jpg')
#获取原始图像的高、宽以及通道数
rows,cols,channel=src.shape
#定义旋转矩阵
M=cv2.getRotationMatrix2D((cols/2,rows/2),-40,1) #逆正,顺负
#对输入图像按旋转矩阵进行旋转
rotatated=cv2.warpAffine(src,M,(cols,rows))
#将旋转后的图像的宽和高都缩小为原来一半
xianyiren2=cv2.resize(rotatated,(cols//2, rows//2))
xianyiren2=cv2.resize(rotatated,(300,400))
#将图保存为xianyiren2.jpg
cv2.imwrite('xianyiren2.jpg',xianyiren2)
# 平移
M=np.float32([[1,0,-100],[0,1,30]])
#获取原始图像列数和行数
rows,cols=src.shape[:2]
#图像平移,使用平移矩阵,运用opencv的warpAffine函数对图像进行平移
result=cv2.warpAffine(src,M,(cols,rows))
1.第100-150纯黑色
img[100:150,150:200]=[0,0,0]
2.取出蓝色通道的图像
b, g, r = cv2.split(img)
g[:] = 0
r[:] = 0
3.翻转
img=cv2.imread("xianyiren.jpg")
filp=cv2.flip(img,-1)
cv2.imwrite("xianyiren2.jpg",filp)
4.加权
# 将图像2的大小改成和图像1的大小相同
img2=cv2.resize(img2,img1.shape[0:2][::-1])
result=cv2.addWeighted(img1,0.6,img2,0.8,10)
#实践3
#图像灰度处理
import cv2
import numpy as np
#读取原始图像
img = cv2.imread('bri.jpg')
#获取图像高度和宽度
height = img.shape[0]
width = img.shape[1]
#图像最大值灰度处理
grayimg1 = np.zeros((height, width, 3), np.uint8)
#图像最大值灰度处理
for i in range(height):
for j in range(width):
#获取图像R G B最大值
gray = max(img[i,j][0], img[i,j][1], img[i,j][2])
#灰度图像素赋值 gray=max(R,G,B)
grayimg1[i,j] = np.uint8(gray)
#图像平均灰度处理方法
grayimg2 = np.zeros((height, width, 3), np.uint8)
# print (grayimg)
#图像平均灰度处理方法
for i in range(height):
for j in range(width):
#灰度值为RGB三个分量的平均值
gray = (int(img[i,j][0]) + int(img[i,j][1]) + int(img[i,j][2])) / 3
grayimg2[i,j] = np.uint8(gray)
#图像加权灰度化处理方法
grayimg3 = np.zeros((height, width, 3), np.uint8)
#图像加权灰度化处理方法
for i in range(height):
for j in range(width):
#灰度值为RGB三个分量的平均值
gray = 0.30*img[i,j][0] + 0.59*img[i,j][1] + 0.11*img[i,j][2]
grayimg3[i,j] = np.uint8(gray)
#图像融合和保存
a=cv2.addWeighted(grayimg1,0.5,grayimg2,0.5,0)
result=cv2.addWeighted(a,0.5,grayimg3,0.5,0)
cv2.imwrite('result.jpg',result)
#sobel算子二值化处理
img = cv2.imread('car.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#2、提取轮廓(Sobel算子对x方向求导,提取竖直方向边缘)让图像变“瘦”,便于把车牌揉成一团。
#输出图像位深设为cv2.CV_16S
y = cv2.Sobel(gray, cv2.CV_16S, 1,0)
# 注:对x/y微分和得到x/y方向图像相反 要得到x/y方向边缘,就要求y/x方向的微分。
absY = cv2.convertScaleAbs(y)
# 3、二值化处理(阈值化类型设为cv2.THRESH_OTSU使用最小二乘法处理像素点)
ret, binary = cv2.threshold(absY, 0, 255, cv2.THRESH_OTSU)
#4、保存图像为binary.jpg
cv2.imwrite('binary.jpg', binary)
#prewit算子
graylmage=cv2.cvtColor(img.cv2.COLOR_BGR2GRAY)
#分别构造x和y方向上的卷积模板
kx = np.array([[1, 0, -1], [1, 0, -1], [1, 0, -1]], dtype=int)
ky = np.array([[1, 1, 1], [0, 0, 0], [-1, -1, -1]], dtype=int)
#调用filter2D0函数实现对图像的卷积运算输出图像位深设为cv2.CV_16S
x = cv2.filter2D(grayImage, cv2.CV_16S, kx)
y = cv2.filter2D(grayImage, cv2.CV_16S, ky)
#通过convertScaleAbs0和addWeighted0函数实现边缘提取
#两个方向的权重分别是0.5
ax = cv2.convertScaleAbs(x)
ay = cv2.convertScaleAbs(y)
Prewitt = cv2.addWeighted(ax, 0.5, ay, 0.5, 0)
cv2.imwrite('Prewitt.jpg,Prewitt)
#傅里叶
#(1)傅里叶正向变换
img = cv2.imread('pic.jpg',0) # 导入图像,变成灰度图
#对图像进行傅里叶变换
dft = np.fft.fft2(img)
# 将低频值转换到中间
dft_shift=np.fft.fftshift(dft)
#(2)构造滤波器
# 获取频率为1部分中心点位置
rows,cols = img.shape # (471,498),分别保存图像的高和宽
crow,ccol = int(rows/2), int(cols/2) # 计算中心点坐标
# 构造低通滤波器,相当于构造一个掩模
# 构造的size和原图相同
# 构造一个以频率为0点中心对称,长30+30,宽30+30的一个区域,只保留区域内部的频率
mask=np.zeros((rows,cols),np.uint8)
mask[crow-30:crow+30,ccol-30:ccol+30]=1
#(3)滤波
# 频谱图上,低频的信息都在中间,滤波器和频谱图相乘,遮挡四周,保留中间,中间是低频
fshift=dft_shift*mask
# 在获得频谱图时,将低频点从边缘点移动到图像中间,现在要逆变换,得还回去
f_ishift = np.fft.ifftshift(fshift)
#(4)傅里叶逆变换idft
himg =np.fft.ifft2(f_ishift)
himg = np.abs(himg)
#保存高通滤波处理图像
cv2.imwrite('ditong.jpg',himg)
#实践五
Sobel函数
s1 = abs(sz[0] + 2 * sz[1] + sz[2] - sz[6] - 2 * sz[7] - sz[8])
s2 = abs(sz[0] + 2 * sz[3] + sz[6] - sz[2] - 2 * sz[5] - sz[8])
y = int(k * (s1 + s2) + sz[4])
return normalize(y)
#robet函数
r1 = abs(int(sz[0]) - int(sz[8]))
r2 = abs(int(sz[2]) - int(sz[6]))
y = int(k * max(r1, r2) + sz[4])
return normalize(y)
2.对图像进行灰度线性变换
#分段线性变换
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
img = cv2.imread('275.jpeg')
grayimage = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
height = grayimage.shape[0]
width = grayimage.shape[1]
result = np.zeros((height,width),np.uint8)
for i in range(height):
for j in range(width):
if (int(grayimage[i,j]) < 80):
gray =int(grayimage[i,j]*4)
if (80<int(grayimage[i,j]) < 200):
gray =int(grayimage[i,j]*1.4)
else:
gray = int(grayimage[i,j]*1.3)
if (gray>255):
gray=255
result[i,j] = np.uint8(gray)
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(121),plt.imshow(img,'gray'),plt.title(u'(a)原始图像')
plt.subplot(122),plt.imshow(result,'gray'),plt.title(u'(a)处理后图像')
大数据部分
程序片段题
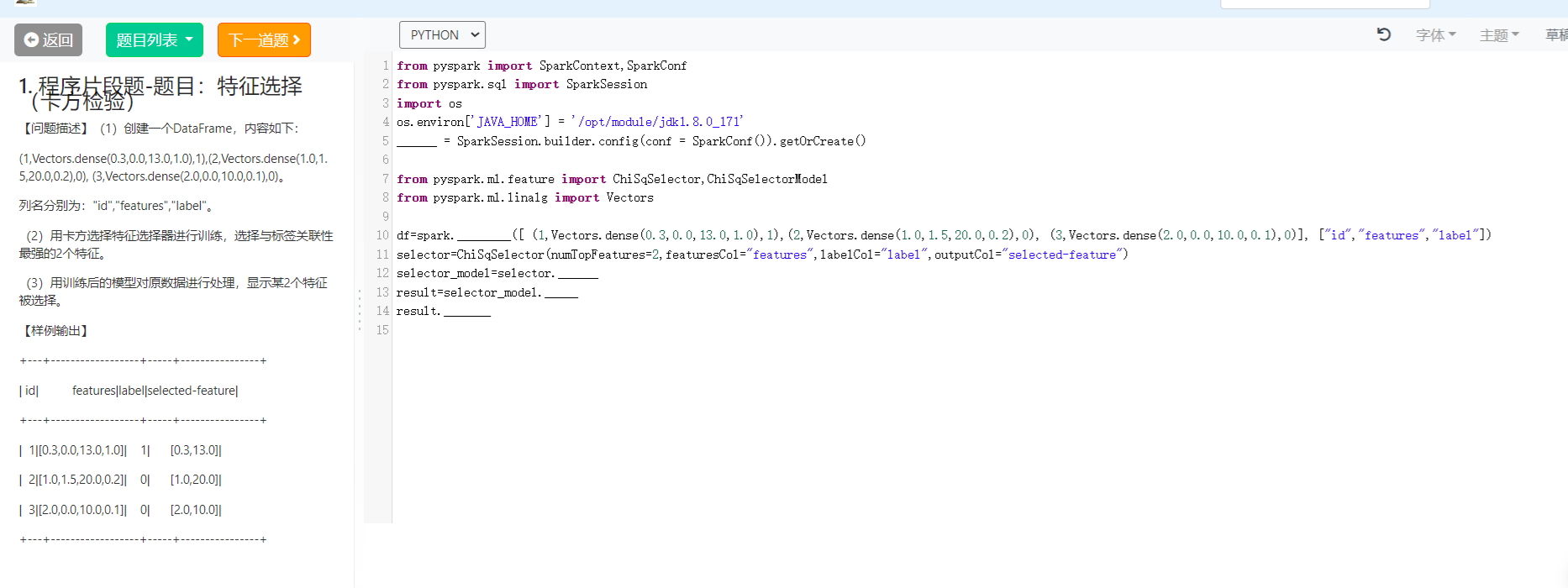
1.卡方检验
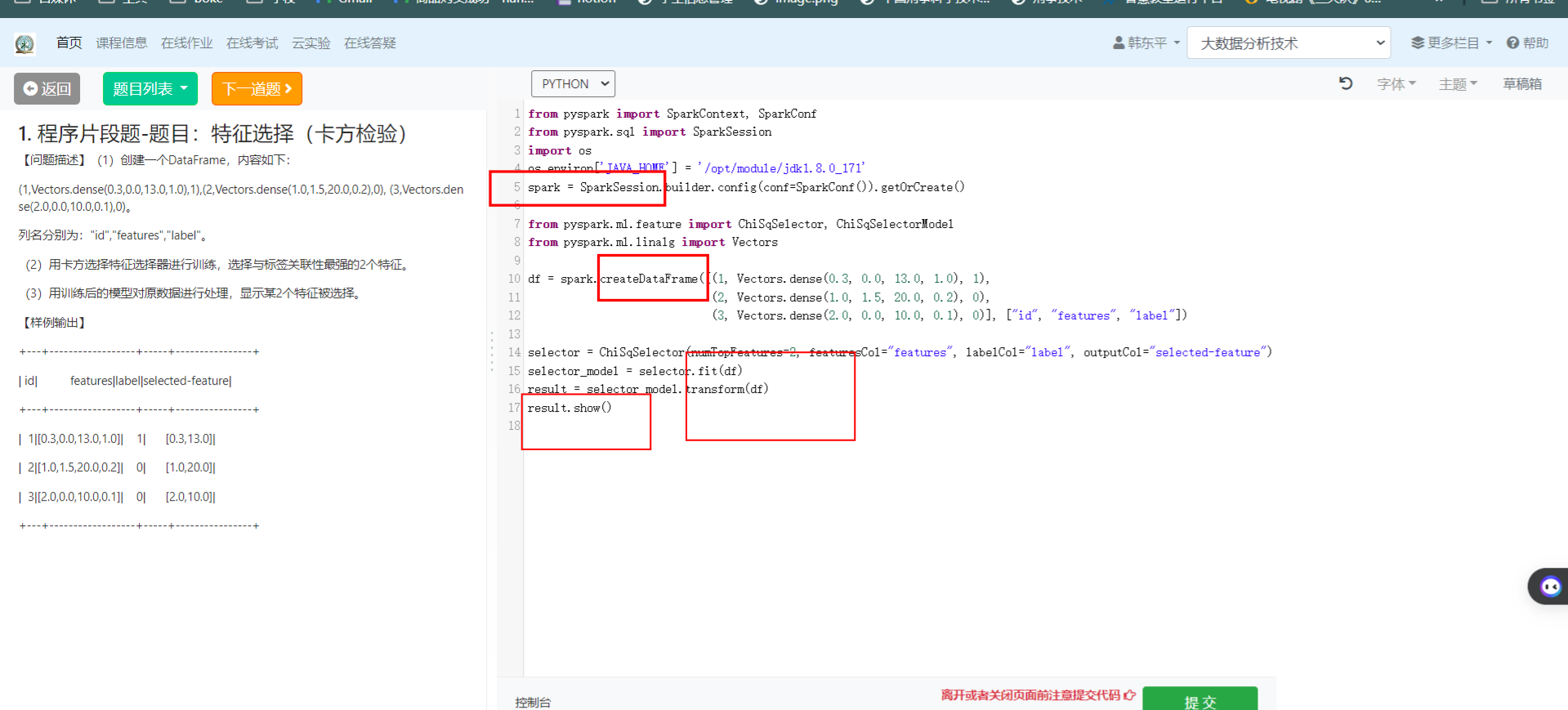
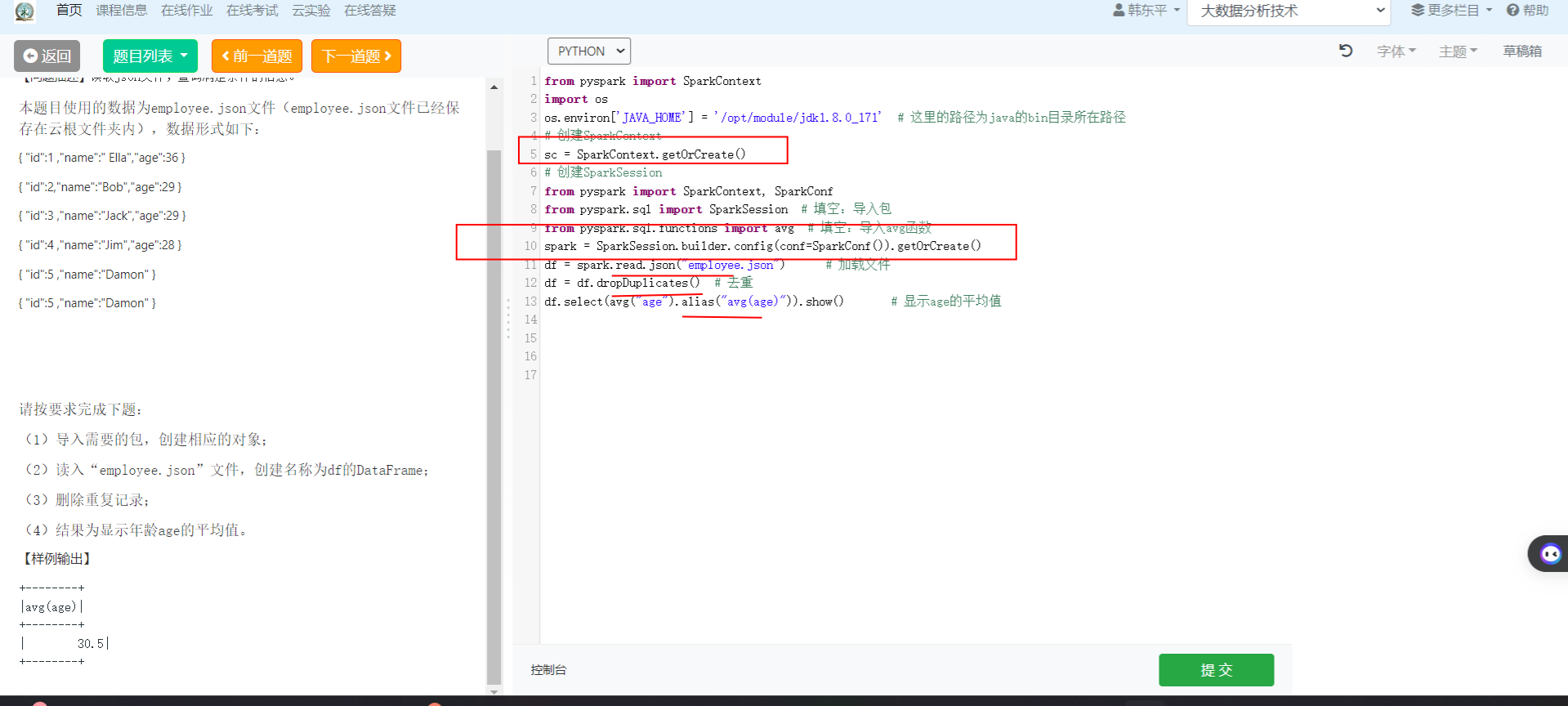
2.程序片段题-题目:读取json文件,查询满足条件的信息
(1)导入需要的包,创建相应的对象;
(2)读入“employee.json”文件,创建名称为df的DataFrame;
(3)删除重复记录;
(4)结果为显示年龄age的平均值。
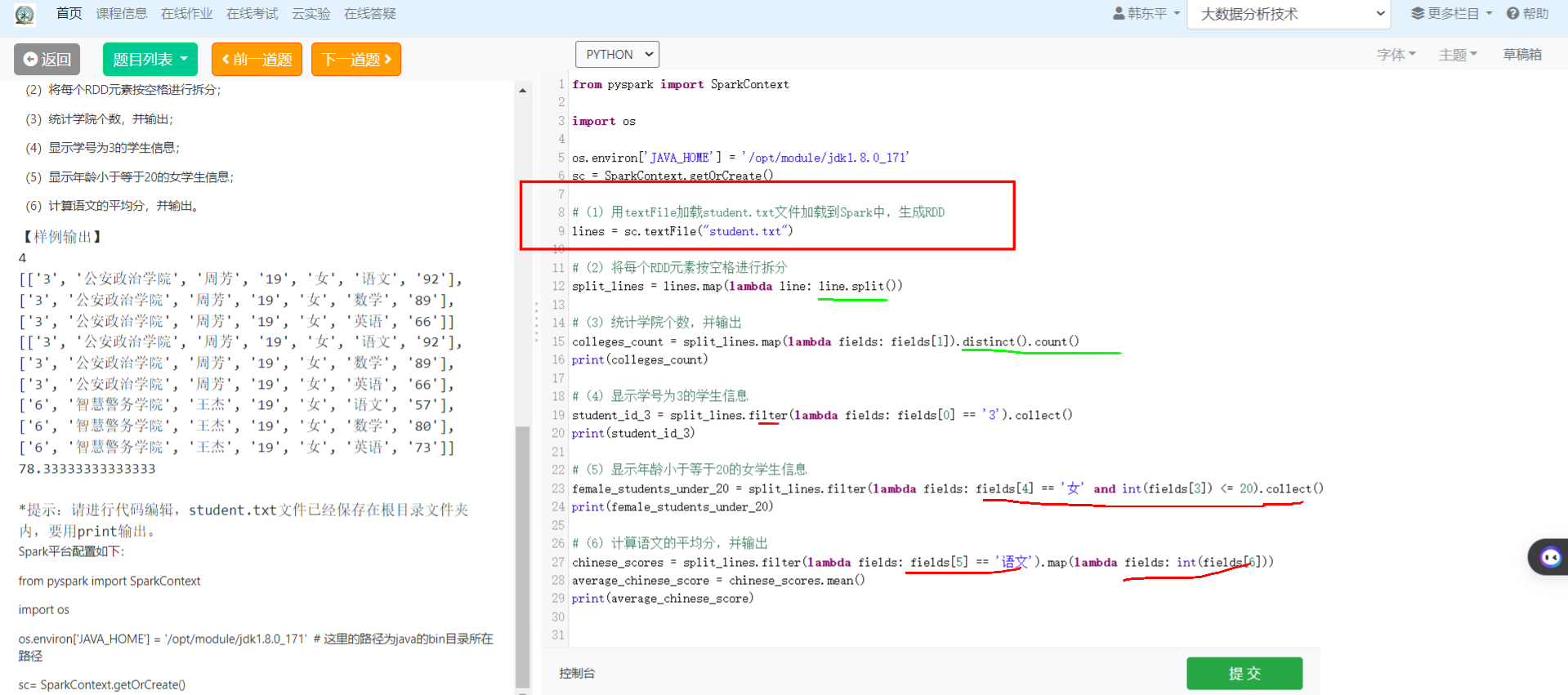
3.编程题-题目:RDD编程实现学生信息处理
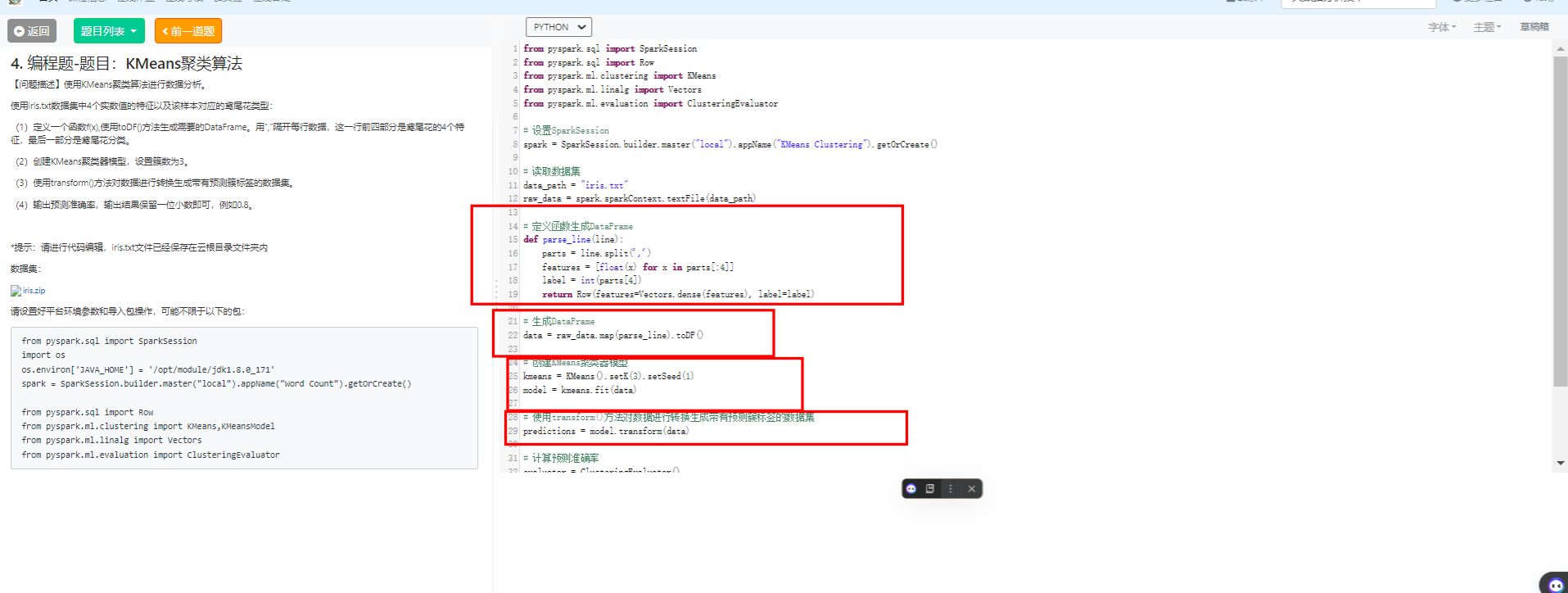
4编程题-题目:KMeans聚类算法
编程题
1. 编程题-题目:KMeans聚类算法
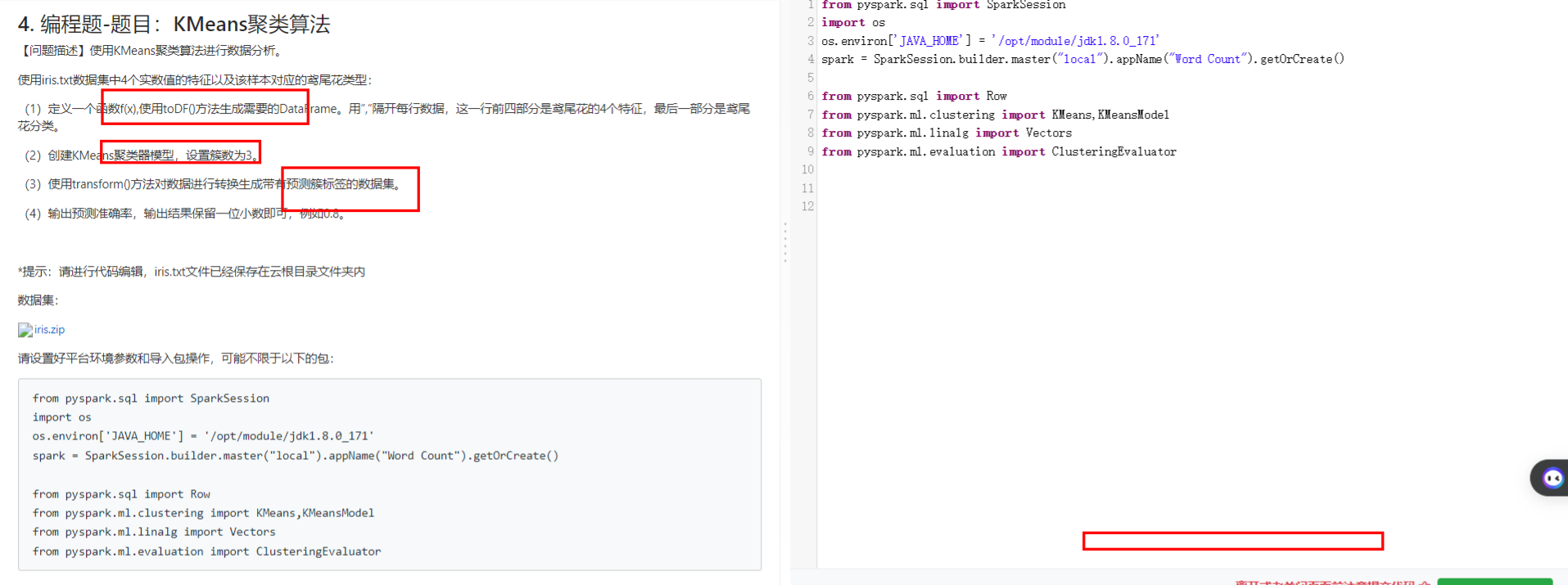
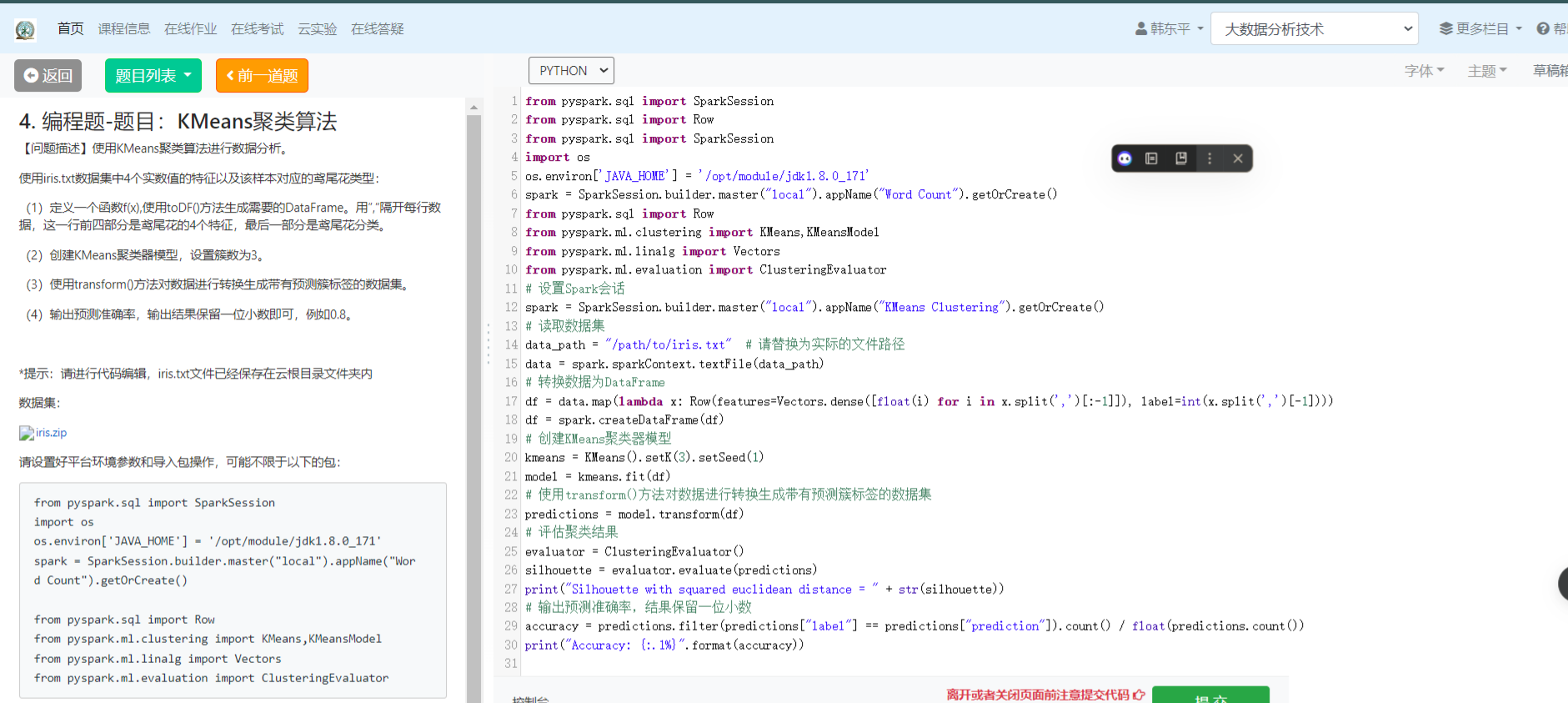
2.编程题-题目:机器学习分词
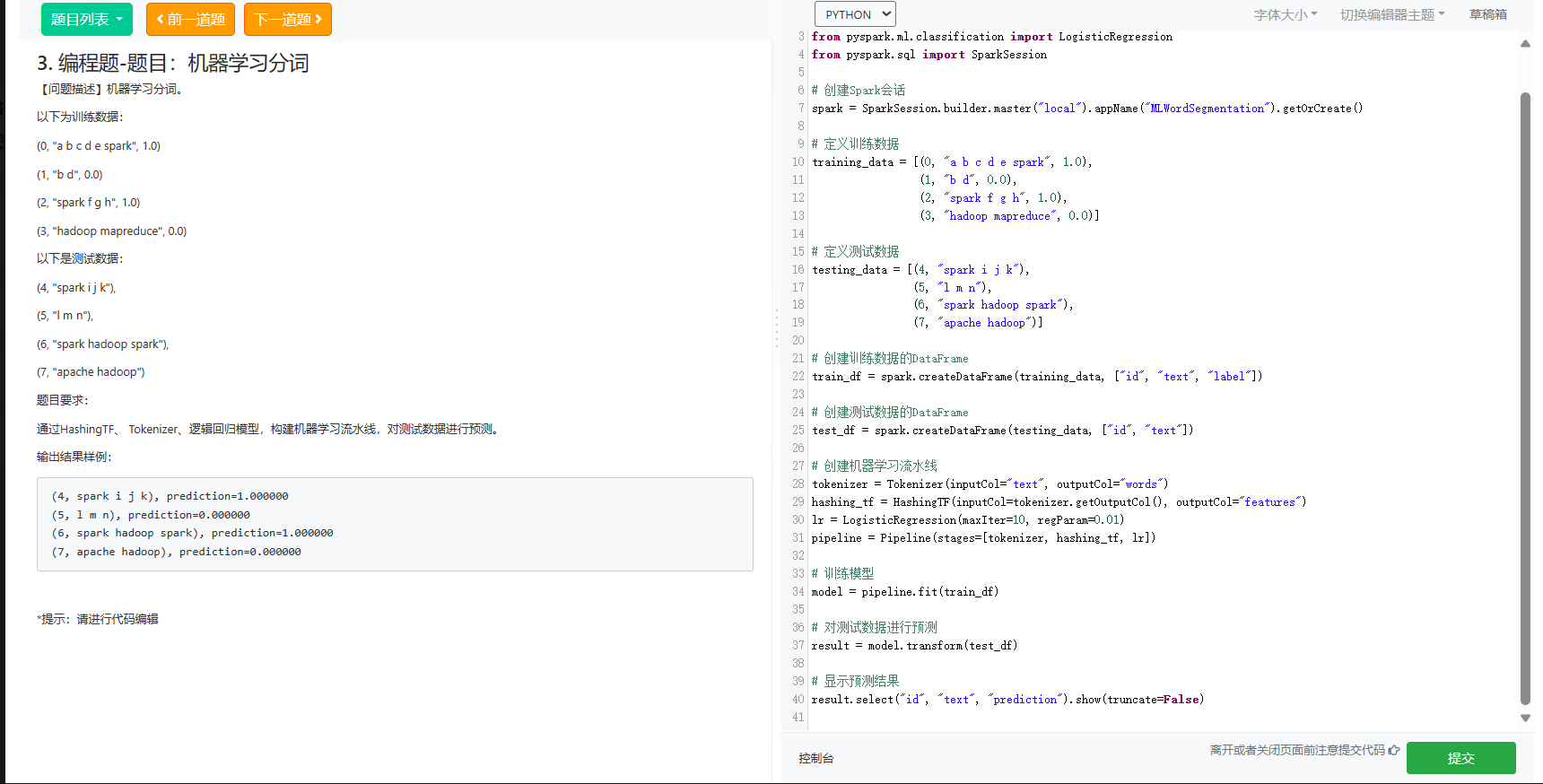
以下是使用PySpark构建机器学习流水线并对测试数据进行预测的代码:
from pyspark.ml import Pipeline
from pyspark.ml.feature import HashingTF, Tokenizer
from pyspark.ml.classification import LogisticRegression
from pyspark.sql import SparkSession
# 创建Spark会话
spark = SparkSession.builder.master("local").appName("MLWordSegmentation").getOrCreate()
# 定义训练数据
training_data = [(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)]
# 定义测试数据
testing_data = [(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")]
# 创建训练数据的DataFrame
train_df = spark.createDataFrame(training_data, ["id", "text", "label"])
# 创建测试数据的DataFrame
test_df = spark.createDataFrame(testing_data, ["id", "text"])
# 创建机器学习流水线
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashing_tf = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashing_tf, lr])
# 训练模型
model = pipeline.fit(train_df)
# 对测试数据进行预测
result = model.transform(test_df)
# 显示预测结果
result.select("id", "text", "prediction").show(truncate=False)这段代码使用了HashingTF来进行特征提取,Tokenizer进行分词,然后使用逻辑回归模型进行分类。最后,通过机器学习流水线对测试数据进行预测,并显示预测结果。
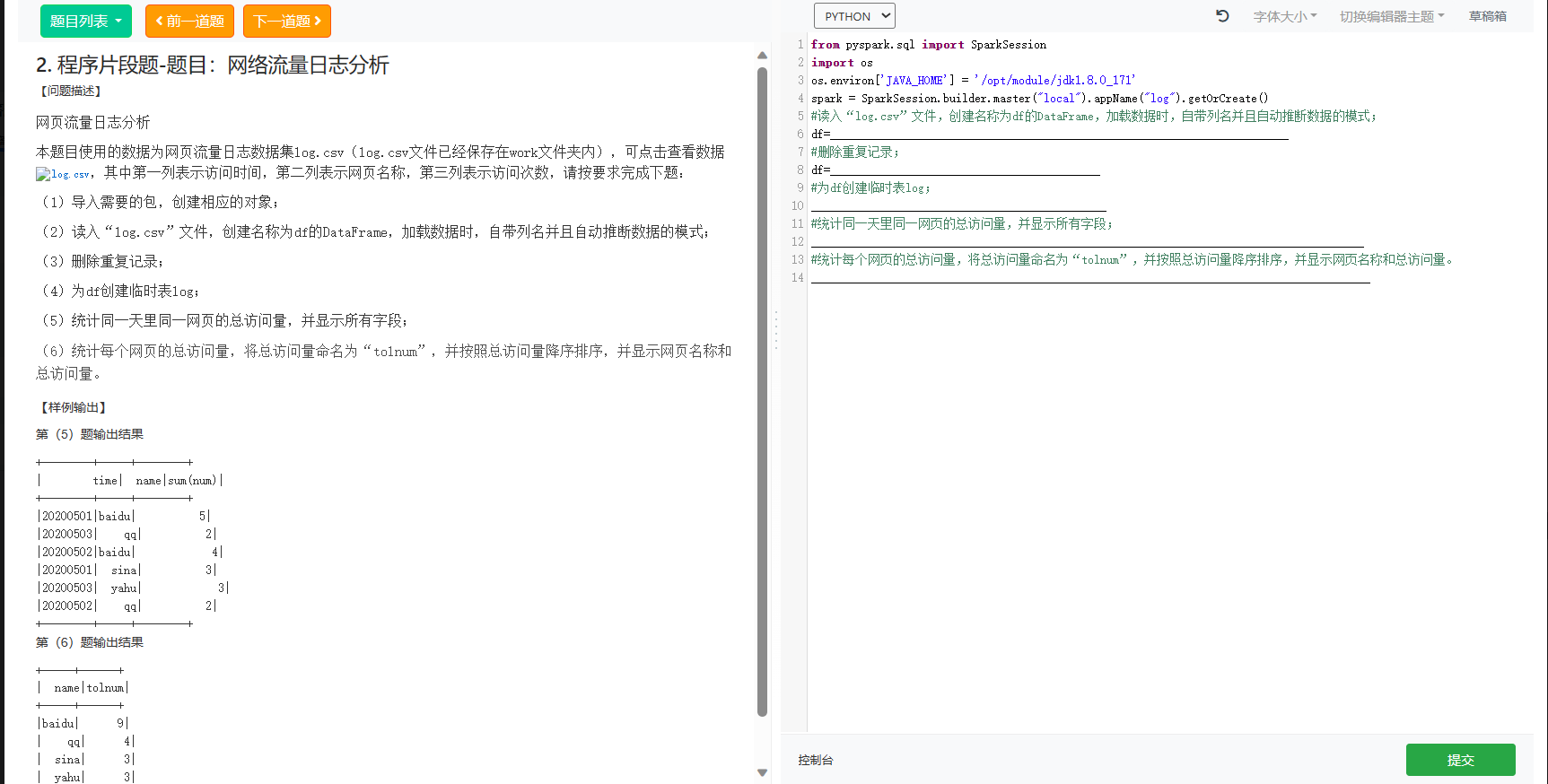
2.程序片段题-题目:网络流量日志分析


from pyspark.sql import SparkSession
import os
# Set Java home environment variable
os.environ['JAVA_HOME'] = '/opt/module/jdk1.8.0_171'
# Create Spark session
spark = SparkSession.builder.master("local").appName("log").getOrCreate()
# Read in "log.csv" file, create a DataFrame named df, loading data with headers and inferring schema
df = spark.read.csv("log.csv", header=True, inferSchema=True)
# Remove duplicate records
df = df.dropDuplicates()
# Create a temporary table 'log'
df.createOrReplaceTempView("log")
# Statistic: Total visits for each page on the same day, showing all fields
result_day_page = spark.sql("""
SELECT time, name, sum(num) as sum(num)
FROM log
GROUP BY time, name
""")
result_day_page.show()
# Statistic: Total visits for each page, named as "tolnum", ordered by total visits in descending order, showing page name and total visits
result_page_total = spark.sql("""
SELECT name, sum(num) as tolnum
FROM log
GROUP BY name
ORDER BY tolnum DESC
""")
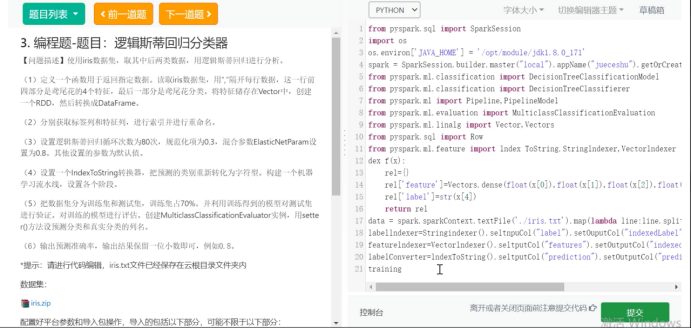
result_page_total.show()3.编程题-题目:逻辑斯蒂回归分类器
4.编程题-题目:RDD编程实现学生信息处理
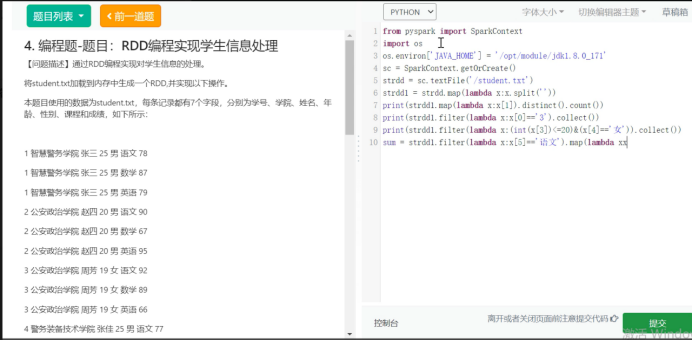
![]()
2编程题-题目:决策树分类器
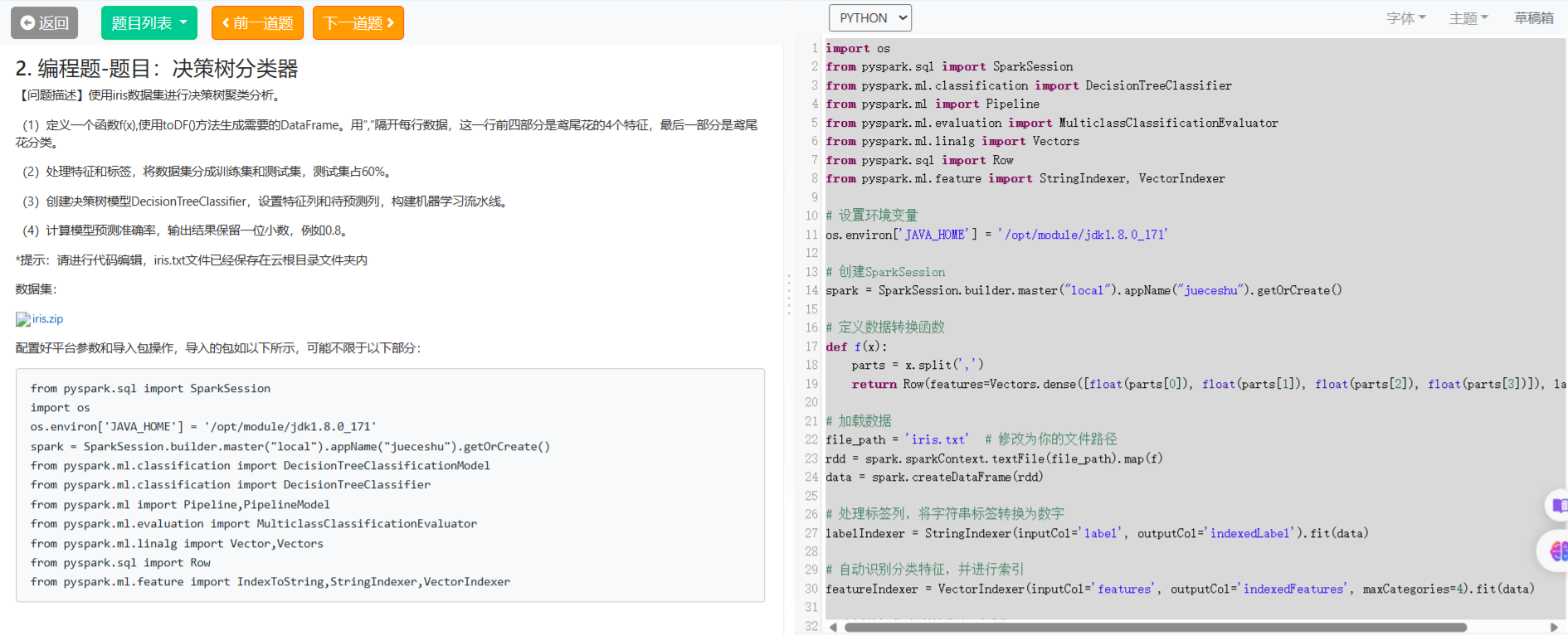
import os
from pyspark.sql import SparkSession
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.linalg import Vectors
from pyspark.sql import Row
from pyspark.ml.feature import StringIndexer, VectorIndexer
# 设置环境变量
os.environ['JAVA_HOME'] = '/opt/module/jdk1.8.0_171'
# 创建SparkSession
spark = SparkSession.builder.master("local").appName("jueceshu").getOrCreate()
# 定义数据转换函数
def f(x):
parts = x.split(',')
return Row(features=Vectors.dense([float(parts[0]), float(parts[1]), float(parts[2]), float(parts[3])]), label=parts[4])
# 加载数据
file_path = 'iris.txt' # 修改为你的文件路径
rdd = spark.sparkContext.textFile(file_path).map(f)
data = spark.createDataFrame(rdd)
# 处理标签列,将字符串标签转换为数字
labelIndexer = StringIndexer(inputCol='label', outputCol='indexedLabel').fit(data)
# 自动识别分类特征,并进行索引
featureIndexer = VectorIndexer(inputCol='features', outputCol='indexedFeatures', maxCategories=4).fit(data)
# 分割数据集为训练集和测试集
(train_data, test_data) = data.randomSplit([0.4, 0.6])
# 创建决策树模型
dt = DecisionTreeClassifier(labelCol='indexedLabel', featuresCol='indexedFeatures')
# 构建机器学习流水线
pipeline = Pipeline(stages=[labelIndexer, featureIndexer, dt])
# 训练模型
model = pipeline.fit(train_data)
# 进行预测
predictions = model.transform(test_data)
# 计算准确率
evaluator = MulticlassClassificationEvaluator(labelCol='indexedLabel', predictionCol='prediction', metricName='accuracy')
accuracy = evaluator.evaluate(predictions)
# 输出准确率,保留一位小数
accuracy_rounded = round(accuracy, 1)
print(accuracy_rounded)
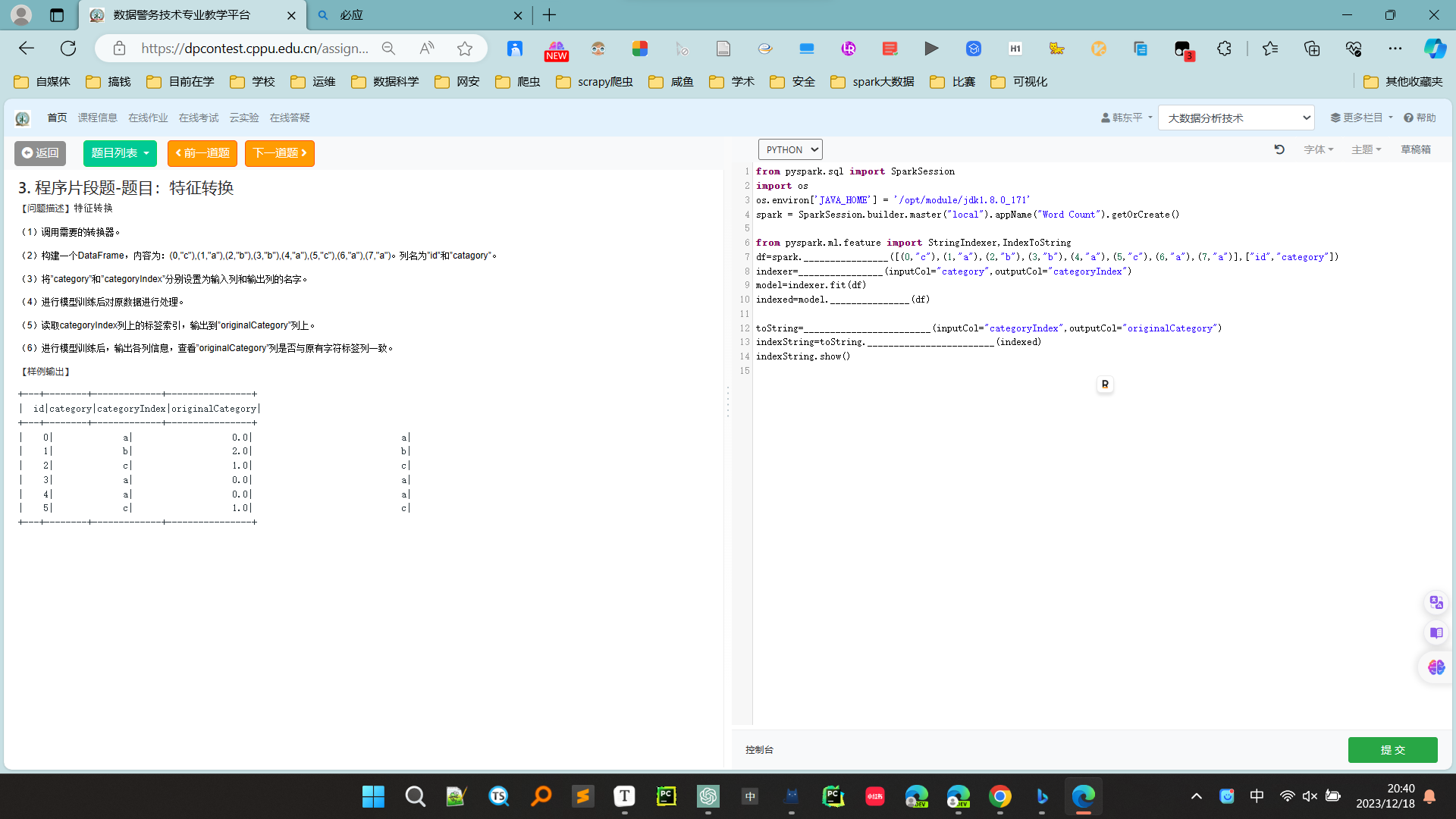
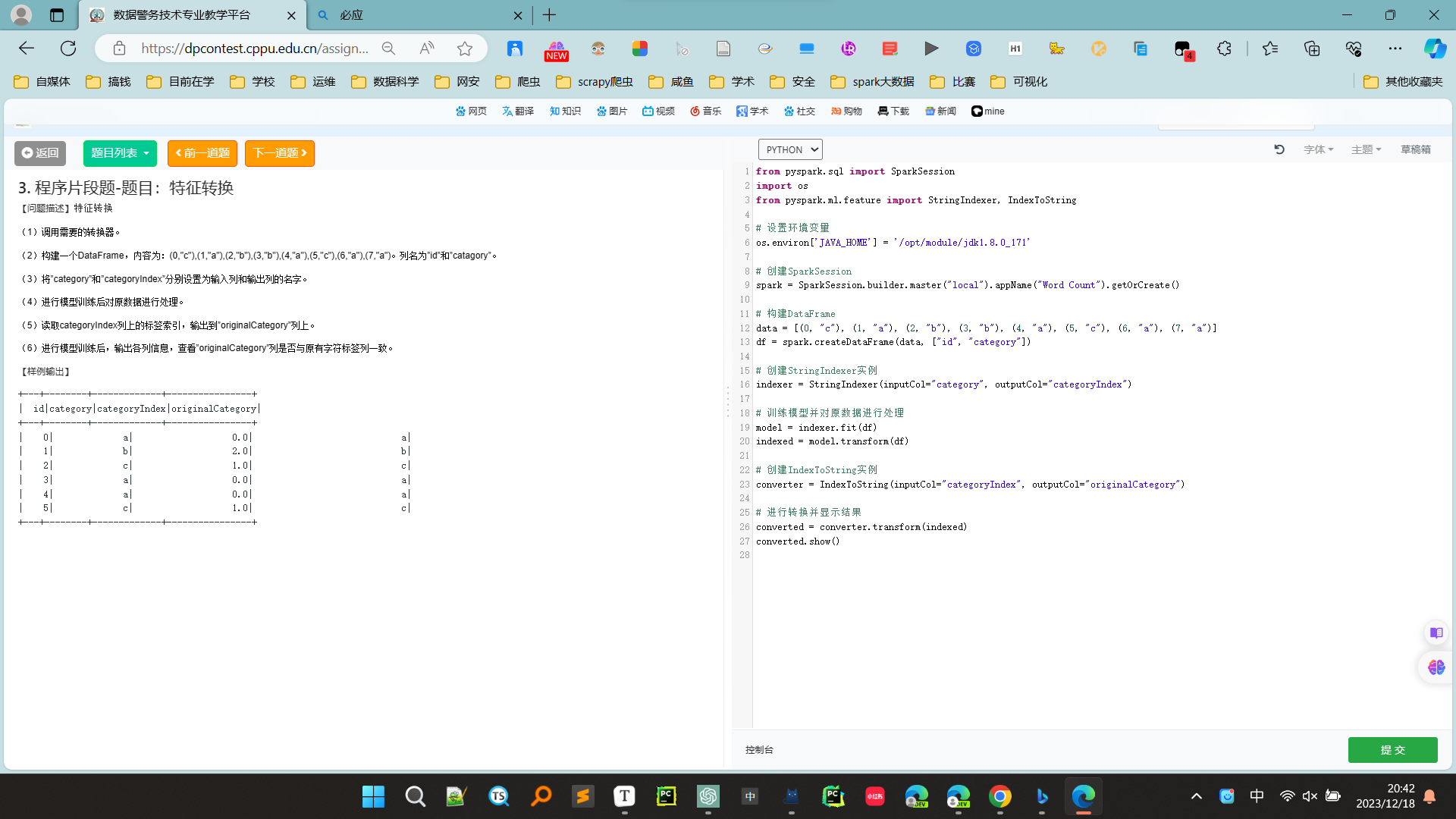
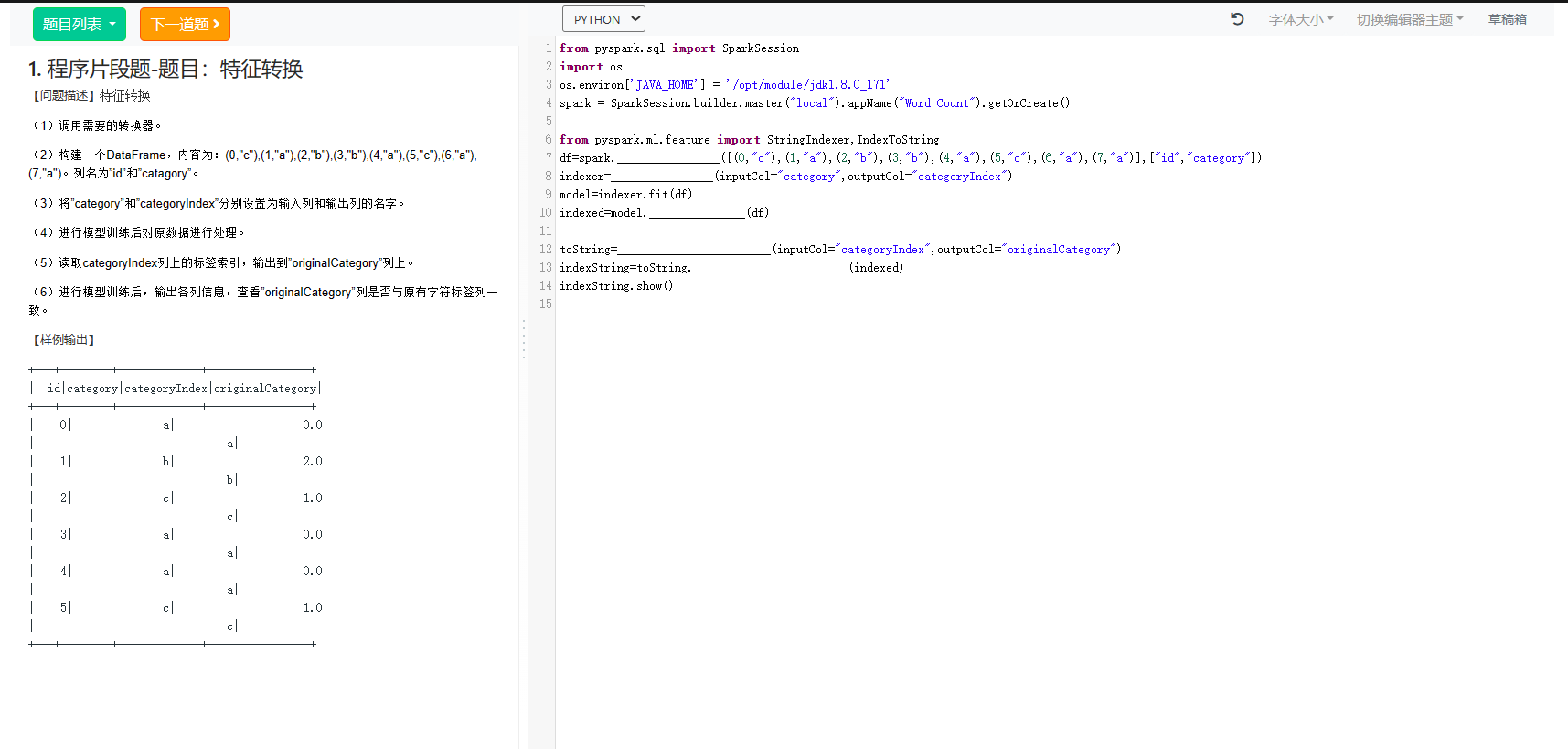
3. 程序片段题-题目:特征转换
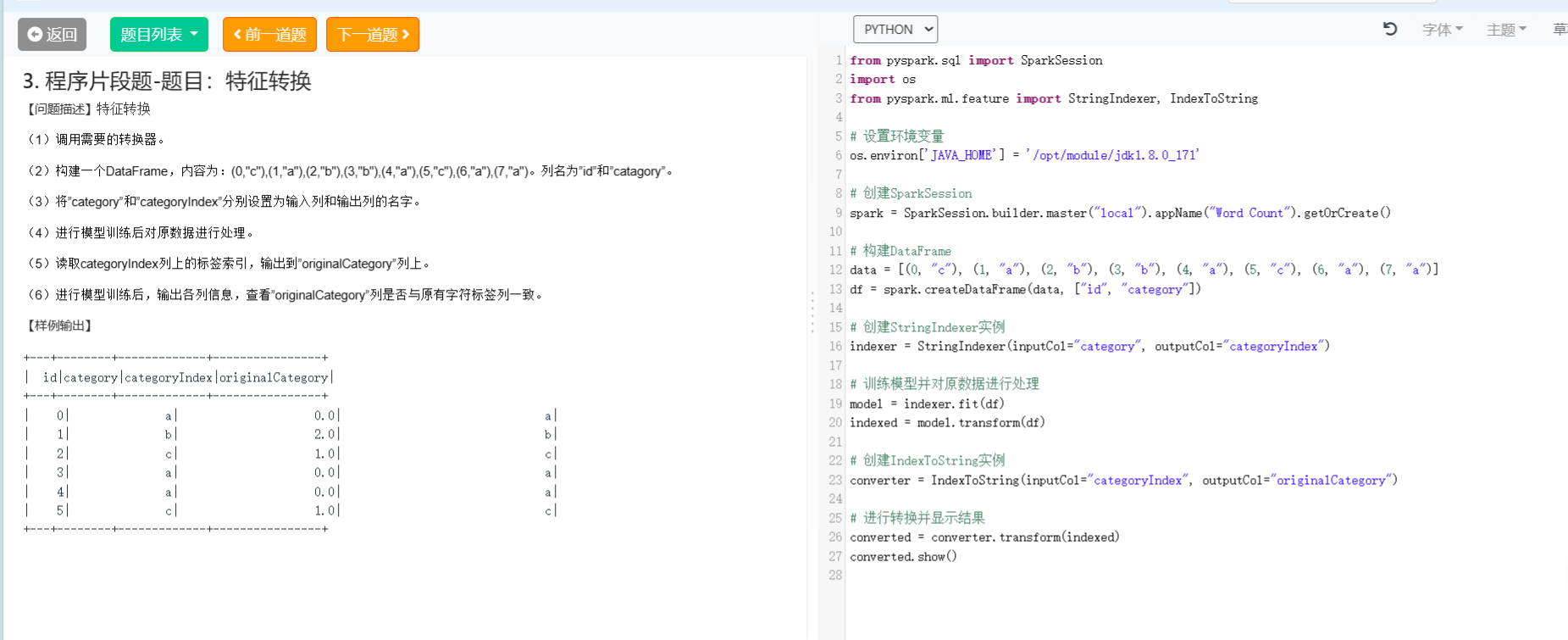
1. 程序片段题-题目:特征转换
from pyspark.sql import SparkSession
import os
os.environ['JAVA_HOME'] = '/opt/module/jdk1.8.0_171'
spark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
from pyspark.ml.feature import StringIndexer,IndexToString
df=spark.createDataFrame([(0,"c"),(1,"a"),(2,"b"),(3,"b"),(4,"a"),(5,"c"),(6,"a"),(7,"a")],["id","category"])
indexer=StringIndexer(inputCol="category",outputCol="categoryIndex")
model=indexer.fit(df)
indexed=model.transform(df)
toString=IndexToString(inputCol="categoryIndex",outputCol="originalCategory")
indexString=toString.transform(indexed)
indexString.show()此代码使用StringIndexer将“category”列转换为数值索引,然后使用IndexToString将索引转换回原始的类别标签。输出的DataFrame indexString 将具有"id"、"category"、"categoryIndex" 和 "originalCategory" 列,如示例输出中指定的那样。
2.程序片段题-题日:网络流量日志分析
简答
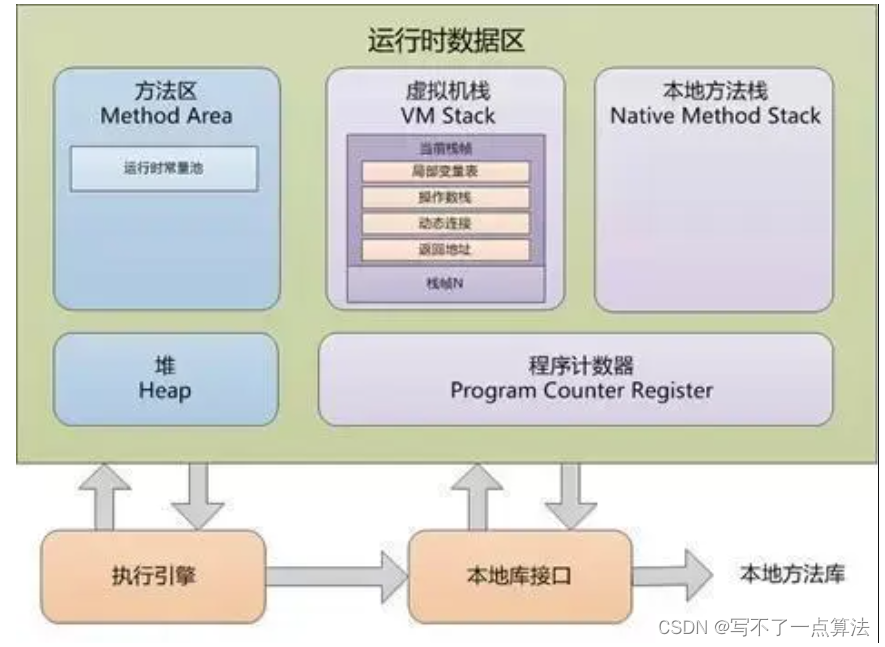
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上,作用有二:增加并行度和减少通信开销(连接操作),例如下图:
RDD分区原则:
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目
对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
*本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N,local[*]则自动判断
*Apache Mesos:默认的分区数为8
*Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
spark运行模式有哪些,并简要说明每种运行模式?
Apache Spark支持以下几种运行模式:





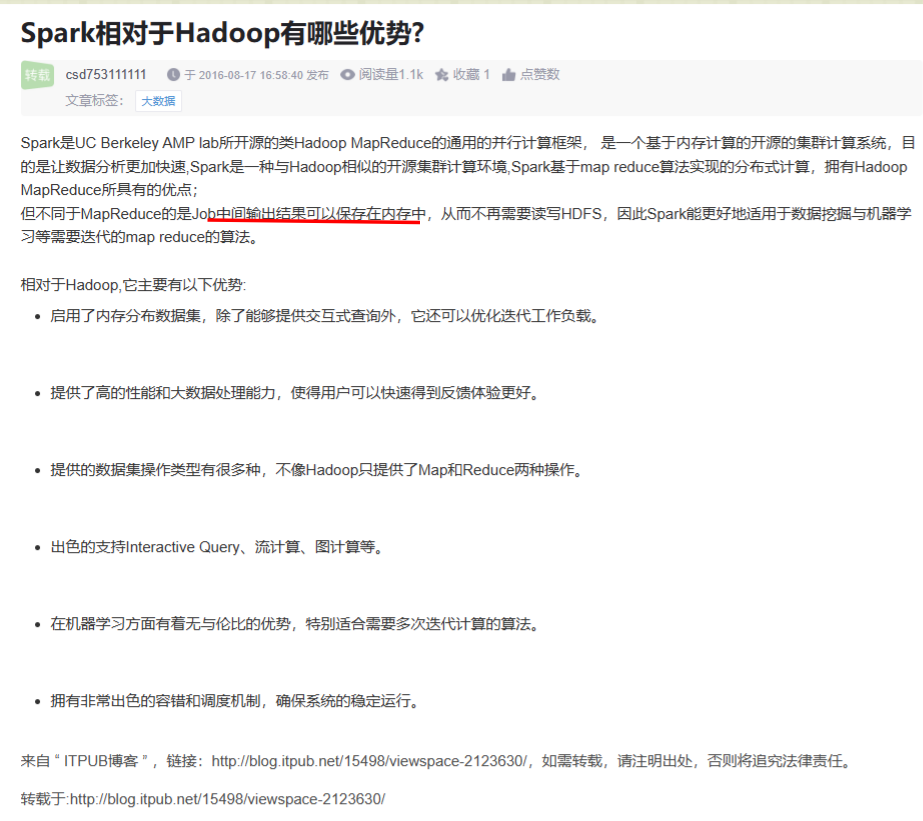
Spark相对于Hadoop有哪些优势?
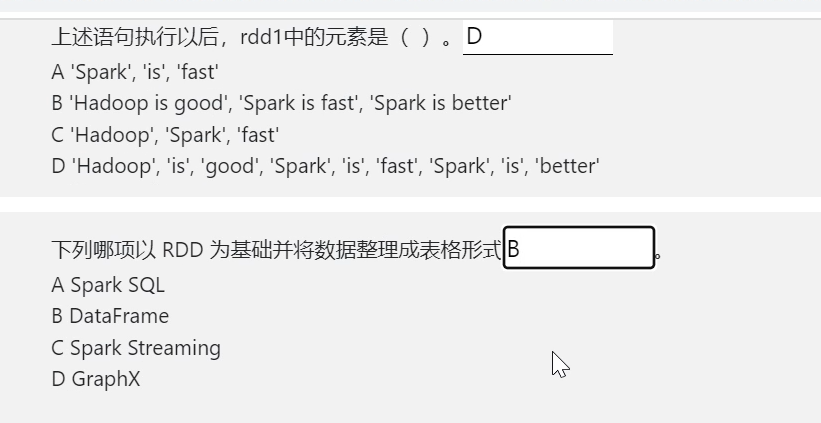
RDD和DataFrame有什么区别?

RDD是弹性分布式数据集,数据集的概念比较强一点。容器可以装任意类型的可序列化元素(支持泛型)
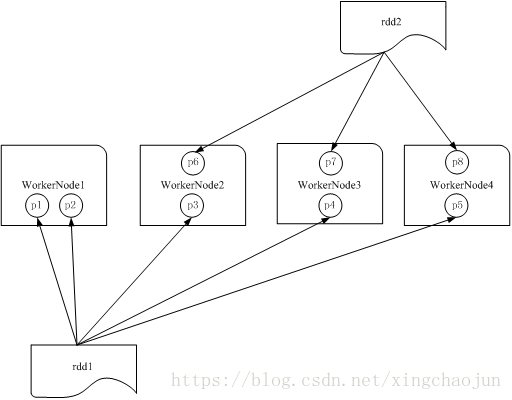
RDD的缺点是无从知道每个元素的【内部字段】信息。意思是下图不知道Person对象的姓名、年龄等。

DataFrame也是弹性分布式数据集,但是本质上是一个分布式数据表,因此称为分布式表更准确。DataFrame每个元素不是泛型对象,而是Row对象。
DataFrame的缺点是Spark SQL DataFrame API 不支持编译时类型安全,因此,如果结构未知,则不能操作数据;同时,一旦将域对象转换为Data frame ,则域对象不能重构。
DataFrame=RDD-【泛型】+schema+方便的SQL操作+【catalyst】优化
DataFrame本质上是一个【分布式数据表】

DataFrame优于RDD,因为它提供了内存管理和优化的执行计划。总结为以下两点:
a.自定义内存管理:当数据以二进制格式存储在堆外内存时,会节省大量内存。除此之外,没有垃圾回收(GC)开销。还避免了昂贵的Java序列化。因为数据是以二进制格式存储的,并且内存的schema是已知的。
b.优化执行计划:这也称为查询优化器。可以为查询的执行创建一个优化的执行计划。优化执行计划完成后最终将在RDD上运行执行。
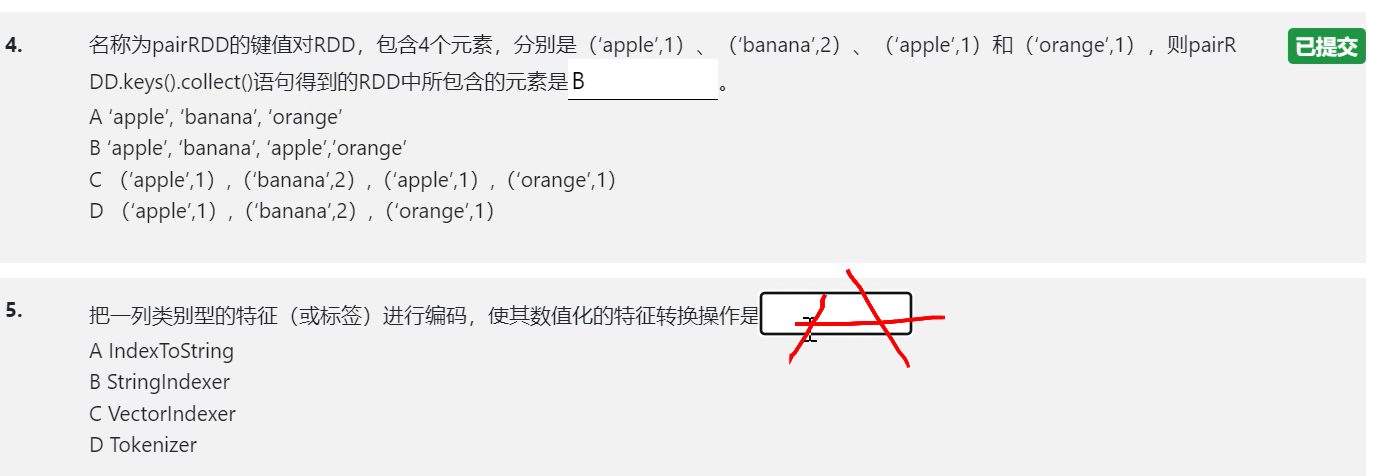
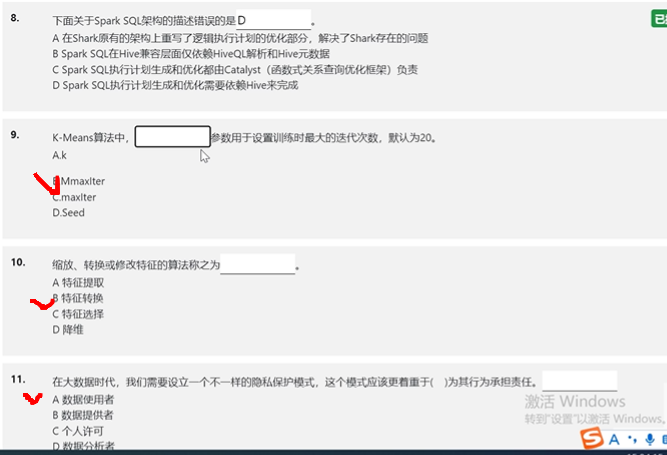
选择


T填空