爬虫案例—根据四大名著书名抓取并存储为文本文件
诗词名句网:https://www.shicimingju.com
目标:输入四大名著的书名,抓取名著的全部内容,包括书名,作者,年代及各章节内容
诗词名句网主页如下图:

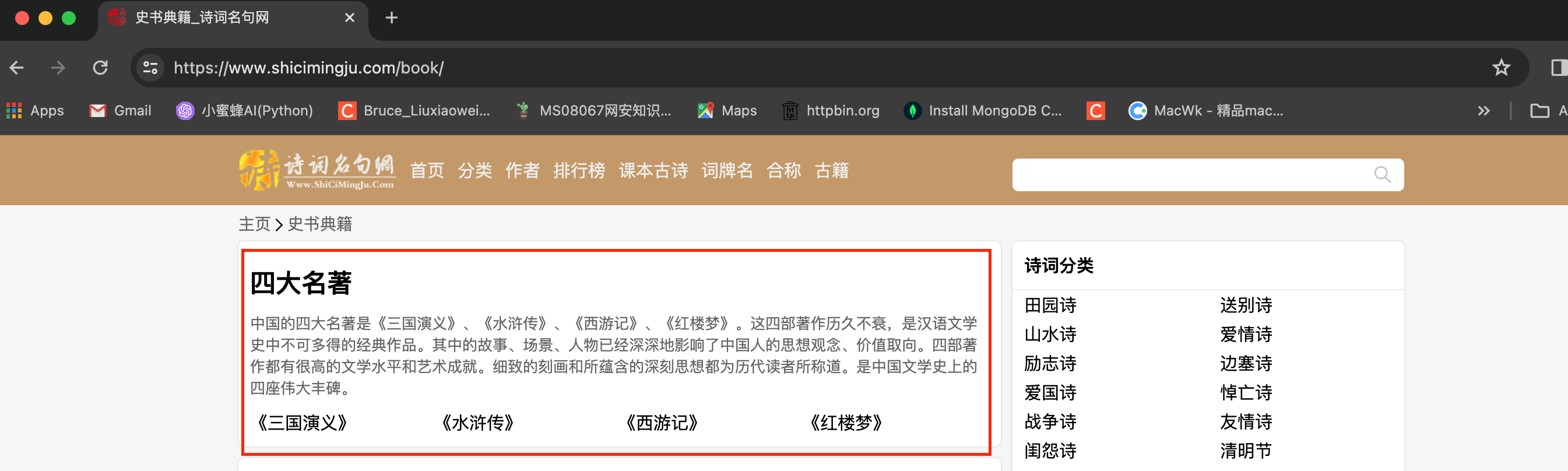
今天的案例是抓取古籍板块下的四大名著,如下图:
 案例源码如下:
案例源码如下:
import time
import requests
from bs4 import BeautifulSoup
import random
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36', }
# 获取响应页面,并返回实例化soup
def get_soup(html_url):
res = requests.get(html_url, headers=headers)
res.encoding = res.apparent_encoding
html = res.content.decode()
soup = BeautifulSoup(html, 'lxml')
return soup
# 返回名著的书名及对应的网址字典
def get_book_url(page_url):
book_url_dic = {
}
soup = get_soup(page_url)
div_tag = soup.find(class_="card booknark_card")
title_lst = div_tag.ul.find_all(name='li')
for title in title_lst:
book_url_dic[title.a.text.strip('《》')] = 'https://www.shicimingju.com' + title.a['href']
return book_url_dic
# 输出每一章节内容
def get_chapter_content(chapter_url):
chapter_content_lst = []
chapter_soup = get_soup(chapter_url)
div_chapter = chapter_soup.find(class_='card bookmark-list')
chapter_content = div_chapter.find_all('p')
for p_content in chapter_content:
chapter_content_lst.append(p_content.text)
time.sleep(random.randint(1, 3))
return chapter_content_lst
# 主程序
if __name__ == '__main__':
# 古籍板块链接
gj_url = 'https://www.shicimingju.com/book'
url_dic = get_book_url(gj_url)
mz_name = input('请输入四大名著名称: ')
mz_url = url_dic[mz_name]
soup = get_soup(mz_url)
abbr_tag = soup.find(class_="card bookmark-list")
book_name = abbr_tag.h1.text
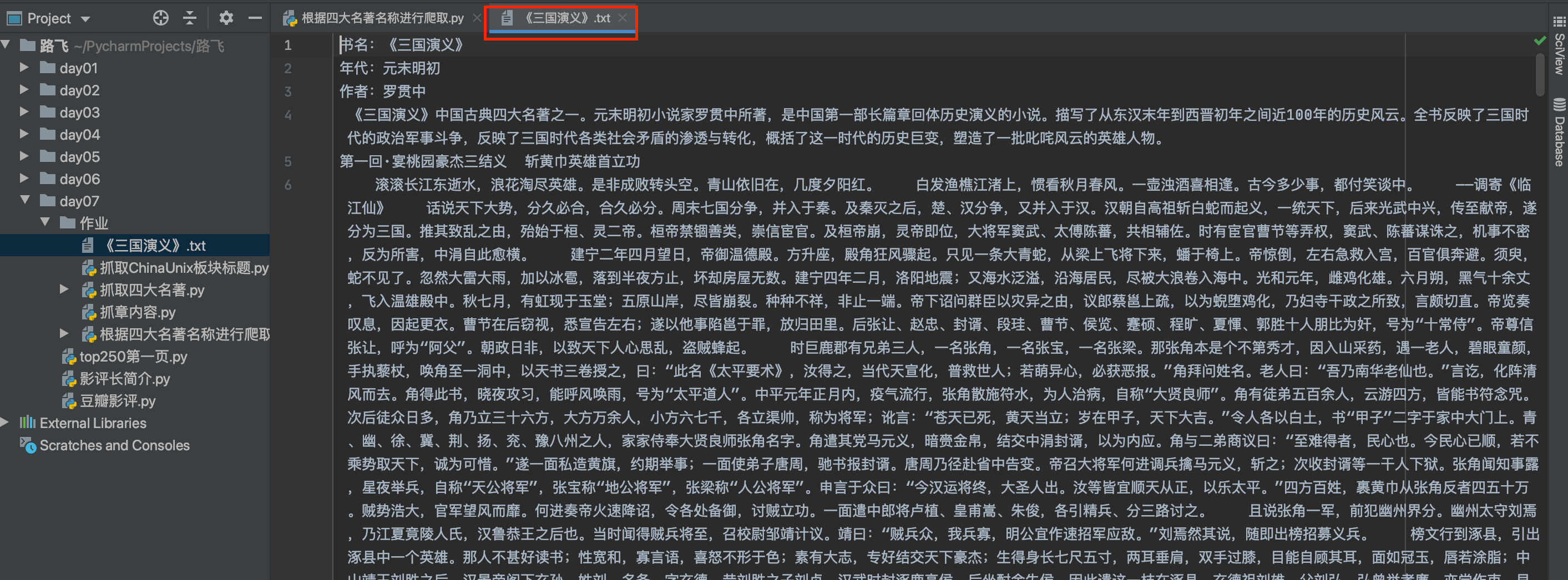
f = open(f'{
book_name}.txt', 'a', encoding='utf-8')
f.write('书名:'+book_name+'\n')
print('名著名称:', book_name, end='\n')
p_lst = abbr_tag.find_all('p')
for p in p_lst:
f.write(p.text+'\n')
mulu_lst = soup.find_all(class_="book-mulu")
book_ul = mulu_lst[0].ul
book_li = book_ul.find_all(name='li')
for bl in book_li:
print('\t\t', bl.text)
chapter_url = 'https://www.shicimingju.com' + bl.a['href']
f.write(bl.text+'\n')
f.write(''.join(get_chapter_content(chapter_url))+'\n')
f.close()

























![[C#]winform部署openvino官方提供的人脸检测模型](https://img-blog.csdnimg.cn/direct/3ba91b7e5e204a1681ee6dd9815e4af4.jpeg)