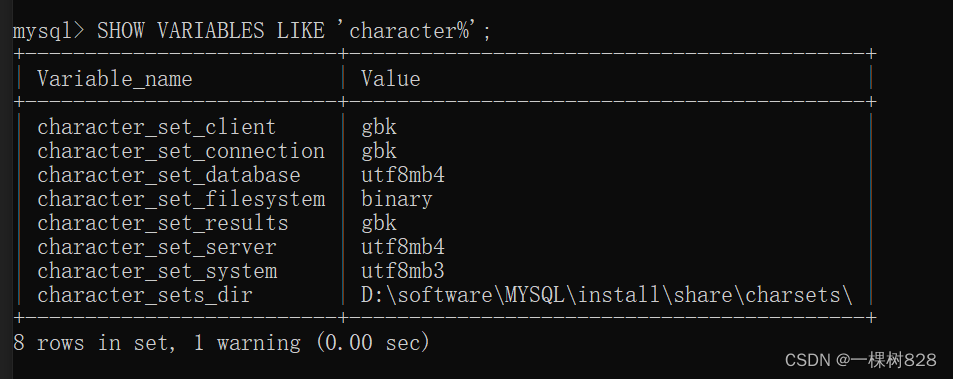
爬虫—响应页面乱码问题解决方法
案例:腾牛网图片抓取
源代码如下:
import requests
url = 'https://www.qqtn.com/wm/meinvtp_1.html'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers
data = res.content.decode()
print(data)
执行之后,报错如下:

解决办法:
- 方法一,设置解码格式为’GBK’
data = res.content.decode('GBK')
print(data)
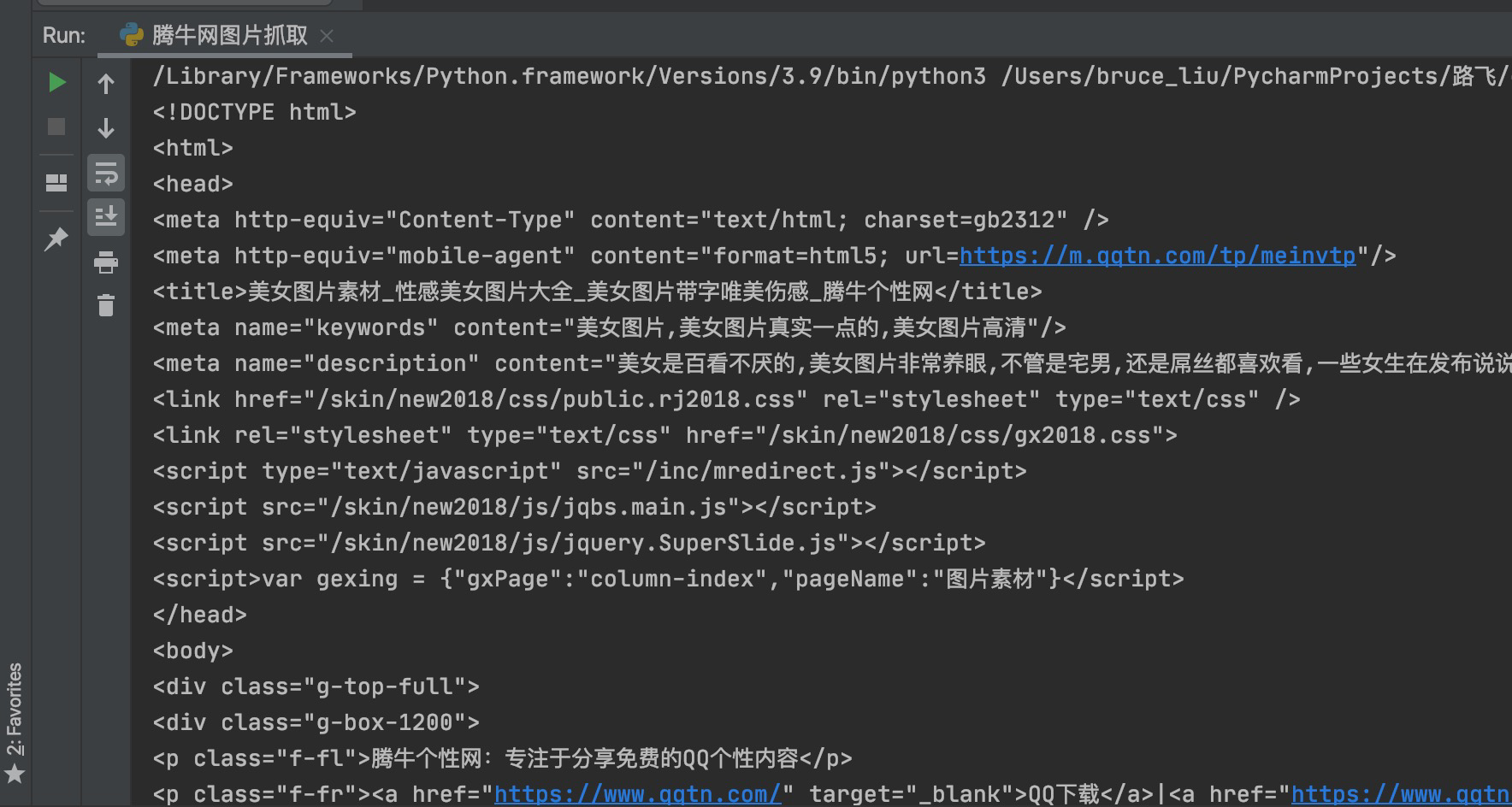
运行结果如下:
- 方法二,自动获取解码格式
# 自动获取解码格式
res.encoding = res.apparent_encoding
data = res.text
print(data)






















![OPC UA 开源库编译方法及通过OPC UA连接西门S7-1200 PLC通信并进行数据交换[一]](https://img-blog.csdnimg.cn/direct/93777ae2548a46c388150ad2e1473968.png)


![[DL]深度学习_Feature Pyramid Network](https://img-blog.csdnimg.cn/direct/2572025fb854498985d157a7af9d05b9.png)