Scrapy是一个Python编写的开源网络爬虫框架,它由五大核心组件构成:引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)。
引擎(Engine):它是Scrapy的核心,负责控制整个爬虫流程的运行,包括调度器、下载器和管道等组件的协调工作。
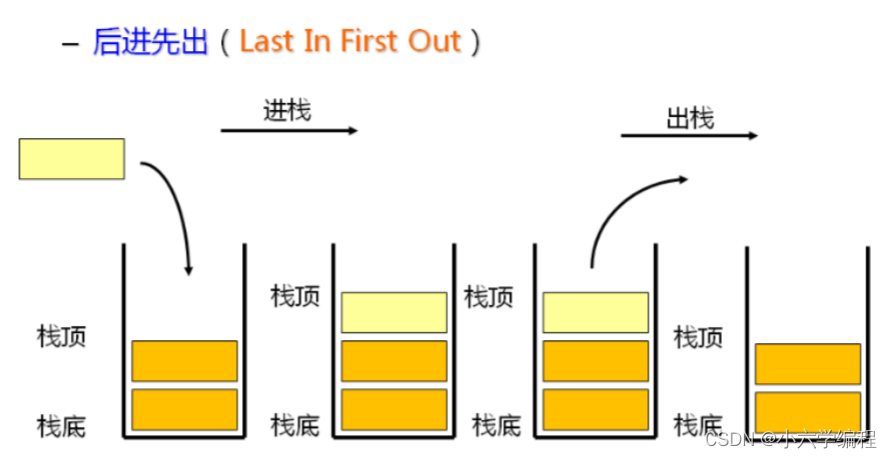
调度器 (Scheduler):它是一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址,以避免做无用功。用户可以根据自己的需求定制调度器。
下载器 (Downloader):它是所有组件中负担最大的,用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的。
爬虫(Spider):爬虫是Scrapy抓取网页并从中提取数据的程序。用户可以编写自己的爬虫程序来抓取特定网站的数据。
实体管道 (Item Pipeline):它的主要任务是处理从爬虫中提取出来的数据,对数据进行清洗和存储。
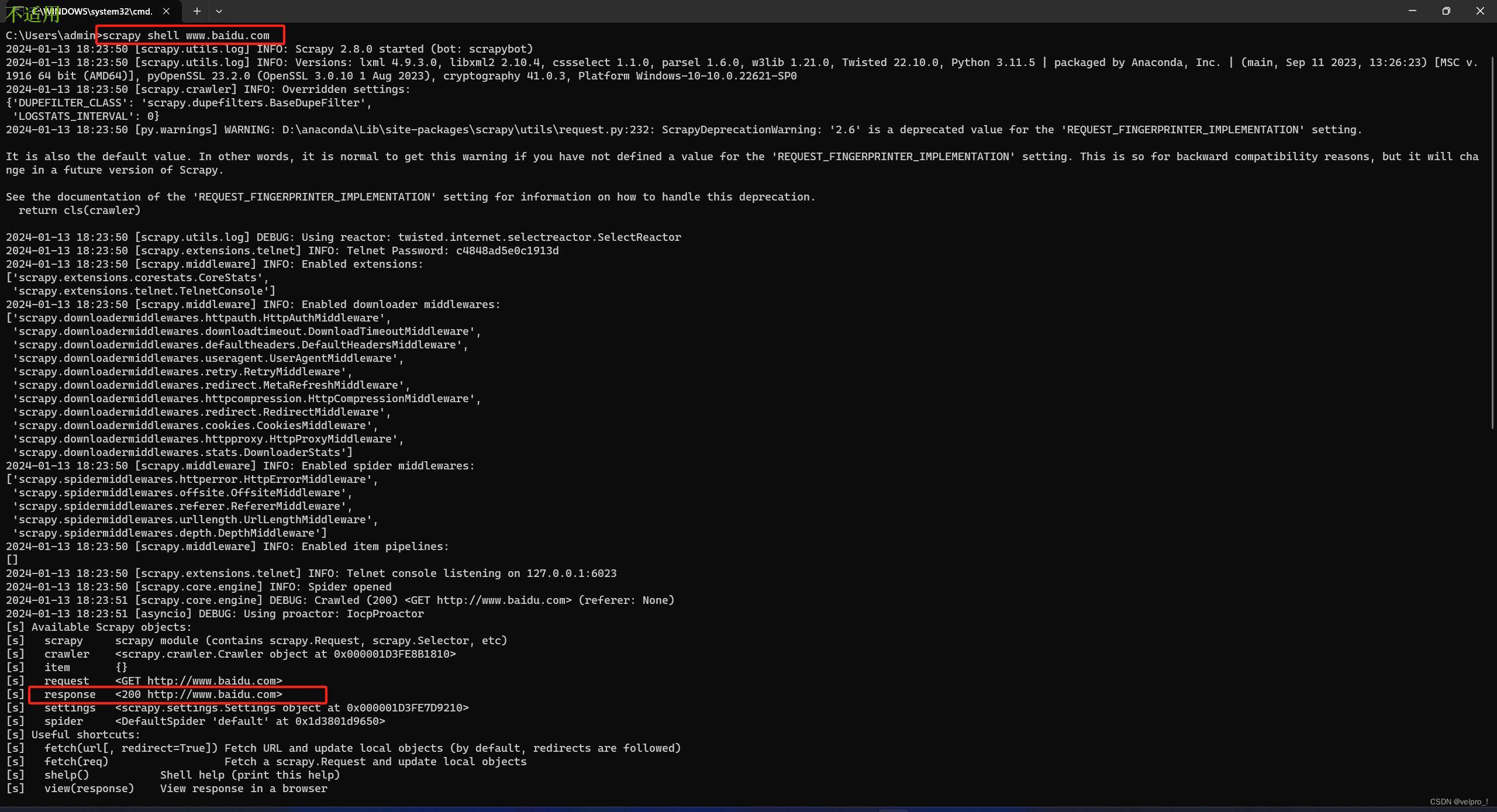
scrapy工作原理:
1、引擎向spiders要url
2、引擎将要爬取的url给调度器
3、调度器会将url生成请求对象放入到指定的队列中
4、从队列中出队一个请求
5、引擎将请求交给下载器进行处理
6、下载器发送请求获取互联网被据
7、下载器将数据返回给引肇
8、引擎将数据再次始到spiders
9、spiders通过xpath解析该数据,得到数据或者url
10、spiders将数据或url给到引擎
11、引擎判断是数据还是url,是数据,交给管道(item pipeline)处理,是ulr交给调度器处理