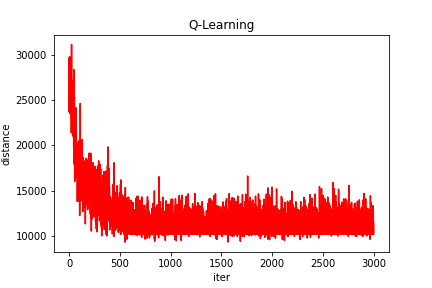
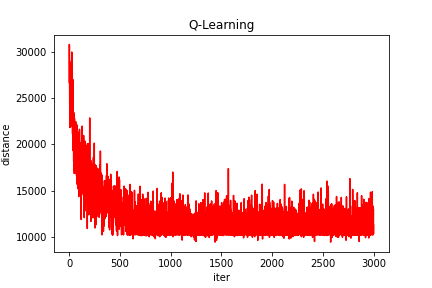
$documents阶段可以根据输入值返回字面意义的文档。
语法
{
$documents: <表达式> }
$documents接受可解析为对象数组的任何有效表达式,包括:
系统变量,如
$$NOW或$$SEARCH_META$let表达式$lookup表达式作用域中的变量
没有指向当前文档的表达式(如 $myField 或 $$ROOT)将导致错误。
举例
测试管道阶段
下面例子为管道阶段创建测试和调试数据,无需创建测试集合。
db.aggregate(
[
{
$documents: [ {
x: 10 }, {
x: 2 }, {
x: 5 } ] },
{
$bucketAuto: {
groupBy: "$x", buckets: 4 } }
]
)
聚合表达式不指定集合。它使用$documents阶段中的输入数据作为$bucketAuto阶段的输入。
[
{
_id: {
min: 2, max: 5 }, count: 1 },
{
_id: {
min: 5, max: 10 }, count: 1 },
{
_id: {
min: 10, max: 10 }, count: 1 }
]
在 $lookup 阶段使用 $documents 阶段
使用$documents修改$lookup的输出。
创建locations集合:
db.locations.insertMany(
[
{
zip: 94301, name: "Palo Alto" },
{
zip: 10019, name: "New York" }
]
)
使用$documents作为数据源来转换文件。
db.locations.aggregate(
[
{
$match: {
} },
{
$lookup:
{
localField: "zip",
foreignField: "zip_id",
as: "city_state",
pipeline:
[
{
$documents:
[
{
zip_id: 94301, name: "Palo Alto, CA" },
{
zip_id: 10019, name: "New York, NY" }
]
}
]
}
}
]
)
输出将locations集合中的数据与$documents管道阶段中的值相关联。
[
{
_id: ObjectId("618949d60f7bfd5f5689490d"),
zip: 94301,
name: 'Palo Alto',
city_state: [ {
zip_id: 94301, name: 'Palo Alto, CA' } ]
},
{
_id: ObjectId("618949d60f7bfd5f5689490e"),
zip: 10019,
name: 'New York',
city_state: [ {
zip_id: 10019, name: 'New York, NY' } ]
}
]
zip字段对应zip_id字段as参数会创建一个新的输出字段







![[C++]——同步异步日志系统(3)](https://img-blog.csdnimg.cn/direct/6927dea6f7854ecaad59bd69b9bb44b4.png)