模型概述
LLaMA-VID模型的主要目标是解决现有视觉语言模型在处理长时视频时遇到的挑战。这些挑战主要包括处理大量视觉特征所需的高计算资源以及信息的复杂性和冗余性。为了克服这些难题,LLaMA-VID采用了创新的方法,有效地减少了长时视频中无关紧要信息的数量,同时保留了最核心和有意义的信息。
Huggingface模型下载:https://huggingface.co/YanweiLi
AI快站模型免费加速下载:https://aifasthub.com/models/YanweiLi
技术方案
LLaMA-VID模型采用了两个关键的Token来表示每一帧或每一张图像:一个上下文标记(Context Token)和一个内容标记(Content Token)。上下文标记用于编码整个图像或视频中最相关或最重要的部分,而内容标记则捕捉每一帧中具体存在或发生过的事物。这种方法不仅减少了长时视频中信息的复杂度,还提高了信息处理的效率和准确性。

性能指标
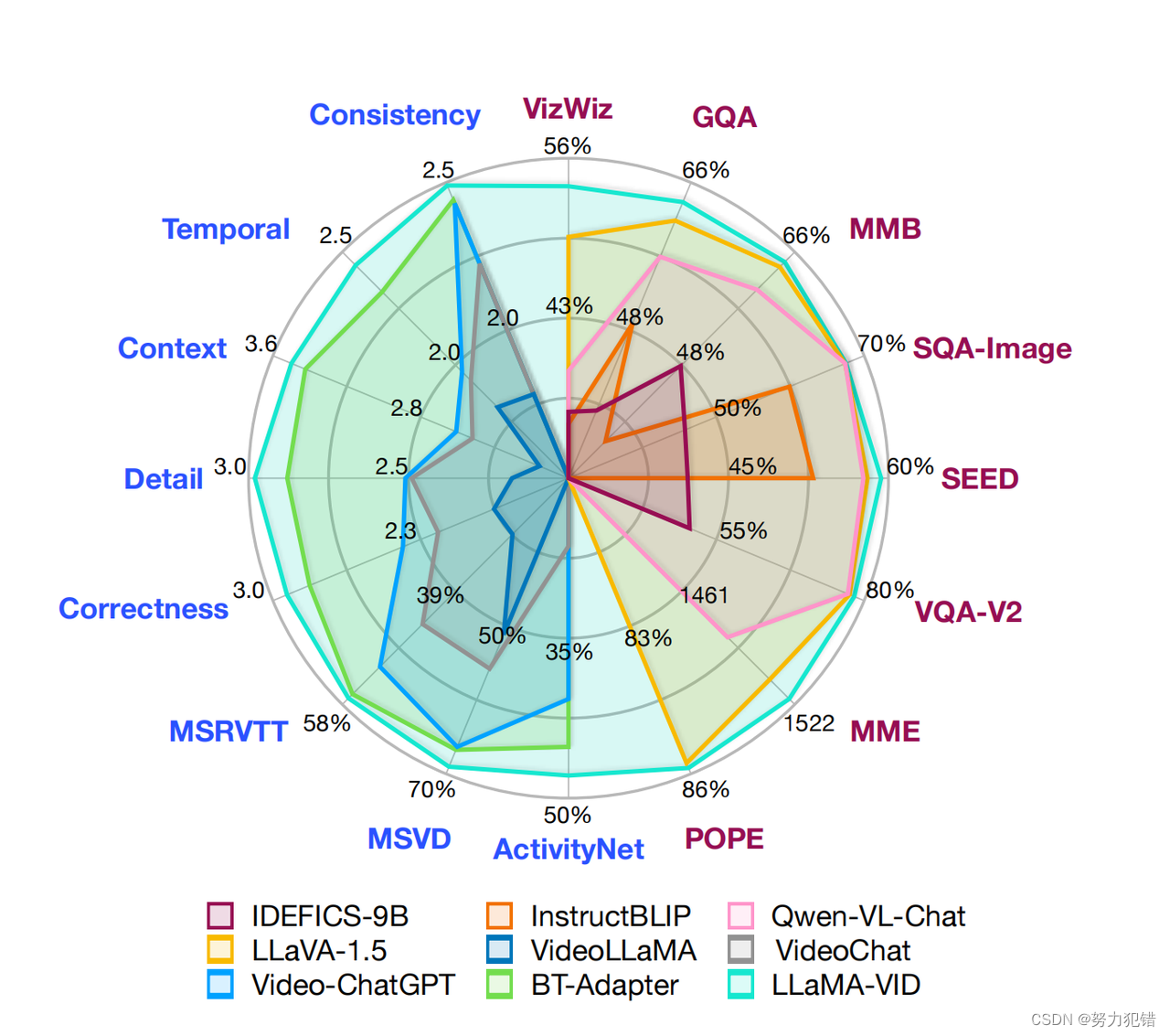
LLaMA-VID模型在处理长时视频方面展现出卓越的性能。它能够处理三种形式的内容:单图片、短视频和长视频。在多个评估榜单上,LLaMA-VID实现了最先进的(State of the Art,SOTA)性能,特别是在长时视频的理解和分析方面。

应用场景
LLaMA-VID模型的应用场景广泛,它可以用于生成图像描述、图像问答、图像摘要等内容。具体来说,该模型能够分析和回答与长时视频内容相关的复杂问题,例如电影情节的总结和理解、角色分析、情感分析等。这使得LLaMA-VID成为一种强大的工具,适用于电影制作、内容创作、娱乐分析和教育等领域。

结论
LLaMA-VID模型的开发不仅推动了视觉语言模型的技术进步,还为长时视频内容的分析和理解提供了新的可能性。它通过创新的技术方案,有效地解决了长时视频处理的挑战,展现出对复杂视频内容的深入理解能力。这一成就标志着在AI领域,特别是在视觉和语言处理方面的一个重要突破。
模型下载
Huggingface模型下载
https://huggingface.co/YanweiLi
AI快站模型免费加速下载
https://aifasthub.com/models/YanweiLi