文章目录
1 摘要
1.1 核心
提出一个仅需要self attention + linear组合成encoder+decoder的模型架构
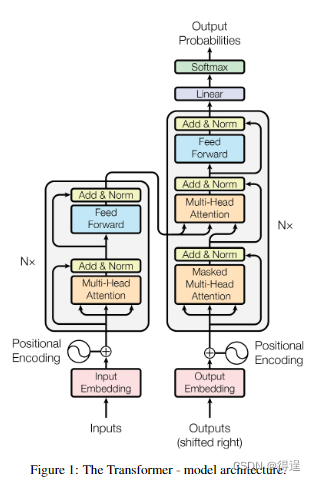
2 模型架构
2.1 概览
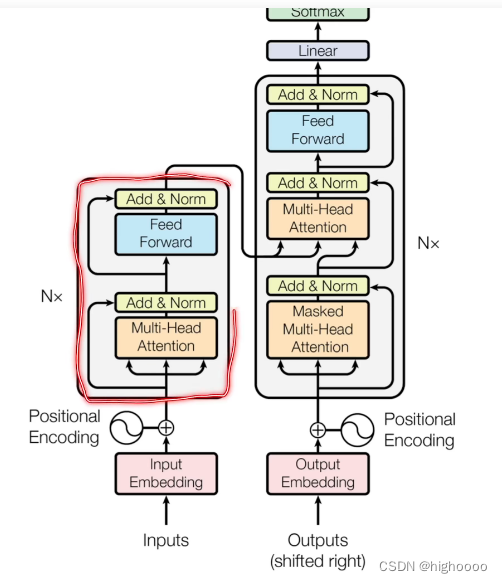
2.2 理解encoder-decoder架构
2.2.1 对比seq2seq,RNN
Self Attention
- 输入token转为特征输入
- shape [n(序列长度), D(特征维度)] 输入
- 进入attention模块
- 输出 shape [n(序列长度), D1(特征维度)] 此时每个D1被N个D做了基于attention weight的加权求和
- 进入MLP
- 输出 shape [n(序列长度), D2(输出维度)] 此时每个D2被D2和MLP weight矩阵相乘
- 每个D2转换为输出token
RNN
- 34步去除,并将每次MLP的输入修改为前一个Kt-1组合Kt输入
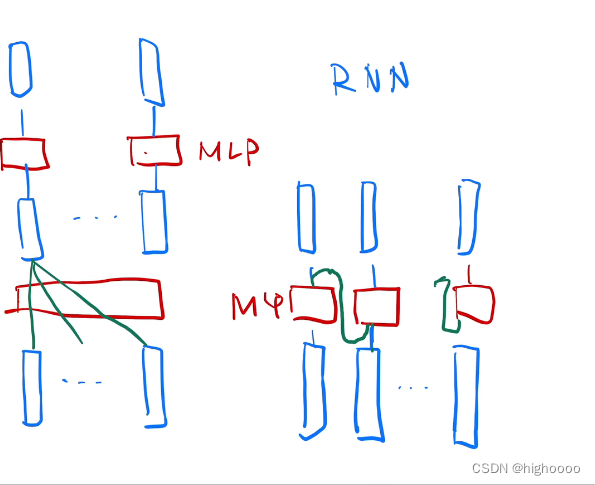
2.2.2 我的理解
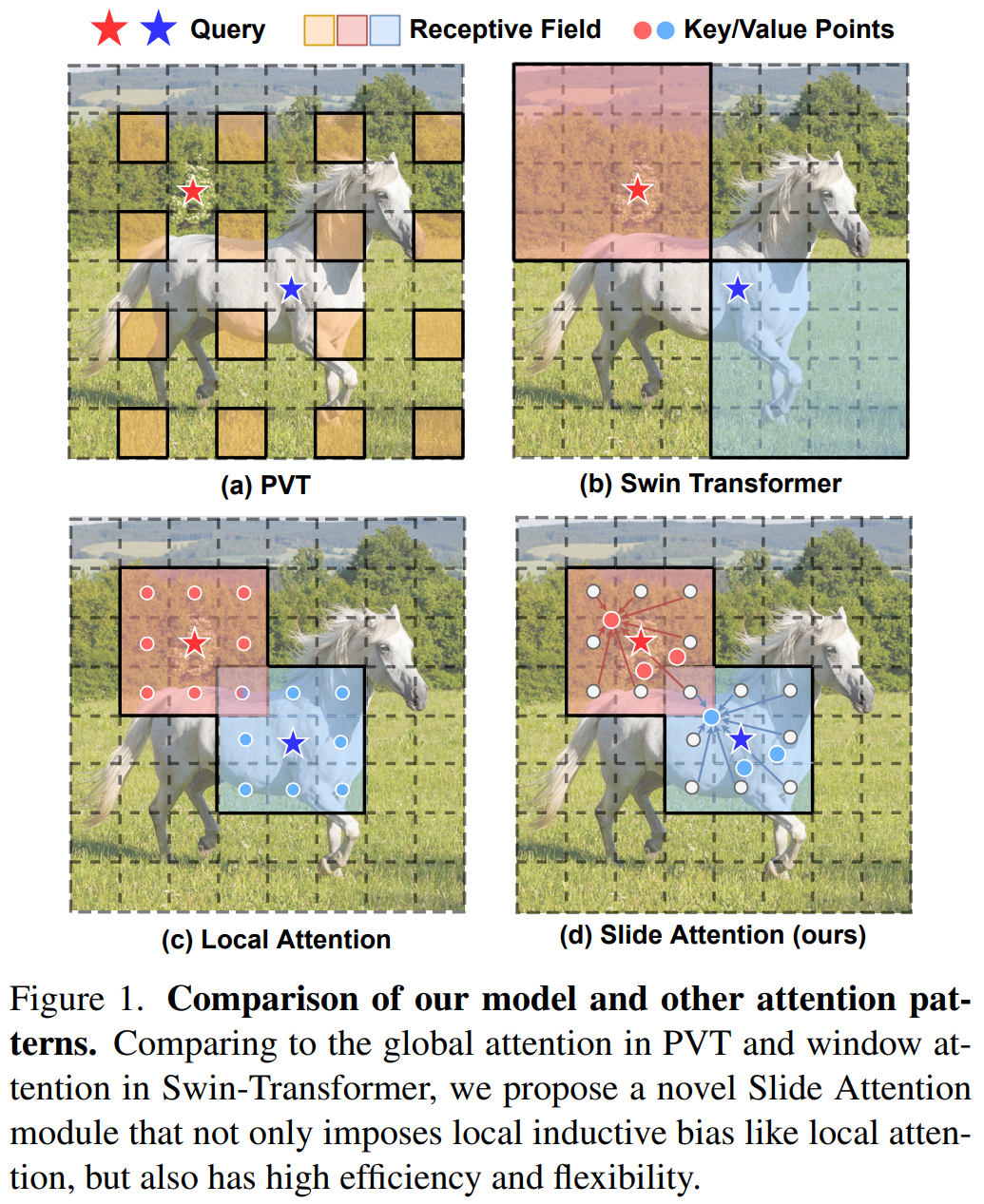
把卷积核的滑动窗口修改成了不用滑动的全局大小窗口,但同时能高效的进行(1次矩阵乘法)特征提取。
CNN可以多通道拓展(增加)特征表征方式(修改卷积核个数),自注意力需要增加多头机制。
3. Sublayer
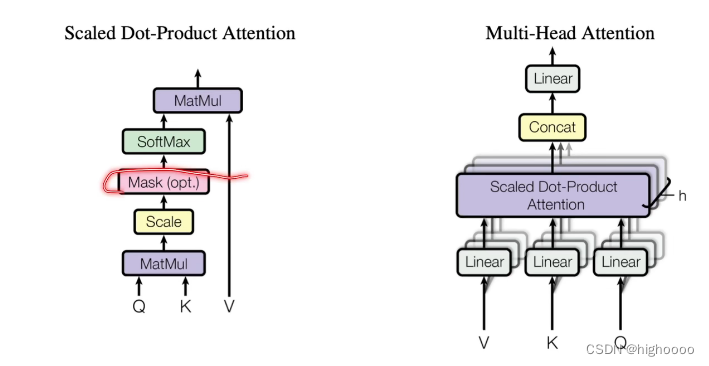
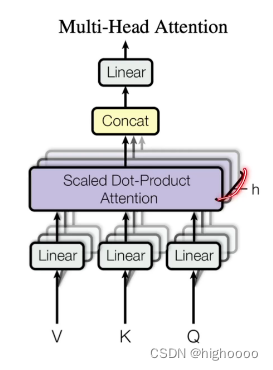
3.1 多头注意力 multi-head self-attention
3.1.1 缩放点乘注意力 Scaled Dot-Product Attention
得到query和字典KV里的softmax相似度矩阵
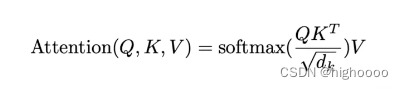
3.1.2 QKV
Q: 描述特征
K: 特征编号
V: 特征值
Attention(Q,K): 表示Query和Key的匹配程度(系统中商品(Key)很多,其中符合我的描述(Query)的商品的匹配程度会高一点)
键是唯一标识 值是该positional input的隐式特征 query是一个新的positional input 找到和query比较相似的值 解放局部特征提取 实现全局特征提取 输出最后的query的最后一层特征向量 加上需要的head 构建模型
理解自注意力和QKV
3.1.3 multi-head
原因
1.attention可学习参数太少,增加线性层学习参数
2.类比CNN扩展通道数
使得输出的相似度矩阵是考虑了多种特征形式的。
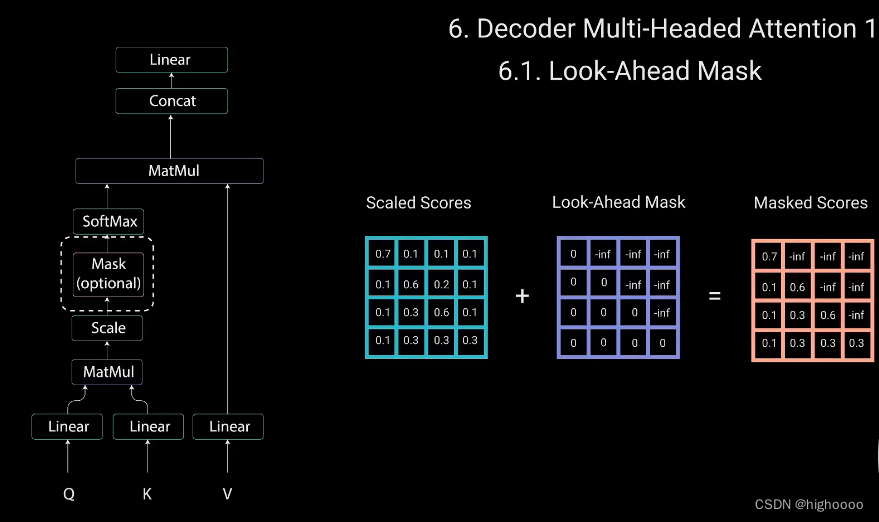
3.1.4 masked
3.2 线性层 MLP
3.3 embedding and softmax
Label Smoothing
0 - 1 标签,softmax很难趋近为1。很soft,输出值很大,才会激活为1。
正确的词,softmax的输出为 0.1 即可,剩下的值是 0.9 / 字典大小
损失 perplexity,模型的困惑度(不确信度)、log(loss)做指数。因为正确的标签只需要给到 10 %。
模型不那么精确,可以提高 accuracy and BLEU score
3.4 positional encoding
输入的token在经过特征编码后,会和位置编码相加,我的理解是位置编码就是一种特征,是一种和特征编码等价的东西,所以直接做加法。
具体的加上了cos/sin函数,将值缩到0-1(?)之间,和特征编码的最大最小值相同,然后相加。
这个是对2D的位置编码,其中考虑的行列分别进行编码为2/d组合成d。
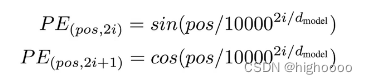
3.5 dropout
线性层用了大量dropout(0.1-0.3)
总结
从语言模型来说,通过全局注意力机制,优化掉RNN的短记忆缺点。
从模型架构来说,通过全局注意力机制,得到一个每个权重都考虑到所有输入特征的模型架构/特征提取机制/backbone。
附
李沐b站 对该论文理解的一些题目和答案
归一化,标准化,正则化
归一化(Normalization):
使用方法: 归一化通常指对输入数据进行缩放,使其值在特定的范围内,例如将输入归一到0,1范围或−1,1范围。
意义: 归一化有助于提高模型训练的稳定性,避免梯度爆炸或梯度消失问题。常见的归一化方式包括最小-最大归一化和Z分数归一化。
标准化(Standardization):
使用方法: 标准化是指对输入数据进行平移和缩放,使其均值为0,标准差为1。
意义: 标准化有助于使输入数据更易于训练,使得模型更容易收敛。在某些情况下,标准化也有助于降低不同特征的权重对模型训练的影响。
正则化(Regularization):
使用方法: 正则化是通过在模型的损失函数中引入附加项来减小模型的复杂度。L1正则化和L2正则化是两种常见的正则化方法。
意义: 正则化有助于防止过拟合,通过对模型参数的大小进行惩罚,避免模型过度依赖训练数据中的噪声或特定模式。L1正则化倾向于产生稀疏权重,而L2正则化倾向于产生较小且平滑的权重。

![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]VoxSet——Voxel Set <span style='color:red;'>Transformer</span>](https://img-blog.csdnimg.cn/direct/60f62ee88274416e859fef20b101be5f.png)