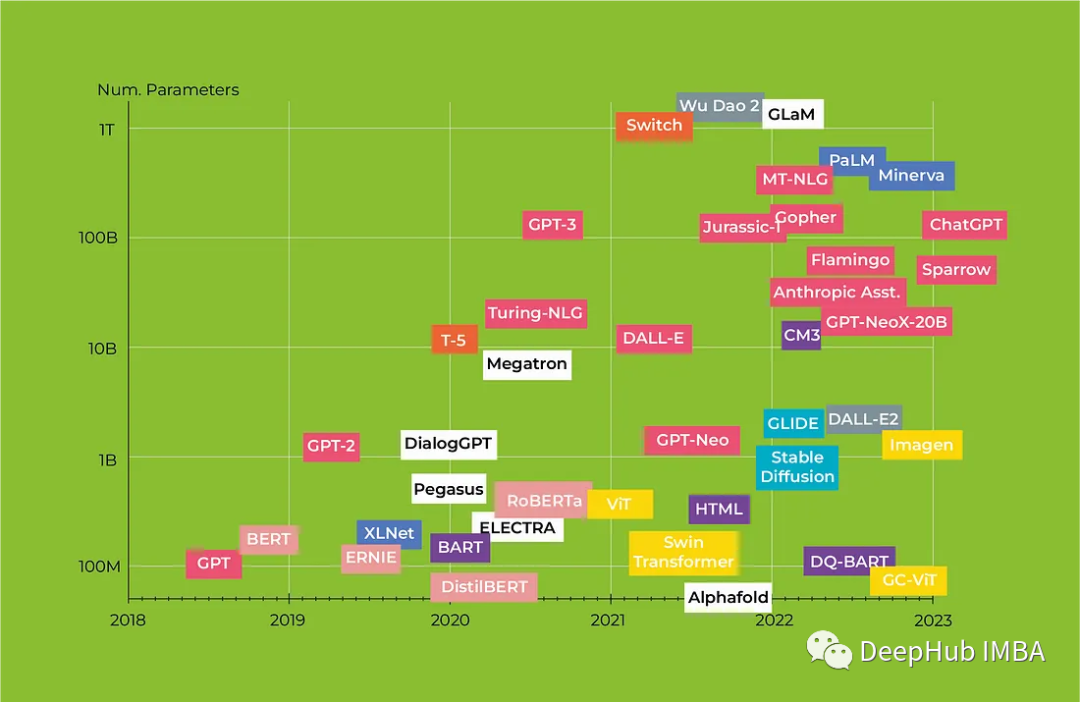
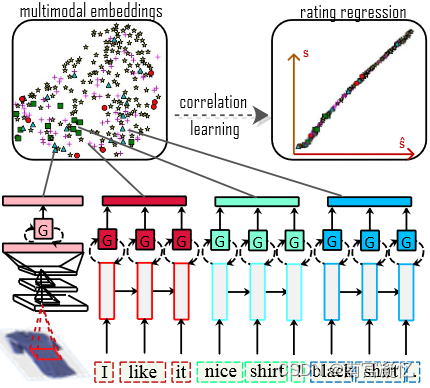
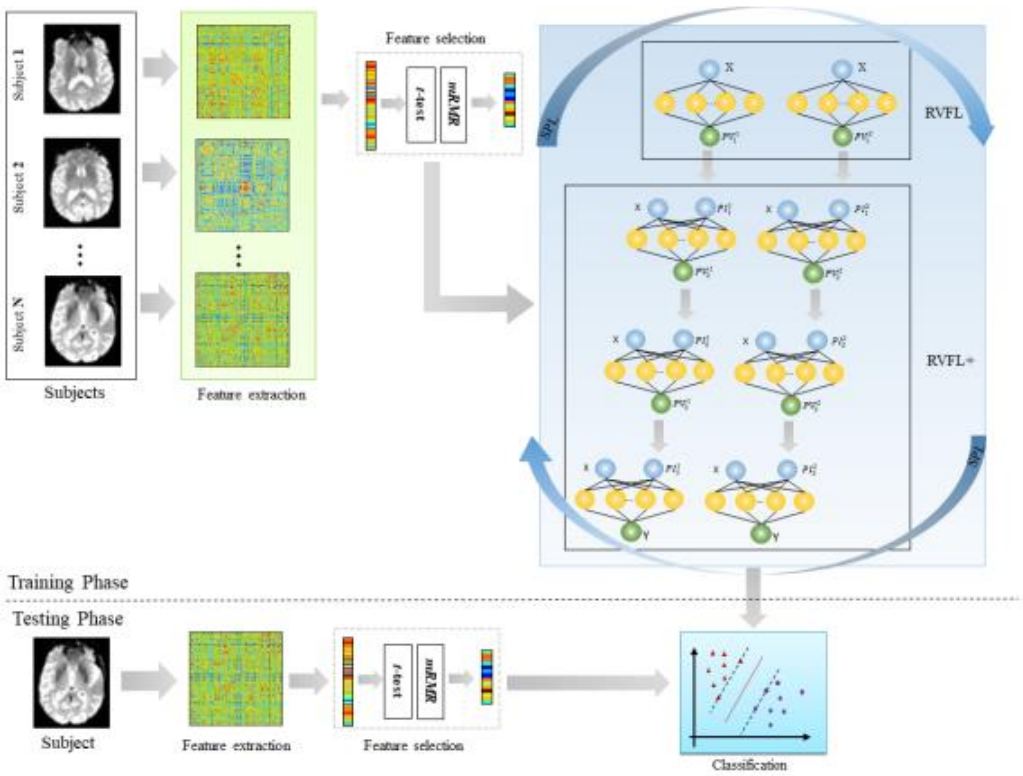
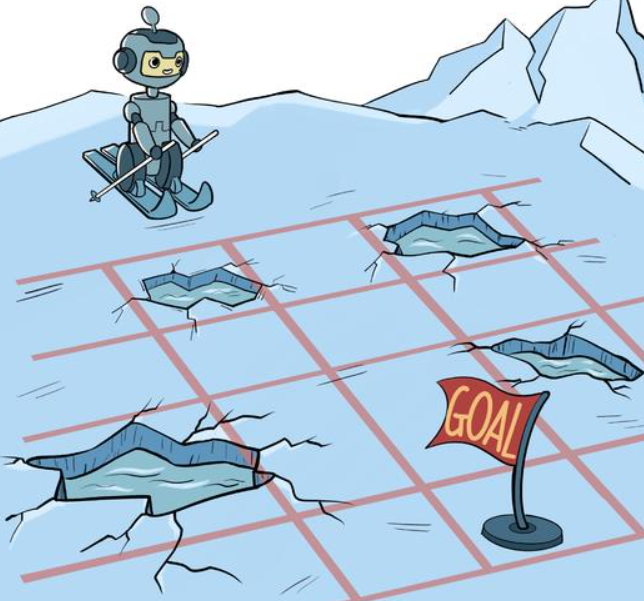
冰壶环境
环境介绍
OpenAI Gym库中包含了很多有名的环境,冰湖是 OpenAI Gym 库中的一个环境,和悬崖漫步环境相似,大小为4×4的网格,每个网格是一个状态,智能体起点状态S在左上角,目标状G态在右下角,中间还有若干冰洞H。在每一个状态都可以采取上、下、左、右 4 个动作。由于智能体在冰面行走,因此每次行走都有一定的概率滑行到附近的其它状态,并且到达冰洞或目标状态时行走会提前结束。每一步行走的奖励是 0,到达目标的奖励是 1。
代码实例
通过创建环境,可以找出冰洞和目标状态。
import gymnasium as gym
# 创建环境
env = gym.make('FrozenLake-v1',render_mode="ansi")
# 解封装才能访问状态转移矩阵P
env = env.unwrapped
holes=set()
ends =set()
for s in env.P:
for a in env.P[s]:
for s_ in env.P[s][a]:
# 获得奖励为1,代表是目标
if s_[2]== 1.0 :
ends.add(s_[1])
if s_[3]==True:
holes.add(s_[1])
holes=holes-ends
print("冰洞的索引:", holes)
print("目标的索引:", ends)
for a in env.P[14]: # 查看目标左边一格的状态转移信息
print(env.P[14][a])
冰洞的索引: {11, 12, 5, 7}
目标的索引: {15}
[(0.3333333333333333, 10, 0.0, False), (0.3333333333333333, 13, 0.0, False), (0.3333333333333333, 14, 0.0, False)]
[(0.3333333333333333, 13, 0.0, False), (0.3333333333333333, 14, 0.0, False), (0.3333333333333333, 15, 1.0, True)]
[(0.3333333333333333, 14, 0.0, False), (0.3333333333333333, 15, 1.0, True), (0.3333333333333333, 10, 0.0, False)]
[(0.3333333333333333, 15, 1.0, True), (0.3333333333333333, 10, 0.0, False), (0.3333333333333333, 13, 0.0, False)]
我们可以看到每个动作都会等概率“滑行”到 3 种可能的结果,我们接下来先在冰湖环境中尝试一下策略迭代算法。
# 这个动作意义是Gym库针对冰湖环境事先规定好的
action_meaning = ['<', 'v', '>', '^']
theta = 1e-5
gamma = 0.9
agent = PolicyIteration(env, theta, gamma)
agent.policyIteration()
print_agent(agent, action_meaning, [5, 7, 11, 12], [15])
策略评估进行25轮后完成
policyImprovement
策略评估进行58轮后完成
policyImprovement
状态价值:
0.069 0.061 0.074 0.056
0.092 0.000 0.112 0.000
0.145 0.247 0.300 0.000
0.000 0.380 0.639 0.000
策略:
<ooo ooo^ <ooo ooo^
<ooo **** <o>o ****
ooo^ ovoo <ooo ****
**** oo>o ovoo EEEE
价值迭代算法:
action_meaning = ['<', 'v', '>', '^']
theta = 1e-5
gamma = 0.9
agent = ValueIteration(env, theta, gamma)
agent.valueIteration()
print_agent(agent, action_meaning, [5, 7, 11, 12], [15])
价值迭代一共进行60轮
状态价值:
0.069 0.061 0.074 0.056
0.092 0.000 0.112 0.000
0.145 0.247 0.300 0.000
0.000 0.380 0.639 0.000
策略:
<ooo ooo^ <ooo ooo^
<ooo **** <o>o ****
ooo^ ovoo <ooo ****
**** oo>o ovoo EEEE
可以发现价值迭代算法的结果和策略迭代算法的结果完全一致,这也互相验证了各自的结果。





















![[足式机器人]Part2 Dr. CAN学习笔记-动态系统建模与分析 Ch02-6频率响应与滤波器](https://img-blog.csdnimg.cn/direct/96c28ff3c715406b9bd63970f8bff583.png#pic_center)