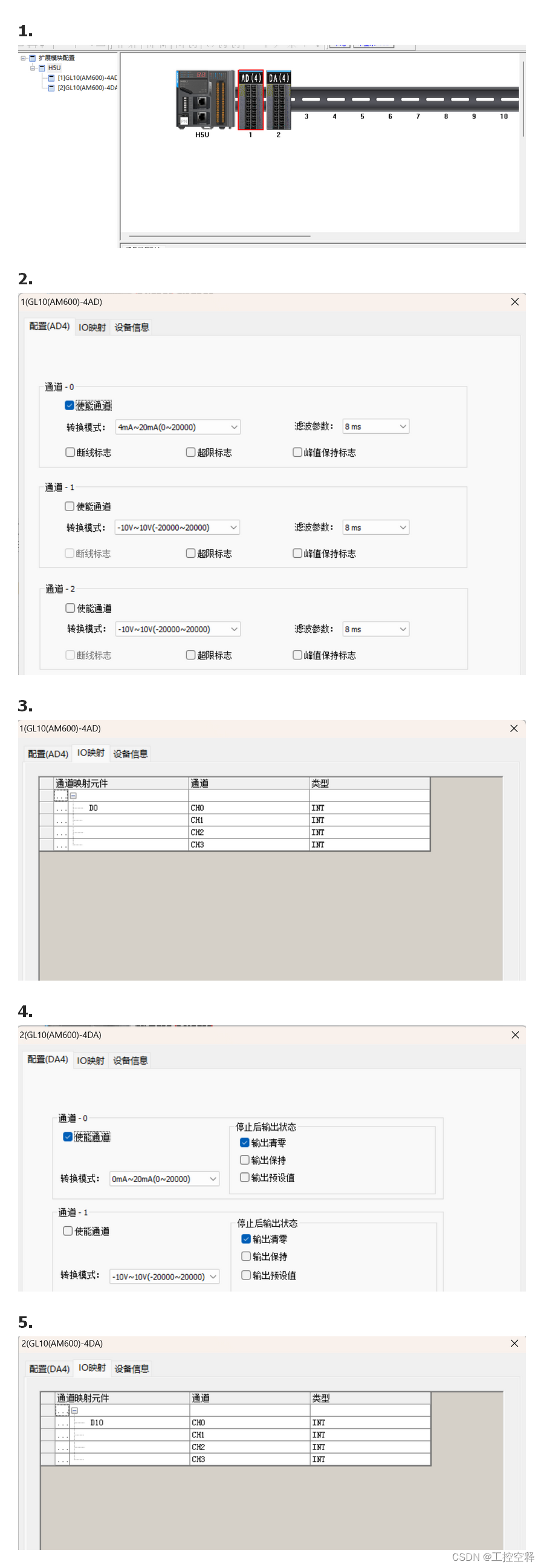
文章目录
hh
Abstract
先指出虽然通用目标检测取得了显著成功,但小目标检测的性能和效率并不能令人满意。与现有的平衡推理速度和(SOD)性能之间的权衡不同,作者提出了一种新的尺度感知知识蒸馏(ScaleKD),它将复杂的教师模型中的知识转移到紧凑的学生模型中。
为了提高SOD精馏过程中的知识转移质量,作者设计了两个新的模块:
1)尺度解耦的特征蒸馏模块:将教师的特征表示分解成多尺度嵌入,从而可以在小目标上对学生模型进行显式特征模拟。
2)提出了一种跨尺度的辅助方法来改进有噪声和无信息的边界框预测学生模型,因为这些边界框会误导学生模型,影响知识蒸馏的效果
并建立多尺度交叉注意层来捕获多尺度语义信息,以改进学生模型。
在COCO和VisDrone数据集上进行了不同类型模型(即两级和一级检测器)的实验,以评估所提出的方法
ScaleKD在一般检测性能上取得了优异的成绩,在SOD性能上取得了惊人的进步
Introduction
在SOD中使用知识蒸馏需要克服两个挑战
1)SOD通常受到噪声特征表示的影响。由于小物体的性质,通常在整个图像中占据一个小区域,这些小物体的特征表示可能会被背景和其他相对较大的实例所污染。
2)目标检测器对小物体上的噪声边界盒容忍度较低。教师模型做出不正确的预测是不可避免的。通常,学生模型可以从老师的不完美预测中提取出信息丰富的暗知识[14,28]。然而,在SOD中,教师边界上的小扰动会显著损害SOD在学生检测器上的表现。
基于此,作者提出了ScaleKD,它由两个模块组成,一个尺度解耦特征(SDF)蒸馏模块和一个跨尺度辅助(CSA)模块,以相应解决上述两个挑战
总的来说,作者提出了一种新的知识蒸馏框架ScaleKD (Scale-Aware Knowledge Distillation),它可以在不增加额外计算成本的情况下提高通用检测和SOD的性能。
KD
知识蒸馏已经成为模型压缩最有效的技术之一,它首先训练一个笨重的教师模型,然后将其知识转移到一个轻量级的学生模型中。常用的知识蒸馏方法包括对输出,logits[14],bounding box[16]和feature的蒸馏
Scale-aware Knowledge Distillation

(1)一个尺度解耦的特征蒸馏模块,显式地将不同尺度的表示传递给学生检测器。(2)跨尺度助手细化了复杂教师和紧凑学生之间的对象大小知识。
考虑一个对象检测器G S: R d→R k作为学生,另一个预测器G T: R d→R k作为教师,其中d和k是两个特征维度。前者是计算效率高但检测性能相对较低的网络,后者相反。给定一个训练数据集S = {(x i,y i) n i =1} ~ P n,用于分布P在一组实例x上。高分辨率输入图像作为教师模型、标准分辨率图像作为学生模型
Scale-Decoupled Feature Distillation
Preliminary
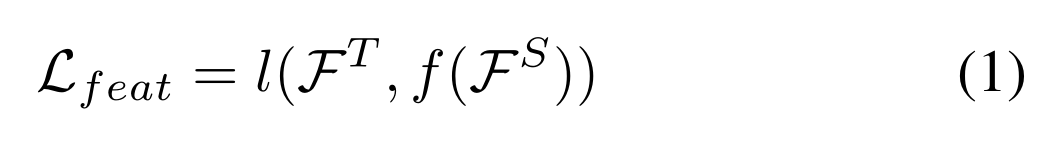
Ft和Fs是师生模型中对应的特征层。f(·)是一个映射函数,用于将学生与教师的特征映射的维度对齐,l(·)是任意有界损失,即l2范数距离。
Motivation
以往的蒸馏方法在蒸馏过程中平等地对待所有大小不同的目标,小对象的特征表示可能会受到大区域背景和其他相对较大尺寸实例的影响。
Methodology
我们的目标是将教师对象检测器的整个特征表示分解成多个部分,其中每个部分只处理相似的对象大小。据推测,这样的操作可以迫使学生检测器不仅要理解整个图像的全局知识,还要理解特定尺度的知识。
具体来说,我们在骨干的最后一阶段为老师和学生网络都获得了一个特征嵌入Zt 和 Zs。
我们打算在不同的输入尺度上充分利用特征表示。因此,我们采用多分支结构,其中每个分支使用具有不同扩张速率的卷积层。值得注意的是,该模型倾向于以较小的膨胀率关注内核的小对象,反之亦然。
通常,可以通过任意距离最小化损失,将教师模型的知识在指定的分支,即扩展率为1的3x3 Conv层,匹配到学生模型中相应的特征分支。一个缺点是这些操作可能会占用大量内存。因此,我们从神经结构搜索中的权值共享网络中汲取灵感[25,34],采用权值共享尺度解耦特征。这是基于所有三个分支都有相同的操作符这一事实。在实践中,我们只为三个分支保存了一组权值,大大降低了训练内存成本。
我们还注意到,使用三个单独的损失来匹配教师和学生模型之间的三个平行分支可能会导致练习者在超参数调谐上花费不必要的精力。因此,对于每个分支,我们使用一个平坦层,即多层感知器,并将三个平坦层连接在一起。在蒸馏过程中,我们采用单一的l2损失(在后面的部分中表示为L feat)来最小化教师和学生模型之间这个连接的扁平层的距离。提出的整体模块如图2。值得注意的是,学生的尺度解耦特征模块和教师的对应模块相同。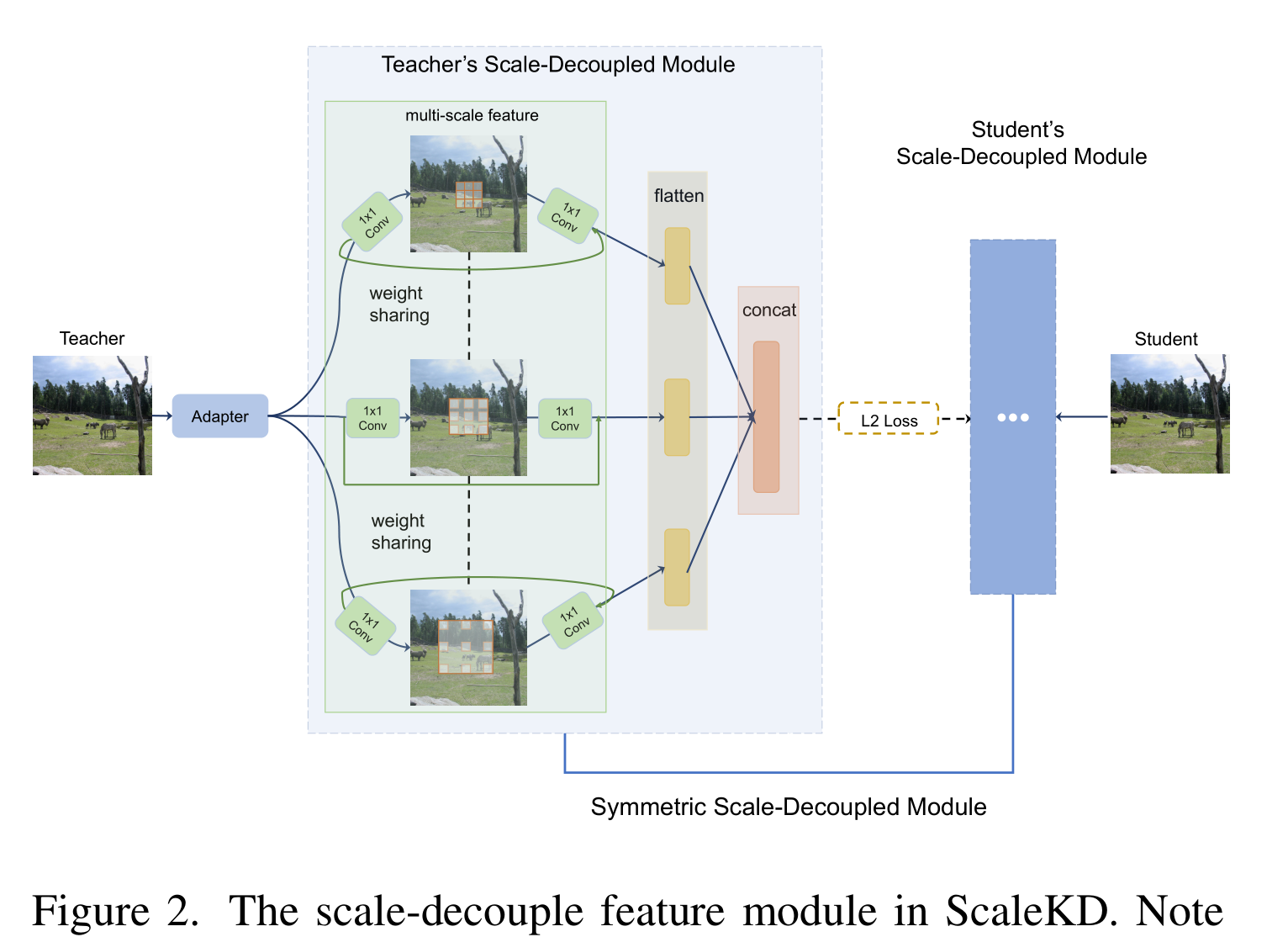
Cross-Scale Assistant
Preliminary
除了特征蒸馏之外,另一种实用的方法是基于输出的KD,它将教师对分类和定位的预测转移给学生作为辅助监督的来源。我们的工作主要集中在边界盒蒸馏,这可以被认为是一个回归问题。一般来说,回归蒸馏如下: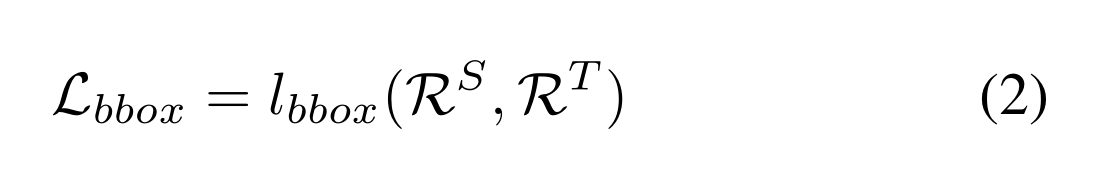
R S为学生网络的回归输出,R T是对教师网络的预测,l(·)与方程1相同,其中可以应用任何有界损失。这个有界损失可以是l1、平滑l1或l2损失,这取决于我们对学生预测和教师输出之间的误差进行加权的惩罚程度
Motivation
小目标检测与一般目标检测的一个关键区别是SOD对噪声边界框很敏感。显然,教师探测器无法对每个物体做出完美的预测。在一般的目标检测中,尽管不准确,但学生模型仍然可以从教师对边界框的预测中检索到有信息的知识。然而,对于小目标,教师模型中的噪声边界盒预测可能会混淆学生模型,从而降低SOD的性能。
作为概念证明,作者故意添加了一个轻微的偏差(沿着对角线方向6和12像素),并比较了一个vanilla老师和一个稍微受干扰的老师在小尺度物体上的mAP。如表1所示,在RetinaNet基线上,学生的小物体AP (AP S)随着扰动的增加而持续下降,说明学生检测器对教师SOD边界框预测的敏感性。因此,要构建一个值得信赖的SOD回归蒸馏模块,需要将教师毒框知识的不利影响降到最低。这并不意味着老师的预测必须是完美的——否则,我们可以直接用基本的事实来监督学生——我们只需要改进老师的输出,以确保他们的知识对学生有帮助

来自老师的嘈杂和缺乏信息的束缚盒会严重影响学生的表现。扰动由若干像素测量,并沿对角线方向添加
Methodology
为了解决上述问题,作者提出了一种跨尺度助手(Cross-Scale Assistant, CSA),它可以提炼教师的知识,使学生模型能够获取不同尺度对象上的指导性知识
方法很简单,通过一个交叉注意模块来建立CSA。在交叉关注过程中,在计算教师知识范围内的KQ-注意力时生成一系列键和查询令牌,然后与学生模型的输出值张量进行映射,从而通过每个相应的查询获得特征中的关注区域。该过程在每个学生金字塔尺度上执行,以检索基于区域的信息特征。
一种天真的选择是使用简单的交叉注意[8]。然而,先前的研究[43]发现,标准的交叉注意可以重复地集中在不同头部的显著区域。因此,当图像中出现较大的物体时,交叉注意会将注意力转移到这些较大的物体上,而忽略较小的物体。为此,与纯的交叉注意相比,我们开发了一个多尺度交叉注意层,如图3所示。
跨尺度助手(CSA)模块。我们采用多尺度查询键对对学生模型进行特征嵌入交叉关注。CSA中的可学习权值通过两个独立的分类和回归分支进行更新,这些分支由基础真值标签监督。
注意,交叉注意提取全局信息—对于每个查询键对,生成一个值以突出显示响应最迅速的区域。然后,我们将查询键对拆分为多个子对,其中每个子对表示一组对象尺度。因此,我们的多尺度查询键可以强制注意模块关注不同尺度的区域,从而使所有对象,特别是小对象都能参与到特征学习过程中。
特别地,给出一个来自老师F T∈R h×w×c的输入序列和另一个来自学生F S∈R h×w×c的输入序列,为了简单起见,我们假设两个张量具有相同的大小。将F T投影为查询(Q)和键(K),将F S投影为值(V)。对于以i为索引的不同头部,键K和值V被下采样到不同的大小。因此,我们将的多尺度交叉注意(MSC)表述为:
MSC(·,r i)是用于在第i−头部聚集的MLP层,下采样率为r i, P(·)是用于投影的深度卷积层。与标准交叉注意相比,保留了更多有利于SOD的细粒度和低层次细节。
Qi = F_S * Wi_Q --> 对学生特征映射到查询向量,Wi_Q 是查询对应的权重矩阵
Ki = MSC(F_T, r_i) * Wi_K --> 对教师特征使用MSC操作后映射到键向量,Wi_K 是键对应的权重矩阵
Vi = MSC(F_S, r_i) * Wi_V --> 对学生特征使用MSC操作后映射到值向量,Wi_V 是值对应的权重矩阵
Vi + P(Vi) 将原始特征 Vi 与经过投影变换后的特征 P(Vi) 相加,实际上是组合了原始特征信息和经过深层特征提取后得到的新特征的一种方式,旨在提高模型的学习能力和表征能力。
最后,我们计算注意张量为:
dh是维度,点积缩放分数: Q * K^T / √d_h,通常对角线元素进行缩放是为了防止梯度爆炸或消失问题
CSA的目的是在教师和学生模型之间架起跨尺度信息的桥梁,以完善KD中的边界盒监督。因此,我们用分类分支和回归分支叠加头层来更新这些可学习模块的权值。在精馏中,我们将CSA在分类和回归两个分支上的知识转移给学生,而不是转移教师的输出知识。对于基于输出的蒸馏目标,我们按照[5]有两个损失函数L cls和L bbox。我们注意到,我们的方法也是对其他基于输出的方法的补充,例如LD[46],其中我们所需要做的就是简单地替换蒸馏目标。综上所述,学生模型的总训练目标为:
L det是检测器的标准训练损失,Lfeat是L2损失
除了用于优化学生检测器的蒸馏损失和检测损失外,我们还通过共享检测头进行监督,进一步保证了指导性表征质量和与学生表征的一致性。此外,CSA结合了教师和学生的特点,因此,随机初始化的学生检测器会导致CSA训练不稳定。因此,我们首先预热学生模型进行30k次迭代,因为当指导性知识没有充分优化时,它可能是有害的。学生检测器骨干在1x训练计划下冻结在早期的10k迭代中,在2x训练计划下冻结在20k迭代中。
Experiment
Results

在COCO val2017数据集上的比较,大大提高了检测性能,尤其是在APs

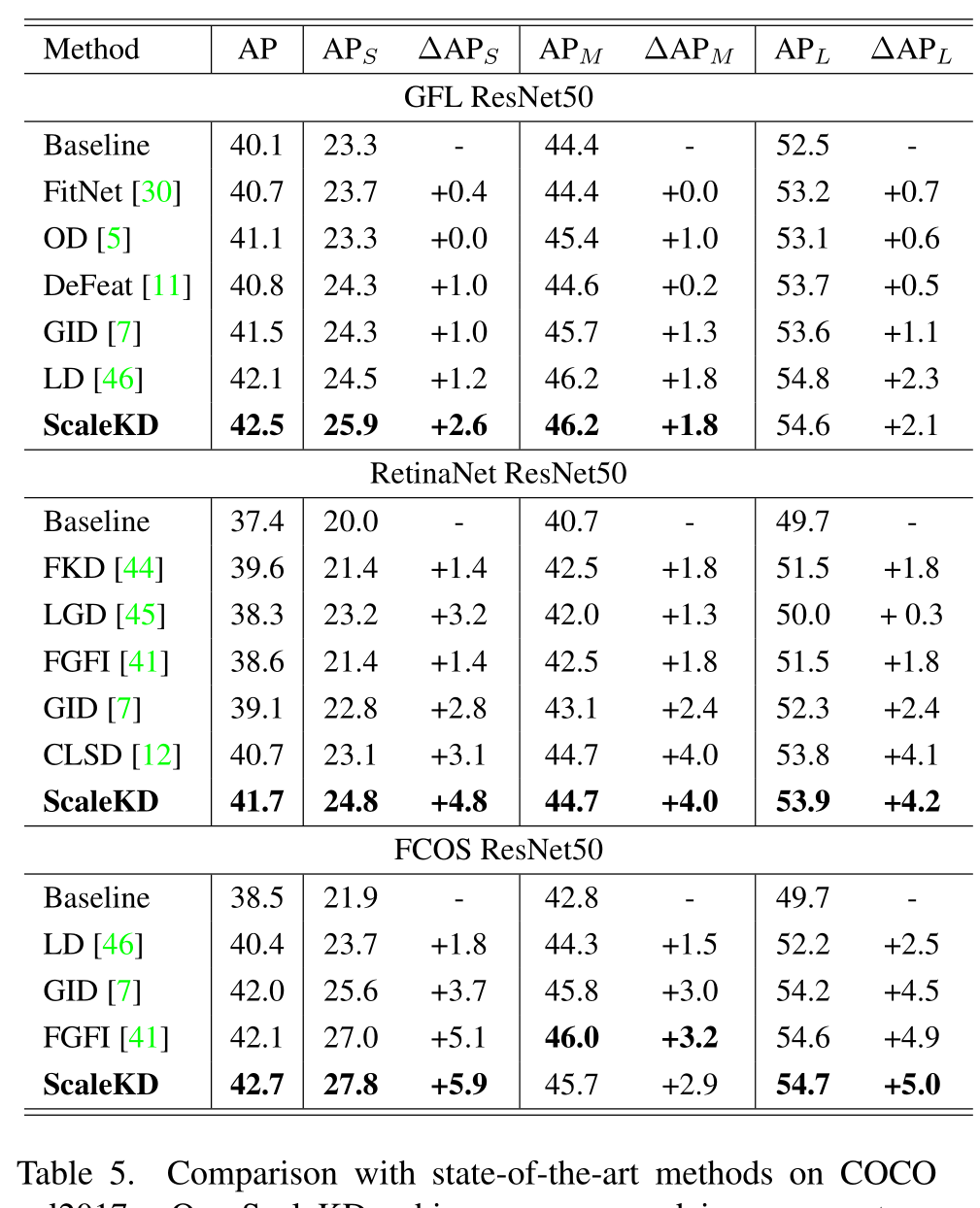
ScaleKD比SOTA在APs上实现了明显的改进
Ablation Study
可以看到在添加CSA模块后,建立多尺度交叉注意力层可以改进性能

对并行分支使用单独的权值对平均AP的改善并不明显,使用权值共享节省内存成本是ok的

Discussion
平衡小目标检测的推理速度和检测性能是一个挑战。作者提出了一种尺度感知的知识蒸馏,旨在通过设计的尺度解耦特征蒸馏和跨尺度辅助来提高SOD的性能,前者显式地解耦了多尺度特征,后者在蒸馏中精炼了教师的边界盒噪声,以获得更多信息丰富的知识。并在COCO 2017和VisDrone上进行了评估,以证明方法的有效性。