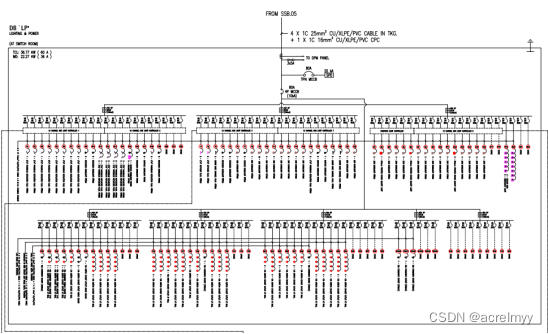
在使用 Elasticsearch 时,我们总有需要修改索引映射的时候,这时我们只能进行 _reindex。事实上,这是一个相当昂贵的操作,因为根据数据量和分片数量,完整复制一个索引可能需要几个小时。
花费的时间不是大问题,但更严重的是,它会影响生产环境的性能甚至功能。
相信大家都明白,数据迁移会消耗大量硬盘资源,肯定会影响性能,但功能呢?
让我们以常规的 _reindex 为例。假设我们在索引上创建了一个别名。如果没有别名,我们就有大麻烦了。
常规的reindex程序分为两个步骤。
1. 调用 _reindex 命令开始数据迁移。
2. 数据迁移完成后,调用 _aliases 命令在新旧索引之间切换。
步骤 2 完成后,新索引正式运行,并将负责所有读写请求。然而,这只是一个完美的理想方案,现实中的情况并非如此。
下面是一种正常情况。
实际上,在数据迁移期间或切换别名之前,客户端会继续向原始索引写入数据,这些新的更改不会迁移到新索引,从而导致数据不一致。
对于客户来说,他们的感觉是在更改别名后,刚才所做的所有更改都会消失。此外,正如我刚才提到的,一次大的索引迁移可能需要几个小时,因此客户的感觉一定很明显。
那么该怎么办呢?
reindex的正确流程
上述流程对原始流程进行了两次更改。
































![[RoarCTF2019] TankGame](https://img-blog.csdnimg.cn/direct/8fdee77c218b493ebeb7f7c049e8ea19.png)