目录
还在为论文、大作业的数据获取而发愁吗,来试试Pandas爬虫、代码只需要一行,让爬取数据不再遥不可及。
众所周知数据的获取极其重要,而Python爬虫既实用又听起来高大上,本文通过两个实战小例子来介绍Pandas爬取表格数据。
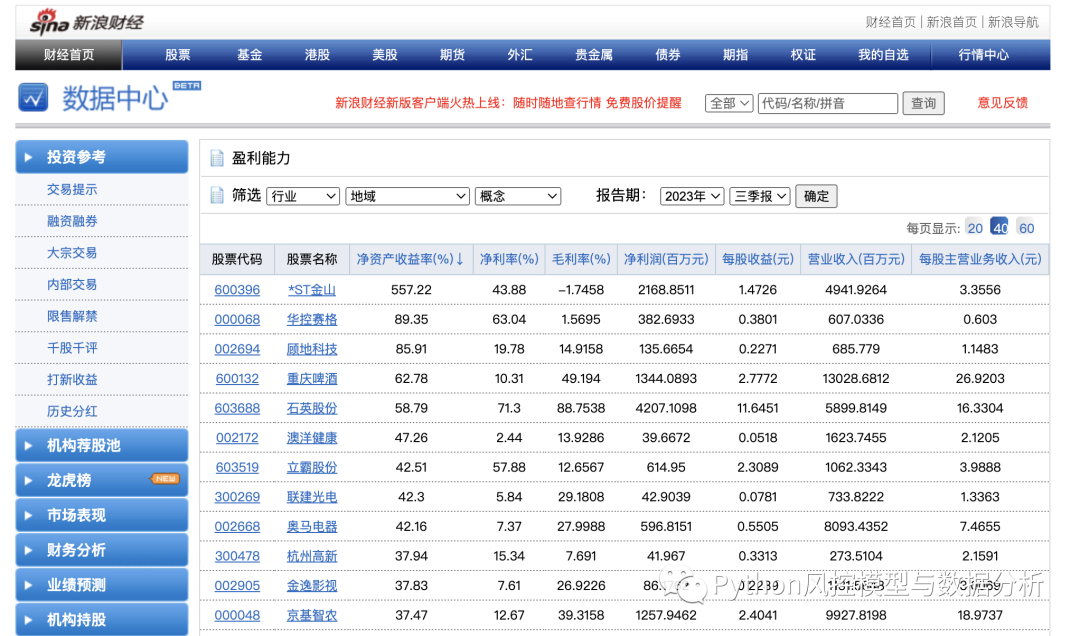
1、爬取新浪财经网股票机构的财务数据
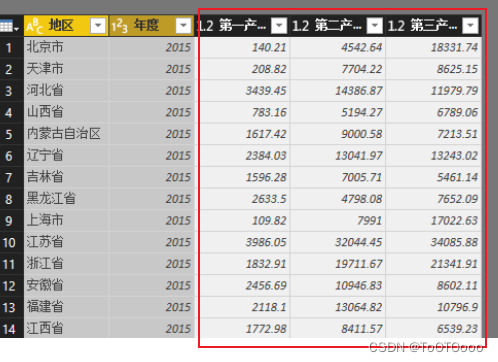
如图可以看到,网页里的财务数据是表格形式的,通过右键检查可以定位到网页元素为table,这种结构就可以直接用pandas来爬取数据了
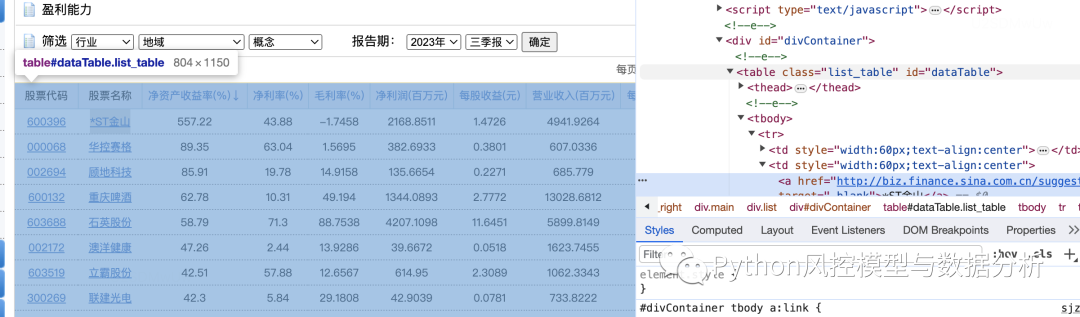
import pandas as pd
url='https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml'
df=pd.read_html(url)[0] # 取这个页面中第0个table元素
df
当然这只是第一页的数据,点击第二页可以看到网址后面多了?p=2,同理后面第三、四页也是如此,所以只需要循环改变url最后的页数就可以全量爬取数据了
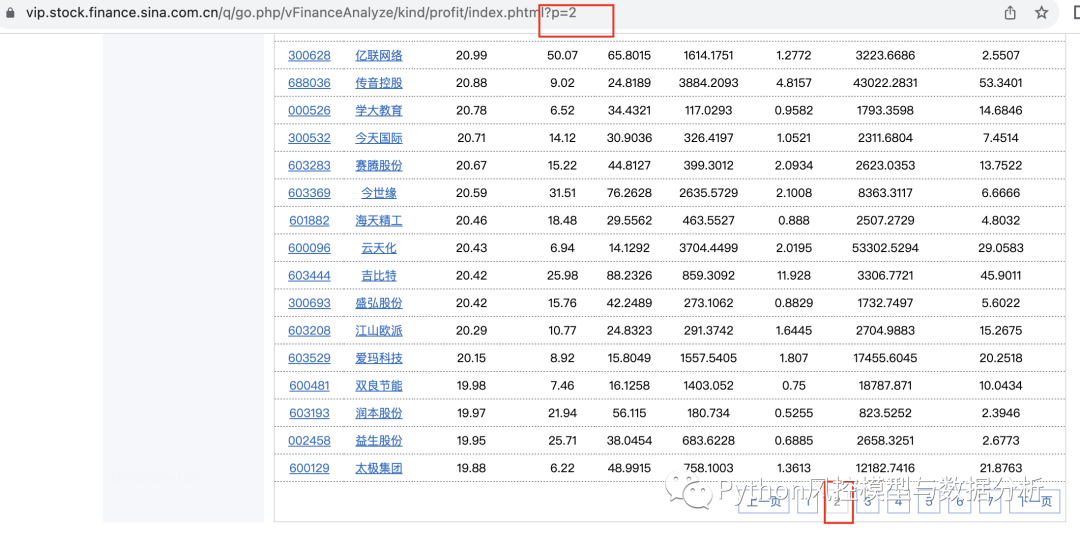
import pandas as pd
l=[]
for i in range(1,10):
url='https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml?p={}'.format(i)
l.append(pd.read_html(url)[0])
df=pd.concat(l,axis=0).reset_index(drop=True)
print(df.shape)
df.head()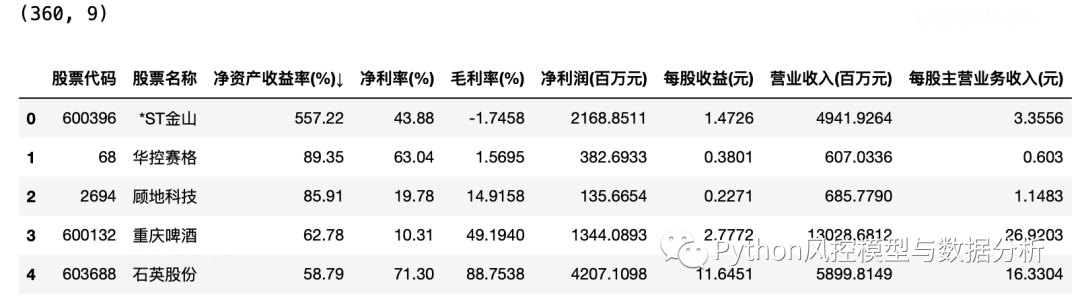
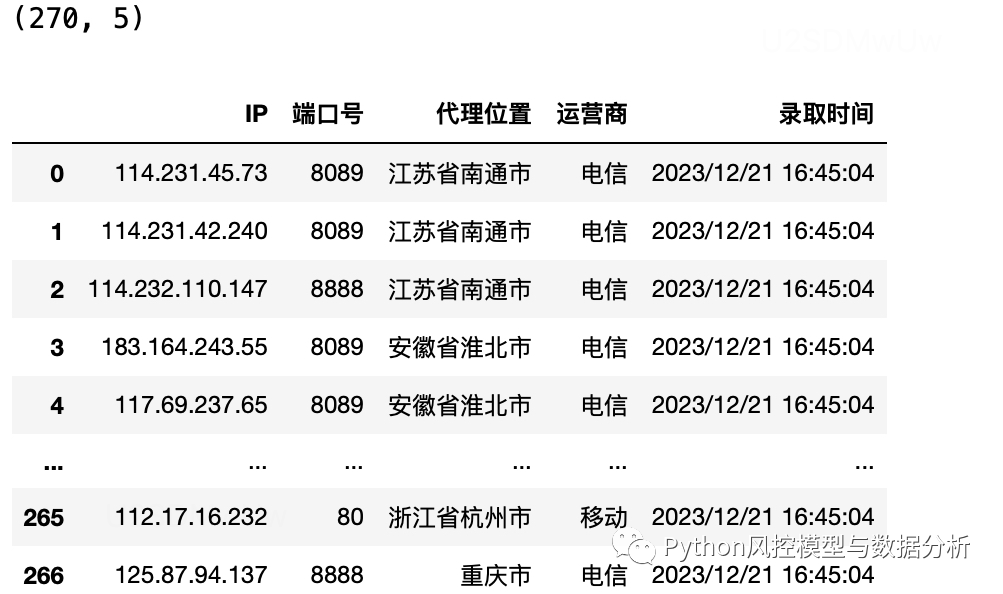
2、爬取89免费代理ip
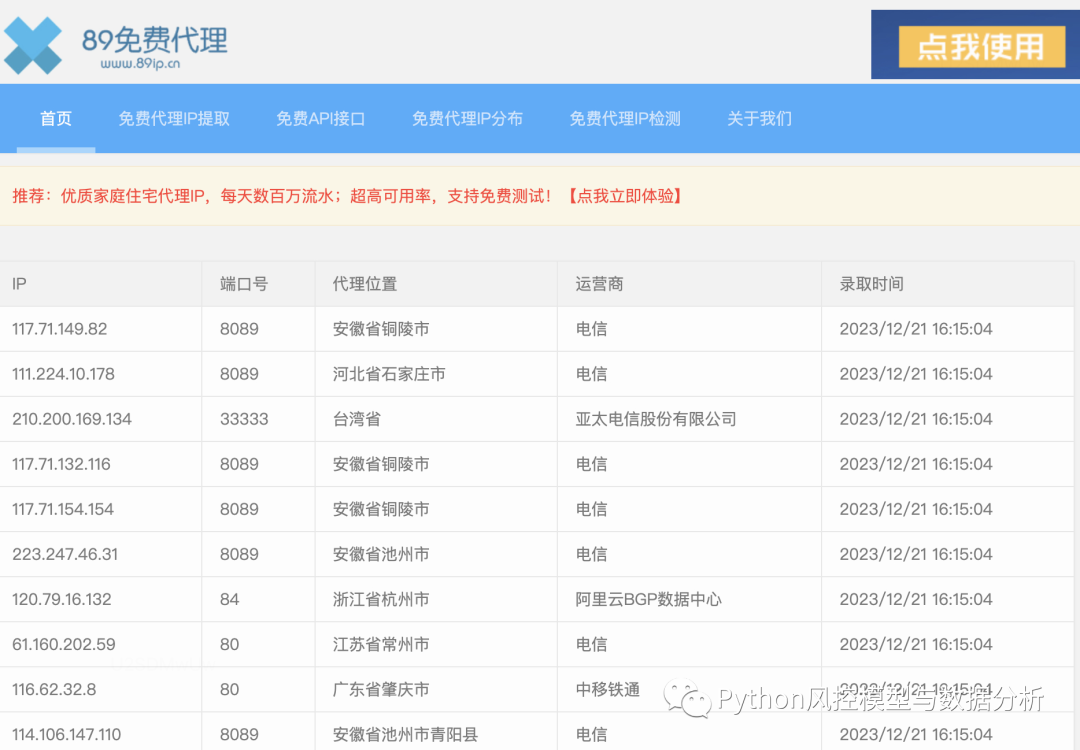
import pandas as pd
url='https://www.89ip.cn/index_1.html'
df=pd.read_html(url,encoding='utf-8')[0]
df
循环爬取多页
l=[]
for i in range(1,10):
url='https://www.89ip.cn/index_{}.html'.format(i)
l.append(pd.read_html(url,encoding='utf-8')[0])
df=pd.concat(l,axis=0).reset_index(drop=True)
print(df.shape)
df