前言
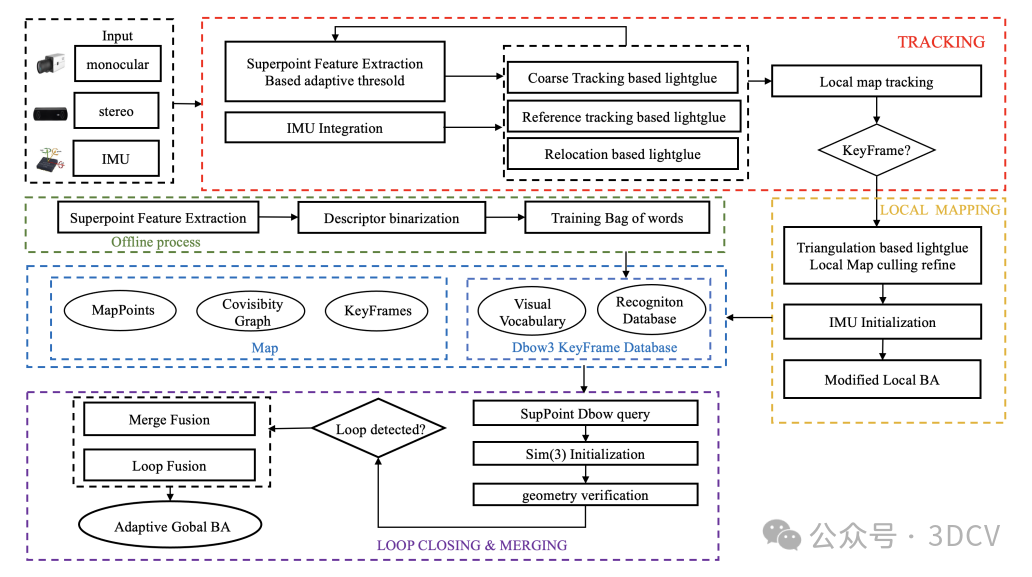
本文分享BEV感知方案中,具有代表性的方法:BEVFormer。
基本思想:使用可学习的查询Queries表示BEV特征,查找图像中的空间特征和先前BEV地图中的时间特征。
它基于Deformable Attention实现了一种融合多视角相机空间特征和时序特征的端到端框架,适用于多种自动驾驶感知任务。
主要由3个关键模块组成:
- BEV Queries Q:用于查询得到BEV特征图
- Spatial Cross-Attention:用于融合多视角空间特征
- Temporal Self-Attention:用于融合时序BEV特征
流程思路:采用3D到2D的方式,先在BEV空间初始化特征,通过在BEV高度维度“升维”形成3D特征。再通过映射关系,使用多层transformer与每个图像2D特征进行交互融合,最终再得到BEV特征。
论文地址: