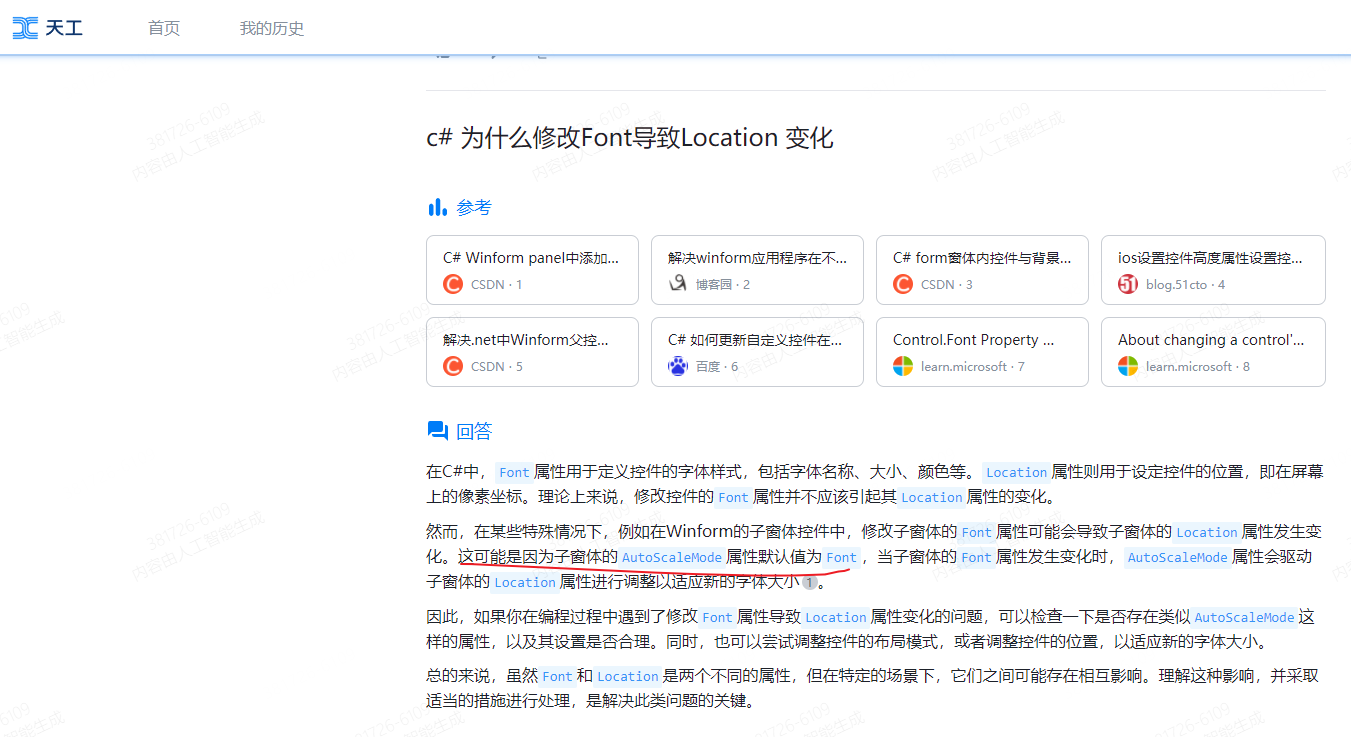
背景描述
pyspark 相当于 python 版的 spark-shell,介于 scala 的诡异语法,使用 pyspark on yarn 做一些调试工作还是很方便的。
配置
获取大数据集群配置文件。如果是搭建的 CDH 或者 CDP 可以直接从管理界面下载配置文件。直接下载 hive 组件的客户端配置就可以,它里面包含了 hdfs 和 yarn 的配置。如下所示:
-rw-rw-r--@ 1 diegolli staff 5.0K Dec 12 16:09 core-site.xml -rw-rw-r--@ 1 diegolli staff 557B Dec 12 16:09 hadoop-env.sh -rw-rw-r--@ 1 diegolli staff 4.0K Dec 12 16:09 hdfs-site.xml -rw-rw-r--@ 1 diegolli staff 1.3K Dec 12 16:09 hive-env.sh -rw-rw-r--@ 1 diegolli staff 6.0K Dec 12 16:09 hive-site.xml -rw-rw-r--@ 1 diegolli staff 310B Dec 12 16:09 log4j.properties -rw-rw-r--@ 1 diegolli staff 5.5K Dec 12 16:09 mapred-site.xml -rw-rw-r--@ 1 diegolli staff 1.6K Dec 12 16:09 redaction-rules.json -rw-rw-r--@ 1 diegolli staff 315B Dec 12 16:09 ssl-client.xml -rw-rw-r--@ 1 diegolli staff 7.3K Dec 12 16:09 yarn-site.xml安装 python 和 pyspark,因为是 on yarn 所以跟集群 spark 没有关系,客户端只需要安装 spark client 工具就可以。
conda create --name py37 python=3.7 # 待环境装好后激活并在其中安装 pyspark pip install pyspark配置环境变量并且启动 pyspark on yarn。启动前需要配置 HADOOP_CONF_DIR,直接指到第一步下载的配置文件即可。如果有多人使用服务器建议只在当前终端中配置。
export HADOOP_CONF_DIR=/root/diegolli/conf # 如果集群配置了 kerberos 认证,启动时需要提供认证身份。 pyspark --master yarn --principal principal_name --keytab /path/to/keytab出现下面结果表示 spark on yarn 启动成功。
Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.4.2 /_/ Using Python version 3.7.16 (default, Jan 17 2023 22:20:44) Spark context Web UI available at http://cdp01.shanghai.com:4040 Spark context available as 'sc' (master = yarn, app id = application_1701688246977_0883). SparkSession available as 'spark'. >>>测试 hive 连接。必须测试,如果不能连接到集群数仓或者没有权限。pyspark on yarn 启动了也没有什么用。
>>> spark.sql("show databases").show() +------------+ | namespace| +------------+ | annie| | default| |feature_test| | mike| | test| | view_db| +------------+ >>> spark.sql("use default") DataFrame[] >>> spark.sql("show tables").show() +---------+--------------------+-----------+ |namespace| tableName|isTemporary| +---------+--------------------+-----------+ | default| abcd| false| | default| ddd_training| false| | default|alitest_trans_081...| false| +---------+--------------------+-----------+ only showing top 3 rows >>> df = spark.sql("select * from ddd_training limit 5") >>> df.show() +-------------+-------------+ |sample_col_id|sample_col_ts| +-------------+-------------+ | 690000125089| 2023-07-01| | 690000022764| 2023-07-01| | 690000022764| 2023-07-02| | 690000125089| 2023-07-02| | 690000125089| 2023-07-04| +-------------+-------------+
异常现象
有时会出现 pyspark on yarn 启动失败,异常提示文件找不见,或者启动了但是按退回键光标却向右边空格。改动 python 版本可以解决这些问题。

















![[C++]——学习模板](https://img-blog.csdnimg.cn/direct/2ef4dbd63a494421b92781cea6d97744.png)