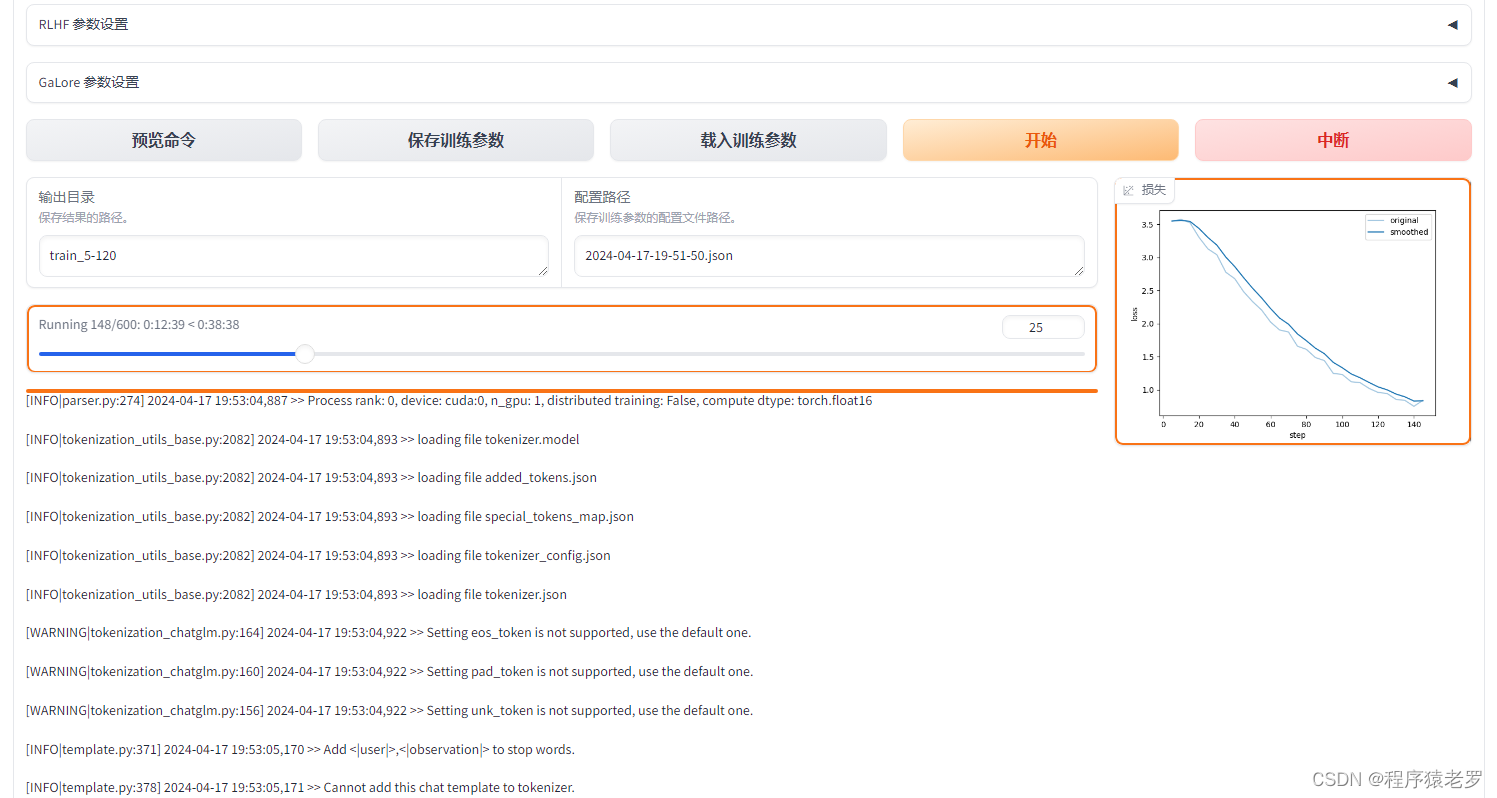
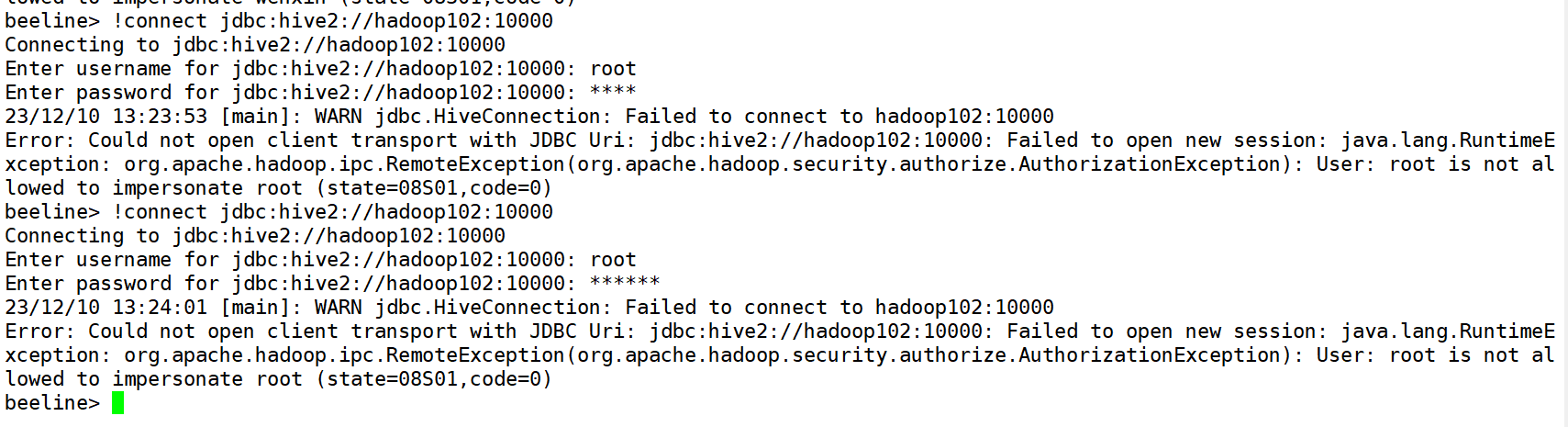
启动chatGLM3大模型后,发起对话请求后,推理过程突然报错,错误信息如下:
Traceback (most recent call last):
File "/root/miniconda3/envs/baichuan/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File "/root/miniconda3/envs/baichuan/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/generation/utils.py", line 1648, in generate
return self.sample(
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/generation/utils.py", line 2777, in sample
streamer.put(next_tokens.cpu())
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/generation/streamers.py", line 97, in put
text = self.tokenizer.decode(self.token_cache, **self.decode_kwargs)
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 3550, in decode
return self._decode(
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/tokenization_utils.py", line 938, in _decode
filtered_tokens = self.convert_ids_to_tokens(token_ids, skip_special_tokens=skip_special_tokens)
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/tokenization_utils.py", line 919, in convert_ids_to_tokens
tokens.append(self._convert_id_to_token(index))
File "/root/.cache/huggingface/modules/transformers_modules/chatglm3-6b-32k/tokenization_chatglm.py", line 140, in _convert_id_to_token
return self.tokenizer.convert_id_to_token(index)
File "/root/.cache/huggingface/modules/transformers_modules/chatglm3-6b-32k/tokenization_chatglm.py", line 75, in convert_id_to_token
return self.sp_model.IdToPiece(index)
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/sentencepiece/__init__.py", line 1045, in _batched_func
return _func(self, arg)
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/sentencepiece/__init__.py", line 1038, in _func
raise IndexError('piece id is out of range.')
IndexError: piece id is out of range.
Traceback (most recent call last):
File "/root/autodl-tmp/peng/LLaMA-Efficient-Tuning/final/chatglm3-lora/chat_model.py", line 144, in <module>
for new_text in chatglm3Model.stream_chat(query, history):
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 56, in generator_context
response = gen.send(request)
File "/root/autodl-tmp/peng/LLaMA-Efficient-Tuning/final/chatglm3-lora/chat_model.py", line 129, in stream_chat
yield from streamer
File "/root/miniconda3/envs/baichuan/lib/python3.10/site-packages/transformers/generation/streamers.py", line 223, in __next__
value = self.text_queue.get(timeout=self.timeout)
File "/root/miniconda3/envs/baichuan/lib/python3.10/queue.py", line 179, in get
raise Empty
_queue.Empty
经排查,是由于单卡启了多个大模型服务导致,也就是显存爆了,推理过程中,大模型对显存的占用会急剧飙升,但是服务报错后显存又会进行自动释放,所以最初忽略了显存的问题。。。。记录一下。



![[<span style='color:red;'>大</span><span style='color:red;'>模型</span>]<span style='color:red;'>ChatGLM</span><span style='color:red;'>3</span>-6B Code Interpreter](https://img-blog.csdnimg.cn/direct/d6c92bb18c3b41e18ee297ab0b45b0bb.png#pic_center)