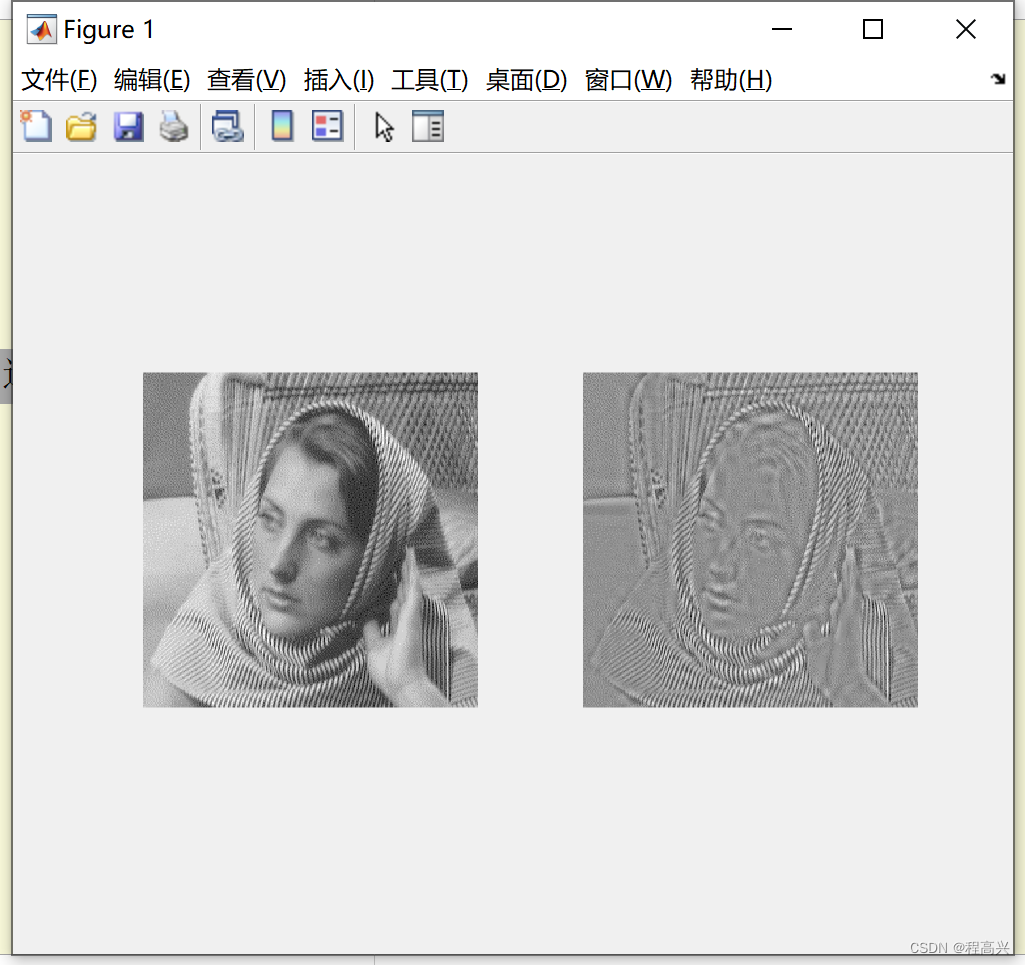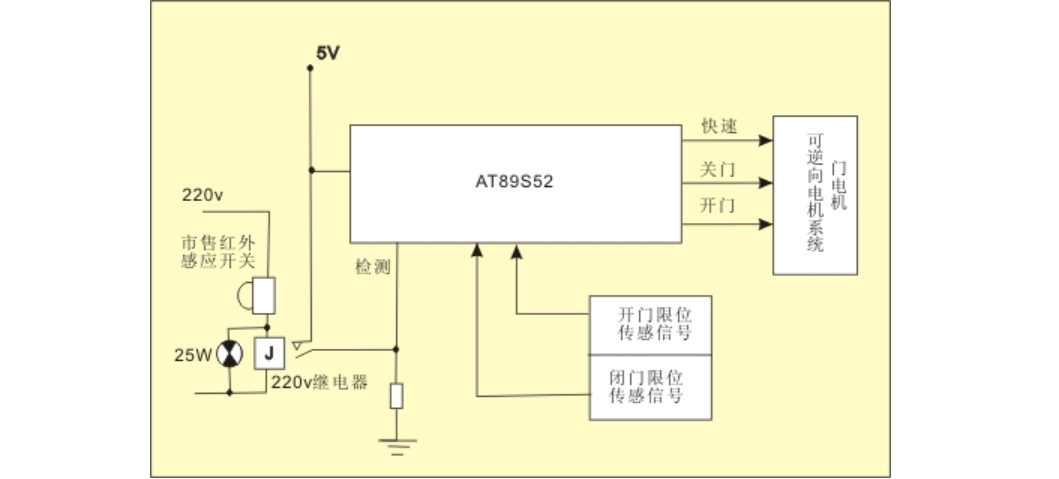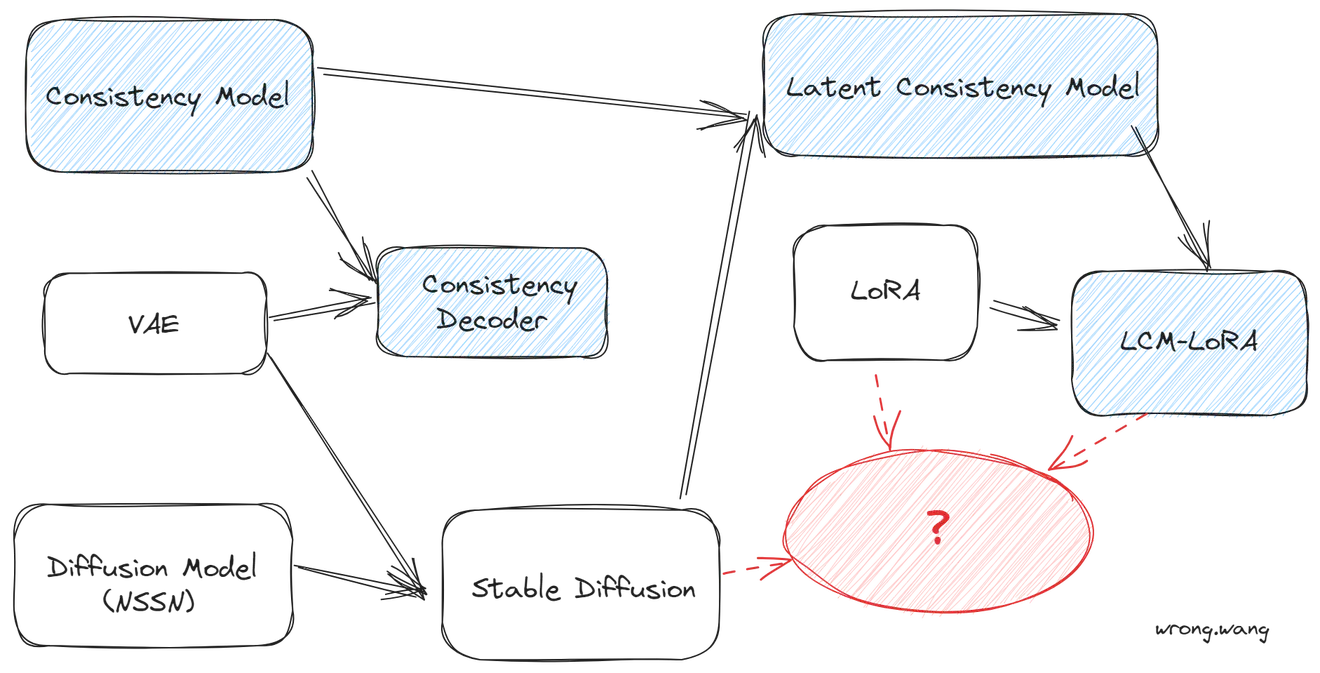
1.Stable diffusion实在预训练VAE空间训练diffusion model的结果。
2.consistency decoder是用consistency model技术训练的一个VAE的decoder,能更好的解码VAE latent为RGB的图片,DALLE3开源了lcm decoder,可以和VAE兼容使用。
3.Stable diffusion经过consistency model蒸馏技术蒸馏后得到latent consistency model。
4.既然lcm是对sd的一个finetune过程,那么就可以结合lora finetune技术,不再微调整个sd模型,而是微调个lora,得到lcm-lora,得到1.5,ssd-1b和sdxl三个版本的lcm-lora。
5.lcm-lora可以和其他sd的风格微调模型组合,依然有用,那就不用训练其他的sd模型的lora了,这些sd模型,直接用lcm-lora就可以加速。

LCM需要微调整个sd模型,consistency model本身可以和sd的网络结构完全一致,但是diffusion model作为ODE,其Solver可以有多种,可以采用硬解法的Solver,比如DPM++等,consistency model解ODE实际上通过的是函数f,f是通过蒸馏得到的,LCM就是在sd基础上利用consistency model蒸馏的,在VAE的潜空间中。社区中一大堆基于sd微调出来的模型难道都要优化一下,才能使用使用lcm技术加速求解吗,这也太麻烦了,于是除了lcm-lora。既然lcm是对sd的一个微调过程,只是换了一个loss,那就可以使用lora,只用lcm的蒸馏损失优化lora的权重。
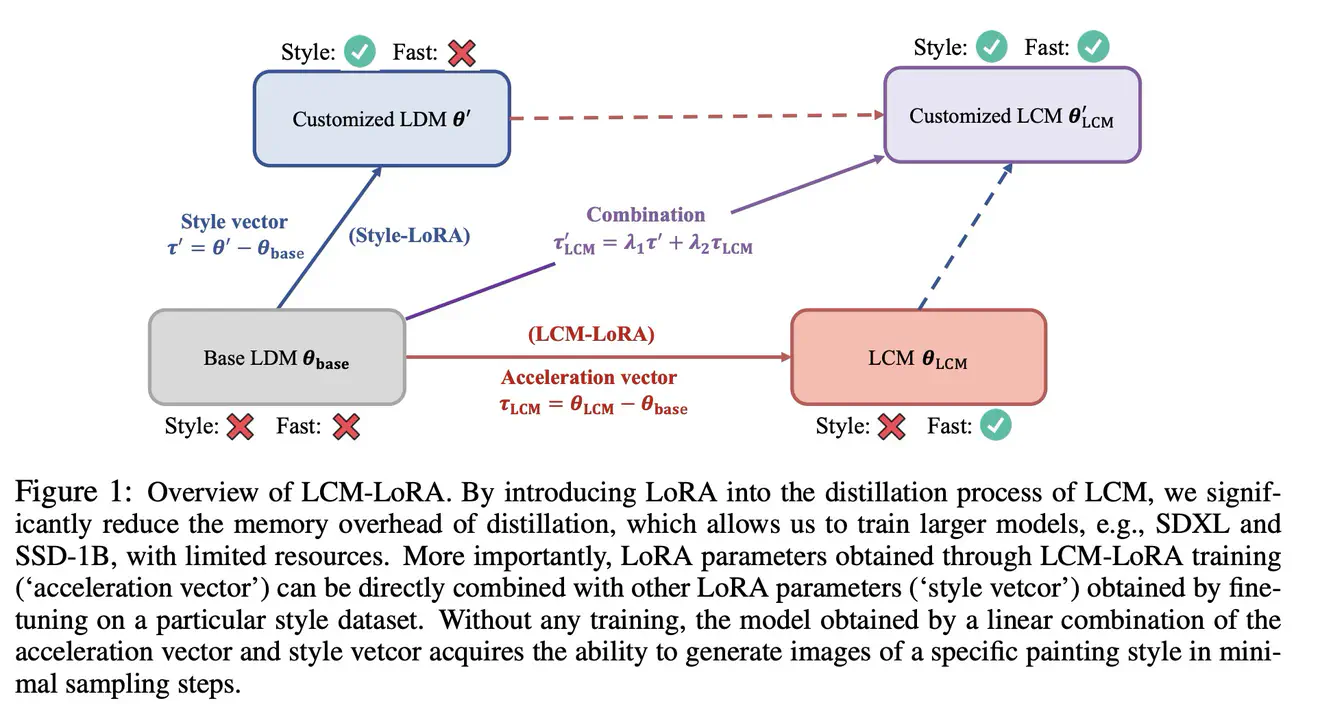
lcm-lora为什么能和之前各种提供style的sd lora直接加权使用呢?
1.lora把finetune增量矩阵限制成了低秩矩阵,两个低秩权重增量矩阵做加权冲突没那么大。
2.微调过程中diffusion前向的数据分布没有改变,lcm-lora训练过程中仍然用到了diffusion去噪,保证模型输出不会偏移原分布太多,从Zn+k预测的\hatZn依然接近真实Zn的分布。
lcm-lora训练过程中已经把guidance scale集成进去了,但是如果negative prompt对结果很重要,可以指定guidance scale为1.5试试。

























![[足式机器人]Part2 Dr. CAN学习笔记-Ch0-1矩阵的导数运算](https://img-blog.csdnimg.cn/direct/c7499731c8c04e97a668d03762c8104c.png)