0数据准备与分析
二分类任务,正负样本共计6W;

数据集下载
https://github.com/SophonPlus/ChineseNlpCorpus/raw/master/datasets/online_shopping_10_cats/online_shopping_10_cats.zip
样本的分布

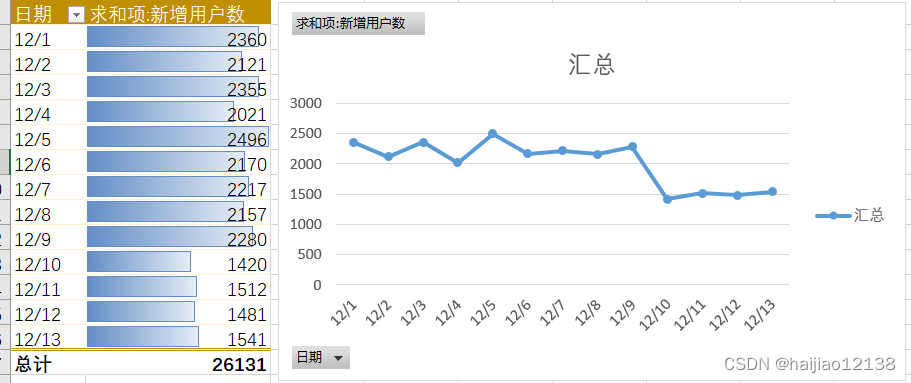
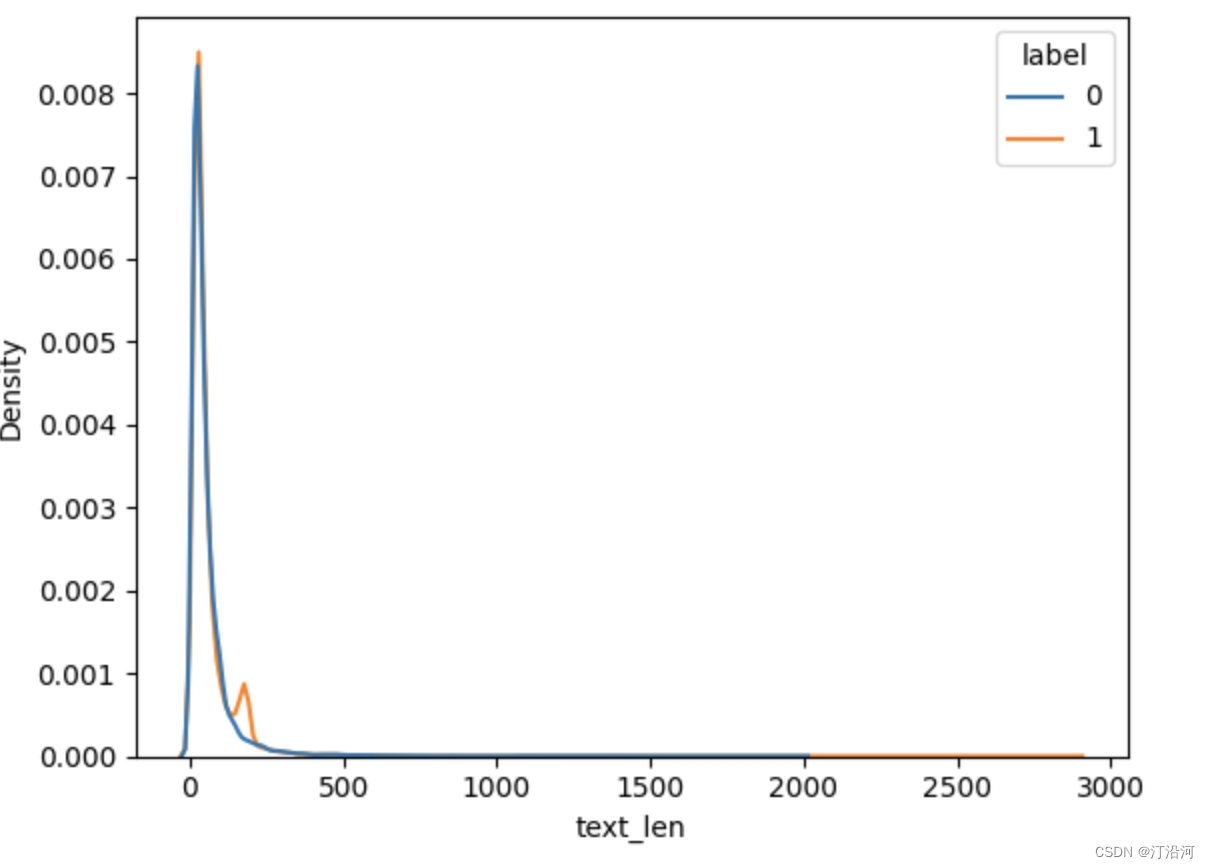
正负样本中评论字段的长度 ,超过500的都很少,可以直接截断;
- 处理的时候长文本截断;
- 可以前面取一点,中间取,尾巴取;
下载停用词:备用
import nltk
from nltk.corpus import stopwords# 下载停用词资源
nltk.download('stopwords')
# 获取中文停用词列表
stopwords_cn_list = stopwords.words('chinese')
中文词向量准备:
https://github.com/Embedding/Chinese-Word-Vectors.git
在初始化阶段预先使用已经训练好的词表进行对应;
| 文件 | 说明 |
| vocab.pkl | 词映射列表:格式如 {' ': 0,
'0': 1,
'1': 2,
'2': 3,
':': 4,
'大': 5,
'国': 6,
'图': 7,
'(': 8,} |
| embedding_SougouNews.npz | 预训练词向量文件 ,与vocab.pkl中文对应关系。 |
ref: