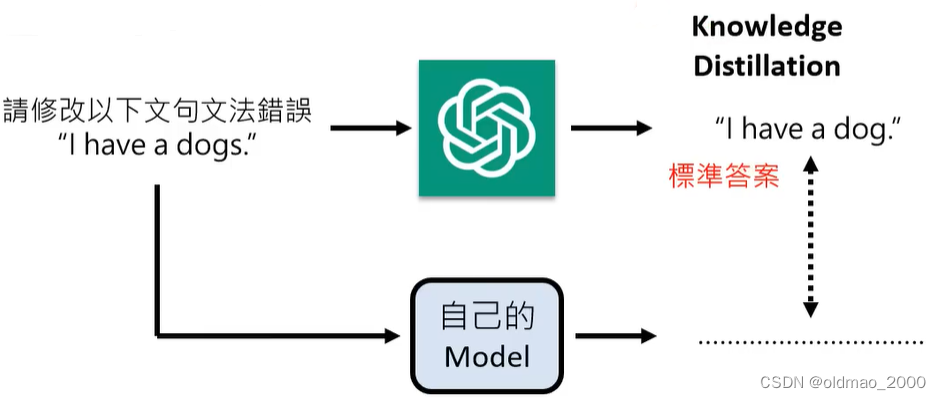
今天我们来闲聊聊chatGPT,然后带出一些目前神经网络或者更大一些人工智能存在的问题,仅作抛砖引玉。我不管OpenAI用什么方式炒作,Q*也好,AI自我意识也好,董事会内斗也罢;首先它的成绩还是非常出色的,并且chatGPT这个产品在大规模使用深度模型上算是非常成功的,however,chatGPT只能算是 Artificial If-clauses(AI, 姑且命名为人工条件生成器),算不上人工智能(Aritificial Intelligence, AI);我们离真正的人工智能还有一定的距离。
ChatGPT没有智能
ChatGPT的效果是惊艳的,大量数据被压缩成了vector,折叠起来,存储起来,需要的时候播放出来。我们要肯定它在数据压缩技术上的突破。
我们可以先参考这两篇论文,诉说着现在的深度神经网络和数据压缩的关系。
Opening the Black Box of Deep Neural Networks via Information, 2017
White-Box Transformers via Sparse Rate Reduction, 2023
简单来说,第一篇是想探索没有BP过程如何能训练神经网络(这篇是探索人工智能很重要的一步),第二篇则是将Transformer用信息论的方式导出了一个更明确的解释(相当于sigmoid和二分类问题的关联解释);具体的话知乎和CSDN上专家们比我解释得详细得多,有兴趣可以自行搜索查阅。深度神经网络的可解释性一直备受关注,大家都希望通过解释各个层的用途,从而更好控制整个网络的性能。
discriminative(判别式,和generative生成式对应)从一开始我们就知道其实它是一个大型穷举算法。我们通过注入不同的参数,然后用tensor的形式让参数们相加相乘,然后配上激活函数,就像是程序员在写的一个个if语句,当某个数值达到某种条件的时候,会让这个层上的这个参数给与后续参数一个正向激活,最终输出结果,所以我们说现在的神经网络,其实就是Artificial If-clauses (AI)。相当于,以前程序员写图像处理,用数学公式简化步骤后,最后能用lisp写个几百个if就能进行图像分类了;然后慢慢发展为大型决策树,if更多一些;到现在的深度神经网络,if已经可以达到亿万了;但是if就是if,是离散的,所以一定会有过拟合,判断不准不一定是写得不好,人类测量精度在那里,只能概率论只能量子效应了。
不过能让神经网络模型有那么一点智能,其实是训练过程。这才是人工智能的根。这方面不发展,人工智能只能是天方夜谭。
神经网络忽略的东西
困惑的Embedding
第一个让人困惑的是Embedding;这里可以引出目前神经网络在NLP上的一个问题,就是想用一个global vector表示语言。这个搜索引擎挥之不去的印记,余弦夹角快捷方便,真香。但是目前它的表示是碎片化的,就是说比如768维的vector,可能在某个领域作预测的时候有30维是有效的,另外738维都是噪声,这样的话,网络里的一些层里的一些channel需要遍历各种可能将30维都用1乘出来其他配0…当然开源的大语言模型都是以词为单位的,到了ChatGPT其实还在前面做了character字符为单位的tranform,这样可以检测拼写错误,让理解更精准,但是负面影响是可能人为需要这个错误的时候,要花更多tokens去解释这个故意的“错误”。对于多义性,可能要用到搜索排序的beam search top k,要根据上下文才能确认哪一个是真正的表述…
……蒋劲科大校长叹道……
……蒋劲(人名) 科大(学校) 校长 叹道……
……蒋劲科(人名) 大校 长叹道……
……蒋劲科大(学校) 校长 叹道……
所以vector还需要更细致地动态生成,这个已经有不少研究在路上了。从感觉上,至多可以将vector压缩到3维;为什么是感觉上,这个是收到求解自然底数e极限的启发:
e = lim ( 1 + 1/n )^n
n->∞
强行幻觉就是,(1 + 1/n) ^ n = ( (n + 1) / n )^n,相当于现有知识增加n微量新知识1,用现有知识n分解,再用现有知识n包装,极限是2.71....向上取整就是3维。当然,这里还是当我在一本正经胡扯比较好。
for语句在哪
我们看到神经网络有了 if-clauses,但是见不到 for,目前我所知道的尝试有一个skipNet的,但是基本上目前的循环就是靠if硬生生套了,就是本来我们写for语句是
sum = 0
for i = 1 to n
sum += i
现在用if就是类似于
sum = 0
if i && 1 then sum += 1
if i && 2 then sum += 2
if i && 4 then sum += 3
if i && 8 then sum += 4
……
并且这个是有限的比如根据模型参数的数量max最大到100,不像上面用for的时候n可以是任意的。还有一个比较典型的案例就是SPP,Yolo里识别多尺度大小的物体的时候做的尝试,是有限地设计成几个bounding box尺度大小。
dropout竟然这么有效
曾经有幸和Google的data scientist一起探讨过,如何连接机器学习五大学派(SVM/kNN 类比学派,贝叶斯学派,NN 连结学派,逻辑学派,EA 进化学派),他认为dropout其实构建了random forests。而从穷举空间来看,我感觉dropout能工作,更像是因为drop到参数大动脉是一个小概率事件,换句话说,我们现在discriminative出来的大量参数,只有很少量是起到主要作用的,参数自身sparse…就比如一个团队,你把捣乱的人踢走了,团队更有效率往一个方向发展;但是从EA来说,你还必须得保留一些捣乱分子,因为他们会干扰方向,当参数收敛遇到问题的时候,可以靠他们把整个团队拉出坑;这个很神奇,也是曾经说神经网络坑爹的地方,就是在穷举搜索空间,你永远不知道这个“坑”的“爹”(比当前最优解更优的解是否存在并且)在哪个地方。所以几年前EA带着autoML火了一段时间。
其实还有不少问题,今天就到这里吧。以后再说。
休息了…打烊…
J.Y.Liu
2023/12/02
p.s 最近发现ChatGPT比如4-Turbo确实已经降“智”(性能大不如前)了。六个月前的问题:“写一个python程序,输入是2个字符串,最终要打印出这2个字符串,并且对齐这两个字符串,相同的字符尽可能多地显示在同一列上,可以用空格分割一行上的字符串”
这个问题ChatGPT3.5-Turbo在6个月前可以1@Pass一次通过写出正确的答案。现在4-Turbo则需要加一个提示请使用LCS算法;而后其他模型都答得牛头不对马嘴。失望。
国内的大模型确实还有很大提升空间,差距也很明显。但是目前的大模型,有一定比技术,但主要还是在比拼财力,颇有当年星球大战的氛围…



























![[蓝桥杯习题]———位运算、判断二进制1个数](https://img-blog.csdnimg.cn/direct/2cc828db0f1f41a79f0087e31a45a8b8.gif#pic_center)