文章目录
前言
强烈建议阅读这篇confluent官方关于CDC的博文,写的非常好还包含了示例代码。可能你读完了之后,都不需要看我下面写的大部分内容。
背景
平时一些业务场景可能需要我们在多个系统之间进行业务同步,典型的场景有如下几种
- 将数据表同步至ElasticSearch以提高搜索速度。
- 同一张表的数据需要在多个数据库之间进行同步。多个数据库可能是同一种数据库,也可能是本文中的例子一样,是不同数据库之间进行同步
- 在同一个数据库中不同的表进行同步。例如表A中新增数据时,我们也需要在表B中进行一些数据操作
上述3个场景的共同要求基本都是,当数据源有新数据时,我们希望马上同步到目标,尽量减少延迟;在同步期间尽量减少对数据源的影响。
解决方案
场景一
对于场景一,我们可以使用的解决方案是Logstash的Jdbc插件。该插件的基本原理是,通过SQL和定期查询,获得新数据之后,送到ES中。但这种解决方案会存在一定的延时,并且如果没新增数据,频繁查询是没必要的。
如果数据库是MySQL,也可以选择阿里的cannal,这样解决了上述问题。现实情况可能是,我们在用PostgreSQL,所以只能选择Logstash。
场景二
对于场景二,如果是同一种数据库,例如Mysql,还是可以选择阿里的cannal。 但是对于其他数据库,例如是Oracle和PostgreSQL,就没办法了
场景三
对于场景三,现有的数据库中,无论哪个数据库,我们都可以使用Trigger-触发器来实现。但触发器增加了原本的SQL的执行时间,同时增加触发器需要更改对应的表结构。另一种方案是使用代码,在代码中进行处理,但这样增加了复杂度。
从目前解决的方案来看,都不是很完美。
CDC-Change Data Capture如何解决上述问题
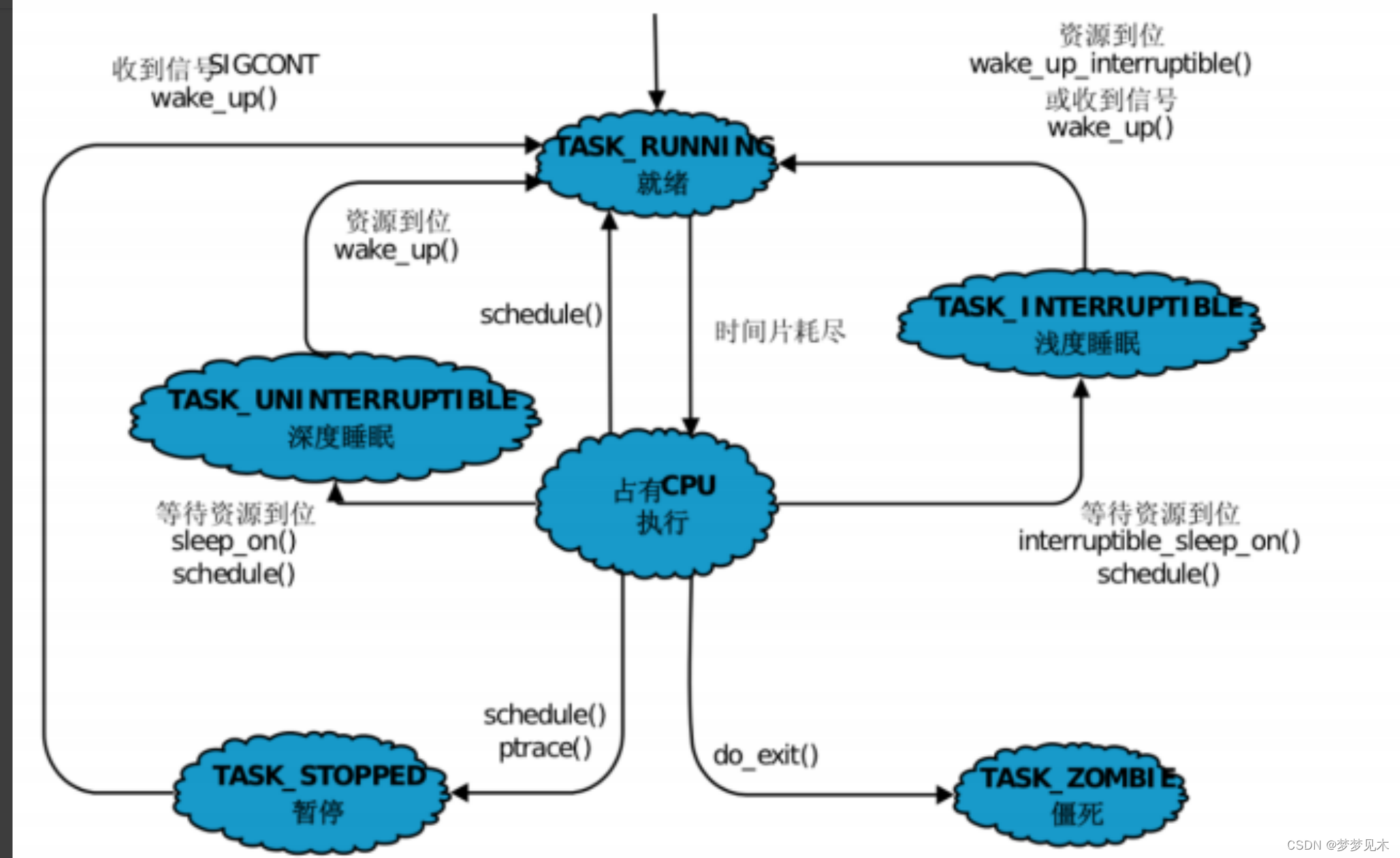
CDC工作原理
每种数据库都有一个至关重要的日志,用来记录数据库中所有修改操作。
- Oracle数据库的日志是Redo Log
- MySQL数据库的日志是Binary Log
- PostgreSQL数据库的日志是Write Ahead Log
通过监控这些日志,当源数据库发生改变时,监控该日志的软件将识别并提取其中的数据变更操作。当数据库中的数据发生插入、更新或删除时,CDC会捕获并记录这些变更操作的详细信息,包括受影响的表、修改前后的值以及执行操作的时间戳等。这些变更数据可以被传递给其他系统或应用程序,以便它们可以根据这些变更进行相应的处理。
CDC不需要对源数据库进行更改,并且不会对源数据库造成性能损耗。
Kafka Connect 和 Debezium简单介绍
Kafka Connect需要两个connector:
- sourceConnector.jar,将源数据导入至Kafka的topic中
- sinkConnector.jar,将Kafka topic中的数据导入至目标源
但是Kafka并没有提供特别丰富的connector,那么Debezium就出现了。
你可以把Debezium简单理解成是CDC技术的一种实现,并提供了很多数据库的sourceConnector.jar和sinkConnector.jar
场景二的例子,将Oracle数据库的数据通过CDC方式同步至PostgrSQL中
为了完成此demo,我们需要
- 一个三节点的kafka集群
- 安装Oracle数据库和PostgreSQL数据库
- debezium
- docker环境
docker-compose文件以及如何配置全部在GitHub上,想要自己体验一下的同学,请按照仓库中的步骤一步一步运行即可。如有问题可在本博文下留言即可。
使用Debezium时遇到问题的排查思路
核心思路就一条,仔细阅读 Debezium官方的Connector文档,特别是每个Connector的第一部分How the connector works
场景一和场景三的实现思路
理解了上述CDC部分,并且如果你能一步一步跟着源码自己动手体验一次。 那么你会很容易知道如何处理场景一和场景三,场景一和场景三无非是使用不同的sourceConnector.jar和sinkConnector.jar,那么我们的问题就变成了怎么找这些jar包?
去confluent hub搜索即可,提供了大量的jar包,包括Elasticsearch相关的sourceConnector、sinkConnector。每个jar包都有对应的文档。或者在Confluent官网 > Products > Connectors 访问
对于场景一官方曾经写过一篇关于如何将MySQL的数据同步到ElasticSearch中的文章。该文章可在elasticsearch-sink-connector的文档中找到
ETL(Extract, Transform, and Load)和Flink CDC
实际业务场景复杂多样,可能不光光是原封不动的复制数据,特别是有一些复杂报表的场景。我们需要对不同数据表的进行同步,并在同步过程中将多个表的数据组织在一起,形成一条有效记录,然后导入到目标源,上述过程就是ETL。
Flink CDC是基于Flink的实现方案,我本人并没有使用过它,这里提一下主要是觉得可能对看博文的你做技术决策有些帮助,根据自己的实际情况去选择适合自己的技术方案。
写在最后
因为我也是才开始慢慢使用CDC解决部分业务场景,所以目前关于Debezium和Kafka Connect的最佳实践还没有特别好的经验分享。基于这个原因,本篇博文并没有太多可供参考的经验,仅仅介绍CDC的思想、提供一些基础示例、不同解决方案的思考思路





















![矩阵置零[中等]](https://img-blog.csdnimg.cn/a6535b2d58f743ac9c3e68fd2277e118.png)