Parquet is a columnar format that is supported by many other data processing systems. Spark SQL provides support for both reading and writing Parquet files that automatically preserves the schema of the original data. When reading Parquet files, all columns are automatically converted to be nullable for compatibility reasons.
Loading Data Programmatically
Using the data from the above example:
- Python
- Scala
- Java
- R
- SQL
peopleDF = spark.read.json("examples/src/main/resources/people.json")
# DataFrames can be saved as Parquet files, maintaining the schema information.
peopleDF.write.parquet("people.parquet")
# Read in the Parquet file created above.
# Parquet files are self-describing so the schema is preserved.
# The result of loading a parquet file is also a DataFrame.
parquetFile = spark.read.parquet("people.parquet")
# Parquet files can also be used to create a temporary view and then used in SQL statements.
parquetFile.createOrReplaceTempView("parquetFile")
teenagers = spark.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenagers.show()
# +------+
# | name|
# +------+
# |Justin|
# +------+Find full example code at "examples/src/main/python/sql/datasource.py" in the Spark repo.
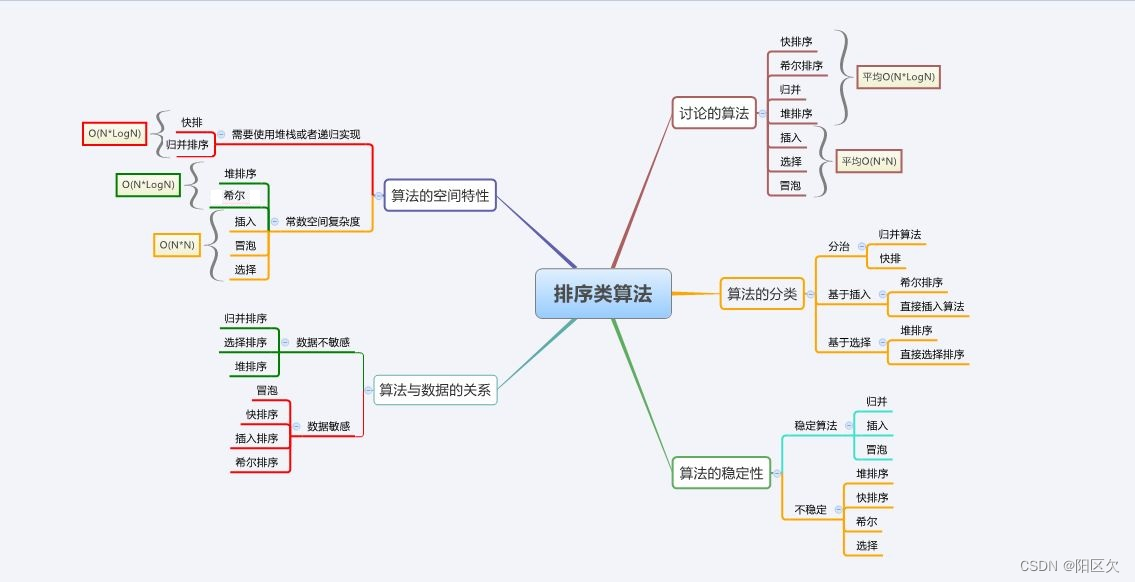
Schema Merging
Like Protocol Buffer, Avro, and Thrift, Parquet also supports schema evolution. Users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. The Parquet data source is now able to automatically detect this case and merge schemas of all these files.
Since schema merging is a relatively expensive operation, and is not a necessity in most cases, we turned it off by default starting from 1.5.0. You may enable it by
- setting data source option
mergeSchematotruewhen reading Parquet files (as shown in the examples below), or - setting the global SQL option
spark.sql.parquet.mergeSchematotrue
- Python
- Scala
- Java
- R
from pyspark.sql import Row
# spark is from the previous example.
# Create a simple DataFrame, stored into a partition directory
sc = spark.sparkContext
squaresDF = spark.createDataFrame(sc.parallelize(range(1, 6))
.map(lambda i: Row(single=i, double=i ** 2)))
squaresDF.write.parquet("data/test_table/key=1")
# Create another DataFrame in a new partition directory,
# adding a new column and dropping an existing column
cubesDF = spark.createDataFrame(sc.parallelize(range(6, 11))
.map(lambda i: Row(single=i, triple=i ** 3)))
cubesDF.write.parquet("data/test_table/key=2")
# Read the partitioned table
mergedDF = spark.read.option("mergeSchema", "true").parquet("data/test_table")
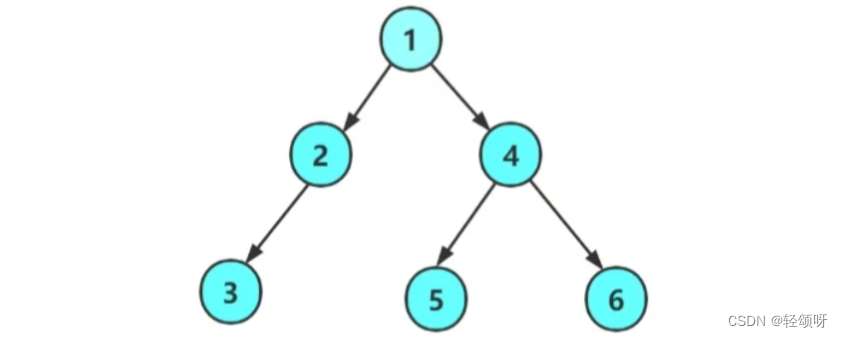
mergedDF.printSchema()
# The final schema consists of all 3 columns in the Parquet files together
# with the partitioning column appeared in the partition directory paths.
# root
# |-- double: long (nullable = true)
# |-- single: long (nullable = true)
# |-- triple: long (nullable = true)
# |-- key: integer (nullable = true)// This is used to implicitly convert an RDD to a DataFrame.
import spark.implicits._
// Create a simple DataFrame, store into a partition directory
val squaresDF = spark.sparkContext.makeRDD(1 to 5).map(i => (i, i * i)).toDF("value", "square")
squaresDF.write.parquet("data/test_table/key=1")
// Create another DataFrame in a new partition directory,
// adding a new column and dropping an existing column
val cubesDF = spark.sparkContext.makeRDD(6 to 10).map(i => (i, i * i * i)).toDF("value", "cube")
cubesDF.write.parquet("data/test_table/key=2")
// Read the partitioned table
val mergedDF = spark.read.option("mergeSchema", "true").parquet("data/test_table")
mergedDF.printSchema()
// The final schema consists of all 3 columns in the Parquet files together
// with the partitioning column appeared in the partition directory paths
// root
// |-- value: int (nullable = true)
// |-- square: int (nullable = true)
// |-- cube: int (nullable = true)
// |-- key: int (nullable = true)