前言
最近重新学习了栈和队列的结构,有一些新的感受。本文将详细介绍栈和队列的数据结构,并给出编译举例方便读者理解。栈和队列与之前学的顺序表结构和链表结构有关,用链表或者顺序表的结构都能实现栈和队列,甚至能用栈实现队列的效果,也能用队列实现栈的效果,只是在代码结构上、内存消耗上、时间消耗上各有不同。在此基础上,栈和队列都有更适合实现自己的结构。
一. 栈
1. 栈的定义
栈作为一种数据结构如何储存数据和输出数据呢?它的结构又为什么如此呢?
栈的结构就像是步枪的弹夹,想象子弹往上装的过程。最后装进去的子弹,会最先打出来。这和栈的储存数据和输出数据的形式类似。除此之外的类比又相当于杯子里装水、羽毛球筒和羽毛球。


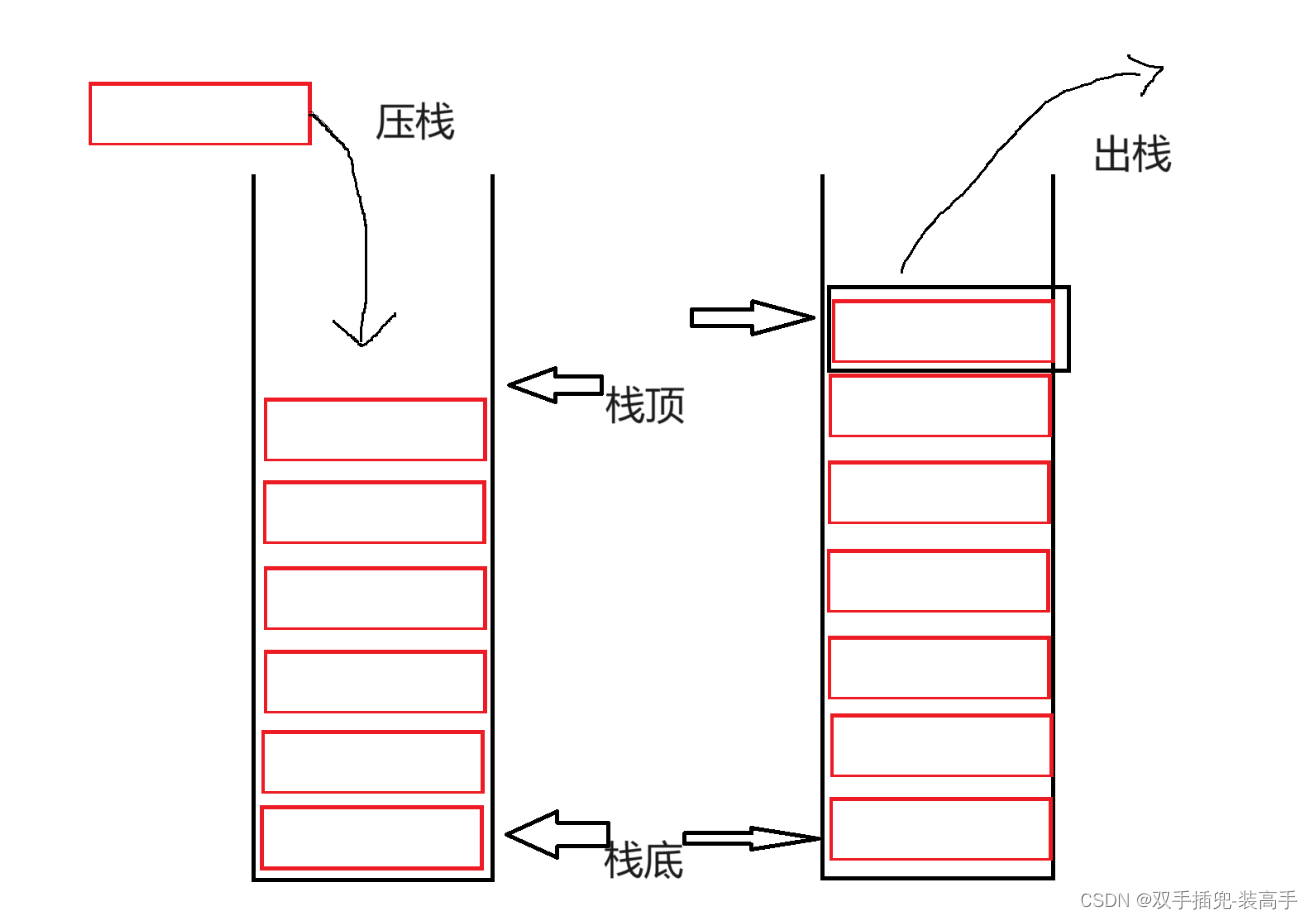
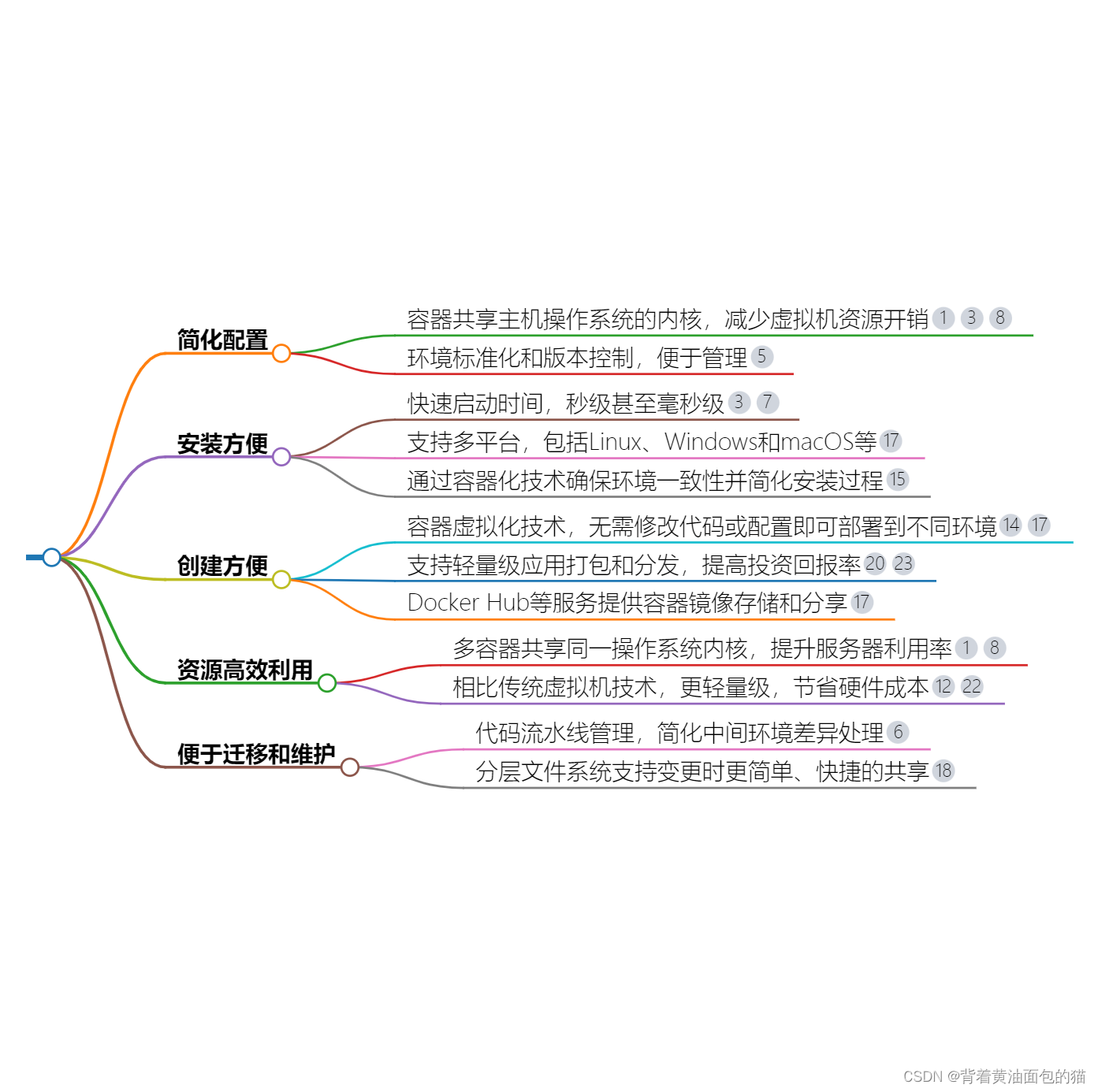
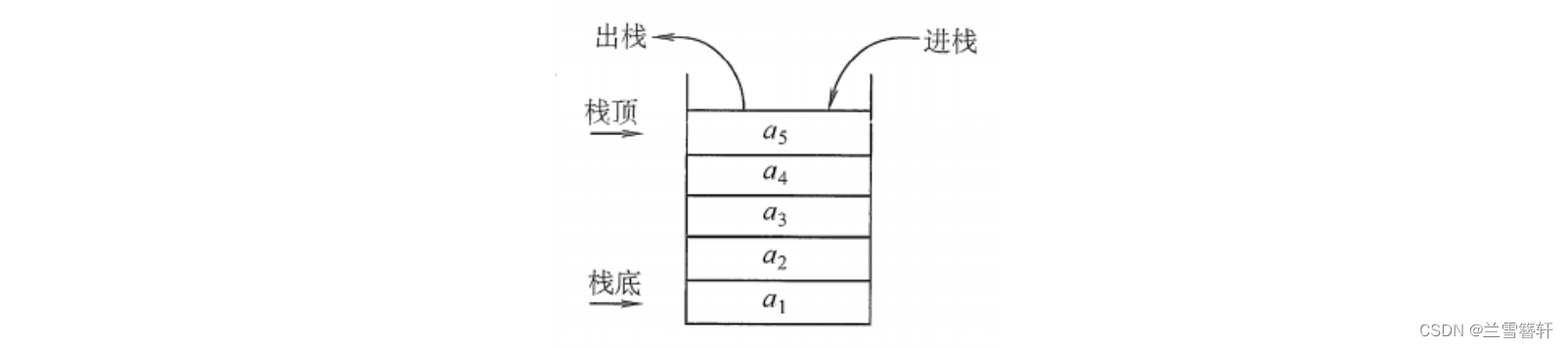
图1-1 形象实例图片
如图1-1所示,像这样最后进的羽毛球会被最先拿出来、最后进入的子弹最先打出,转换为数据的储存方式就是有一个存放数据的容器,在容器中最后存入的数据会被最先拿出来。

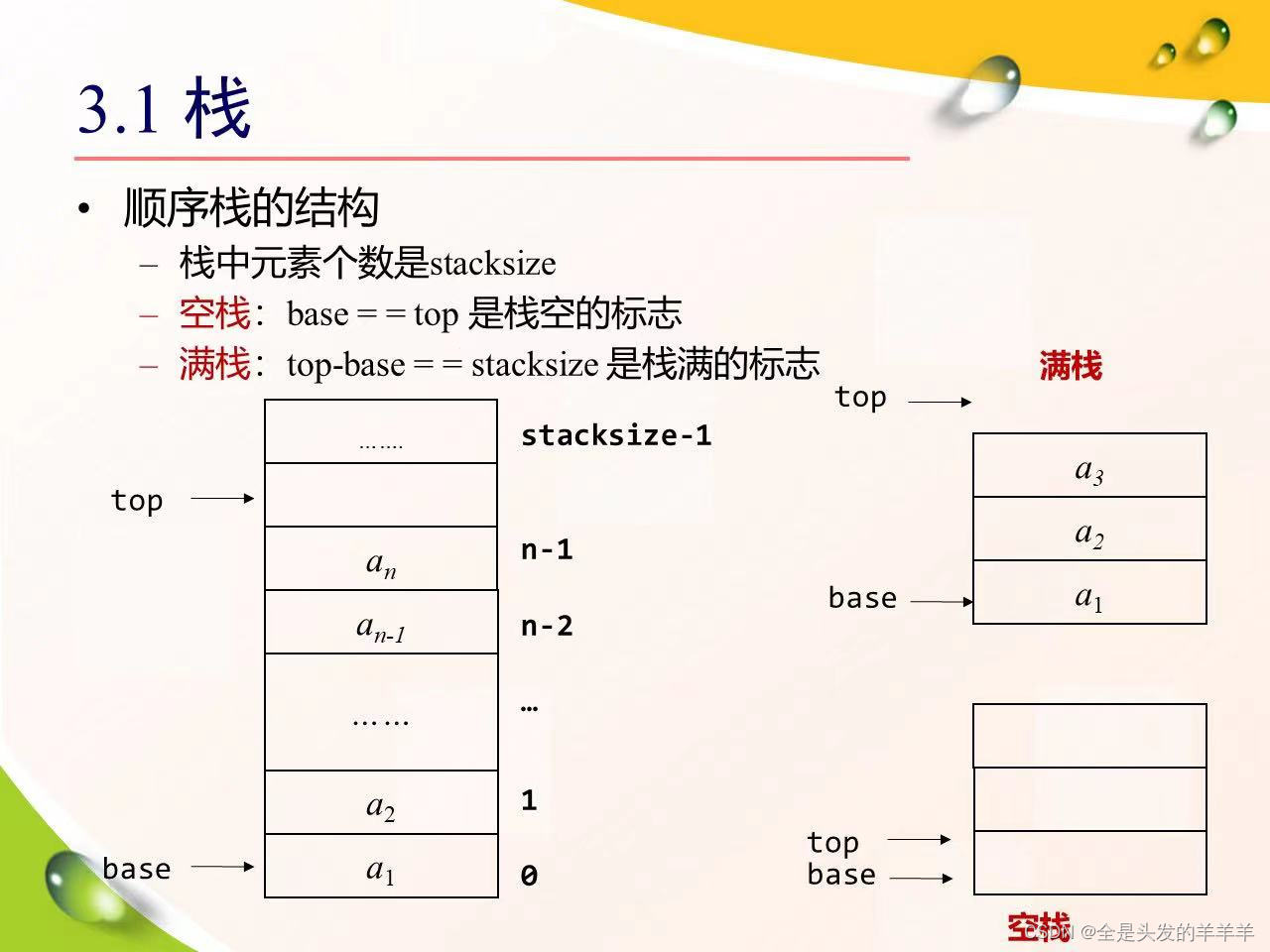
图1-2 栈的结构
那么,如图1-2所示,和栈相关的内容也介绍一下:
栈底:栈底,用水杯的例子来说就相当于杯底。
栈顶:用水杯的例子来说就是水面高度的位置,和进栈出栈的操作密切相关。
进栈:向栈内储存数据,会放到原来栈顶之上。
出栈:从栈顶依照顺序拿出储存的数据。
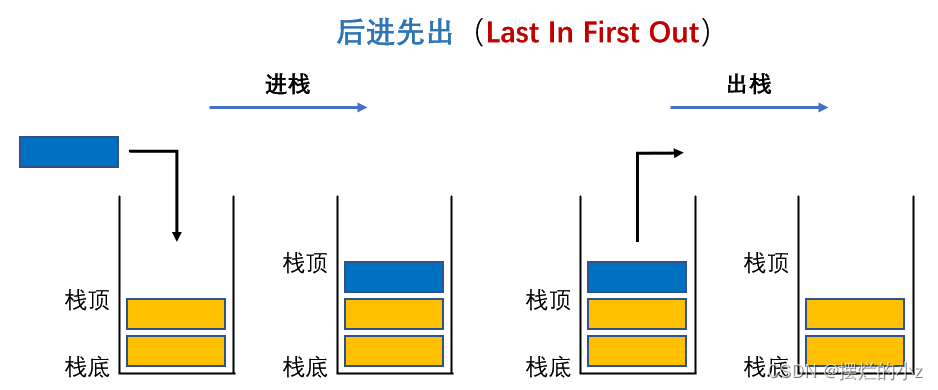
结构的作用,放在这里不太好解释,如果学习了后面的二叉树就能更好的理解这里栈的意义了。总之,栈的效果就是后进先出(Last In First Out)。能够将需要储存的但暂时用不到的数据放到栈底,这样出数据的顺序能够确保。
2. 栈功能的实现
2.1. 实现方案
2.1.1. 整体功能确定
作为一个栈,我们需要把它的功能分装成各种函数。那么栈究竟需要怎么样的功能呢?整体功能大概分为以下几种:
(1)初始化栈的结构。
(2)销毁栈所开辟的内存空间
(3)将数据储存到栈内,及入栈
(4)获得栈顶的数据和删去栈顶数据,及出栈。
(5)栈内没有数据就无法执行删除操作,所以需要判断栈内是否为空。
2.1.2. 实现栈的数据结构
2.1.2.1. 顺序表
顺序表如何实现栈?顺序表是一块连续空间,相当于数组,那么上一个数据和下一个数据的位置就是紧邻的。使用顺序表的结构就相当于具有顺序表的相关特性,优点是数据储存连续,删除数据和读取数据都很方便,特别是对于栈的结构来说。缺点和所有顺序表的结构缺点相同,如果原本空间不足就会异地拷贝数据,消耗会异常的大。
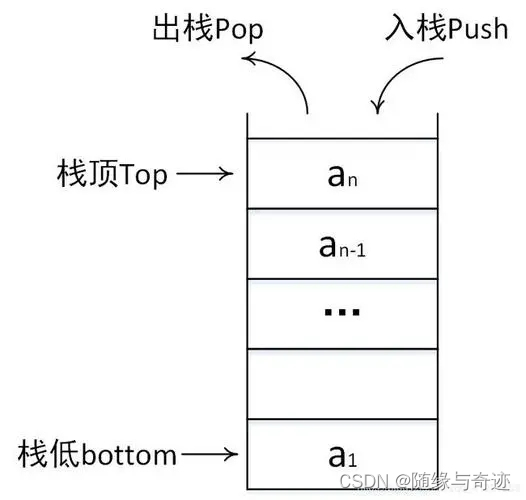
图1-2 顺序表模拟栈
2.1.2.2. 链表
如果用单链表模拟栈也不是不可以,将最后储存的数据放到链表的开头,倒着使用链表。出栈的话就从链表开头拿出数据。
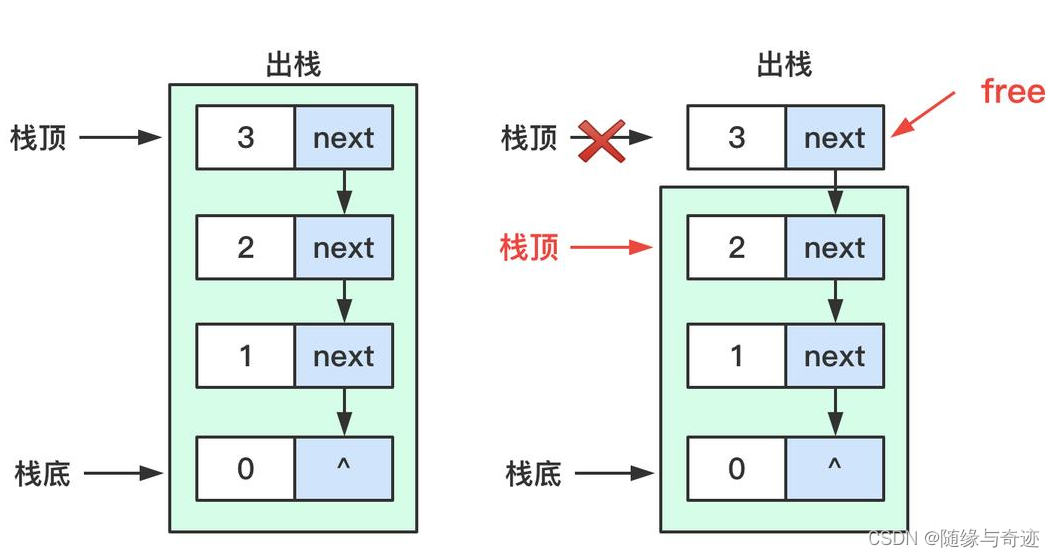
图1-3 单链表模拟栈
如果用双向链表来模拟栈,可以直接用链表的尾插来表示入栈,尾删来表示出栈。
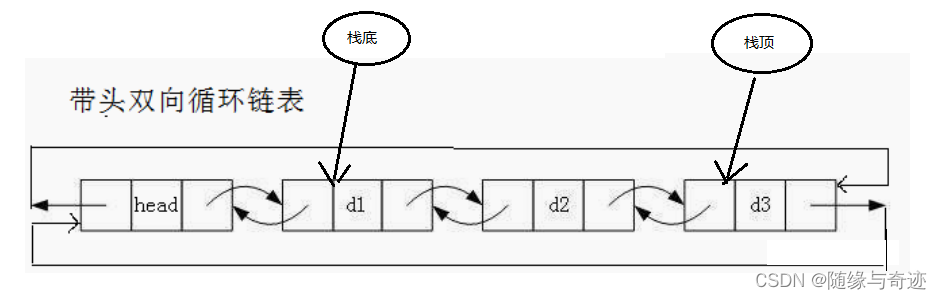
图1-4 双链表模拟栈
但是有一个缺点,就是每次开拓空间都需要储存指针的空间,在32位的系统下会多4到8个字节,在64位的系统下分别会多8到16个字节。
所以一般栈所使用的结构都是顺序表结构。所占空间更少。
2.2. 实现代码
2.2.1. 整体结构
根据2.1.2.描述的内容选择顺序表作为栈的基础结构,又根据2.1.1. 整体的代码如下:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
#define INIT 4
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;
int _top; // 栈顶
int _capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps); 接下来就是分别实现上述函数的具体过程。
2.2.2. 初始化栈
传入栈的指针,开拓初始空间,并将栈内元素初始化。具体代码意义如下所示:
// 初始化栈
void StackInit(Stack* ps)
{
assert(ps);
//开拓初始空间,这里的初始大小能够储存4个数据
STDataType* newnode = (STDataType*)malloc(sizeof(STDataType) * INIT);
if(newnode == NULL)
{
perror("StackInit malloc fail");
exit(1);
}
//让指针指向开拓的空间
ps->_a = newnode;
//初始化,最开始没有数据
ps->_top = 0;
//记录总空间大小,最开始为4
ps->_capacity = INIT;
}2.2.3. 销毁栈
已经创建初始化了栈,接下来就直接将销毁栈的代码写好,代码如下:
// 销毁栈
void StackDestroy(Stack* ps)
{
assert(ps);
//释放内存中堆上开辟的空间
free(ps->_a);
//消除野指针
ps->_a = NULL;
//容量,数据量均归零
ps->_capacity = ps->_top = 0;
}2.2.4. 判断栈是否为空
直接根据数据量是否等于0判断,代码如下:
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(Stack* ps)
{
assert(ps);
return ps->_top == 0;
}2.2.5. 判断栈中数据个数
直接找到数据量然后返回,代码如下:
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{
return ps->_top;
}2.2.6. 储存数据——入栈
我编写代码喜欢先编写完辅助内容,这样剩下的代码好编辑。入栈就和顺序表尾插数据相同,不在多做解释,详情可以参考之前的博客《顺序表》。
// 入栈
void StackPush(Stack* ps, STDataType data)
{
assert(ps);
//容量不足扩容
if(ps->_top == ps->_capacity)
{
STDataType* newnode = (STDataType*)realloc(ps->_a, sizeof(STDataType) * ps->_capacity * 2);
if(newnode == NULL)
{
perror("StackInit malloc fail");
exit(1);
}
ps->_a = newnode;
ps->_capacity *= 2;
}
//入栈
ps->_a[ps->_top] = data;
++ps->_top;
}这里就不需要分装函数扩容了,因为只有入栈函数用扩容的需要。
2.2.7. 删除数据——出栈
使用之前判空的函数,不为空就从尾部删除数据,代码如下:
// 出栈
void StackPop(Stack* ps)
{
assert(ps);
if(!StackEmpty(ps))
{
--ps->_top;
}
}2.2.8. 取出栈顶数据
和出栈配合使用,代码如下:
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{
assert(ps);
return ps->_a[ps->_top - 1];//栈顶元素在top的上一位
}3. 测试栈
3.1. 测试内容介绍
创建栈并初始化,然后放入5个数据确认栈的扩容是否正常,最后将栈内数据取出打印,结果应该与输入顺序相反,随后销毁链表。
因为是测试所以数据相当简单,但是检测函数正确性足够够。
另外,栈的拿出顺序也不一定是一次都拿出来,也可以一边拿一边存。这里以测试为主。
3.2. 测试代码
根据3.1. 将代码实例化,如下:
#include "Stack.h"
void TestStack()
{
Stack st;
StackInit(&st);
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
StackPush(&st, 5);
while(!StackEmpty(&st))
{
STDataType data = StackTop(&st);
StackPop(&st);
printf("%d ", data);
}
printf("\n");
StackDestroy(&st);
}
int main()
{
TestStack();
return 0;
}3.3. 运行结果
运行结果无误:
![]()
4. 相关练习题
4.1. 题目
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
每个右括号都有一个对应的相同类型的左括号。
4.2. 解题思路
直接将数据储存到数组然后找到右括号就向左找括号还是相当困难的,而且不好操作。但是根据我们新学的栈,可以把左括号存到一个栈里,然后碰到右括号就从栈里找出左括号看是否对应,或者找不到直接返回false。遍历完所有的内容之后看栈内还有没有数据,如果有则说明有左括号没法找到对应右括号。反之则说明全部对应,返回true。
4.3. 解题代码
根据4.2. 思路的代码如下:
bool isValid(char* s) {
Stack st;
StackInit(&st);
while(*s)
{
if(*s == '(' || *s == '[' || *s == '{')
{
StackPush(&st, *s);
}
else
{
if(StackEmpty(&st))
{
StackDestroy(&st);
return false;
}
STDataType top = StackTop(&st);
StackPop(&st);
if((top == '(' && *s != ')')
|| (top == '[' && *s != ']')
|| (top == '{' && *s != '}'))
{
StackDestroy(&st);
return false;
}
}
++s;
}
if(!StackEmpty(&st))
{
StackDestroy(&st);
return false;
}
else
{
StackDestroy(&st);
return true;
}
}二. 队列
1. 队列的定义
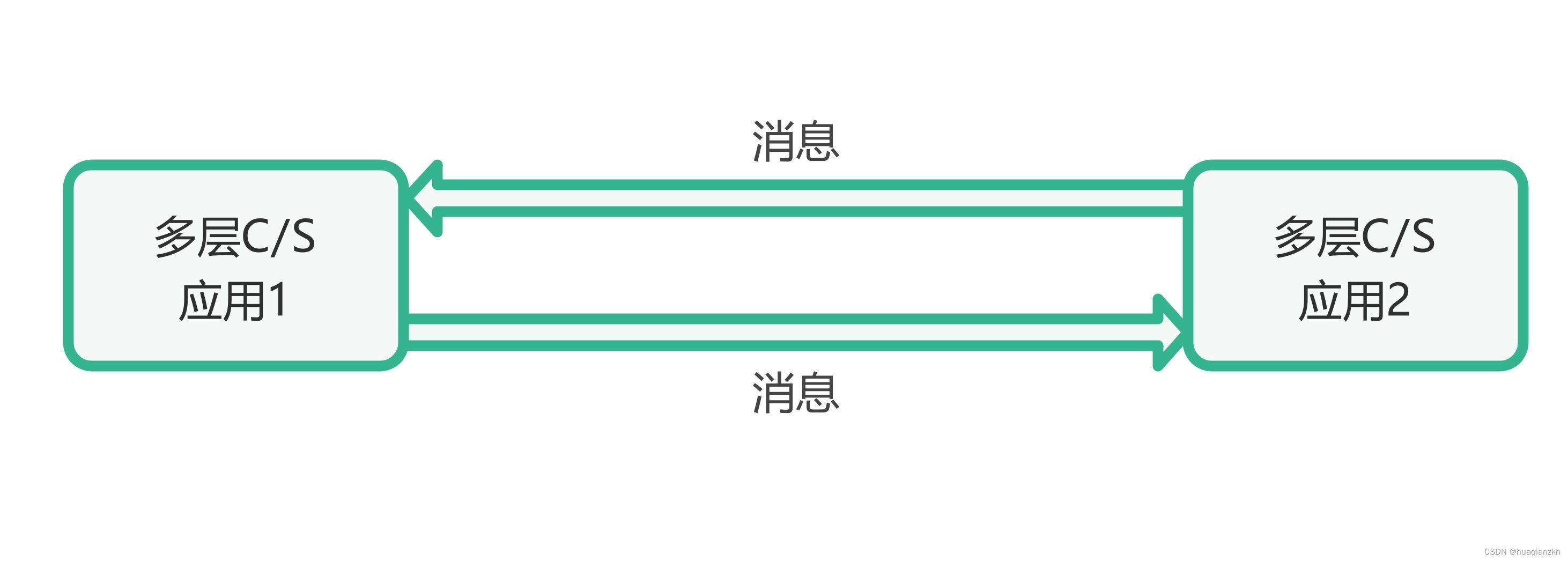
队列中的数据是先入先出(Frist In First Out),这种结构方式就和日常中排队一样,先站队的先拿到货物。在数据结构中就相当于先进入的数据在获取时最先的得到,和栈不同,这里数据的顺序不会被改变,而是和进入结构中的顺序相同。
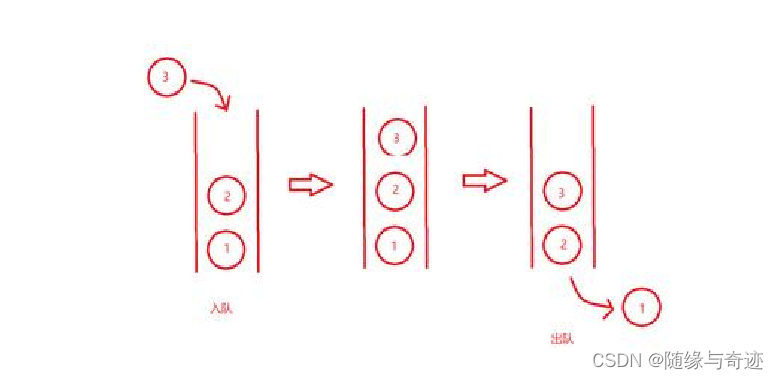
图2-1 队列的数据结构
队列的应用其实在生活中已经有许多地方都能看见了,比如说银行医院的挂号。只要和排队有关的结构用的都是队列。
2. 实现方案
2.1 实现方案
2.1.1. 整体功能
队列,我们需要把它的功能分装成各种函数。它的整体功能大概分为以下几种:
(1)初始化队列的结构。
(2)使用完成后销毁队列开辟的内存空间。
(3)将数据储存到队列中,及入队列。
(4)获得队头或者队尾的数据和删去队头数据。
(5)队列中没有数据就无法执行删除操作,所以需要判断队列内是否有数据。
2.1.2. 实现队列的结构优缺点
2.1.2.1. 用顺序表实现队列
优点:数据结构简单,方便遍历,存数据很方便。
缺点:删除数据需要挪动之后的全部数据,增加数据也可能需要异地扩容,消耗的时间巨大。
2.1.2.2. 用链表实现队列
优点:增加数据方便,直接记录尾数据的位置在之后建立空间插入数据即可。
缺点:指针会额外消耗空间的大小。
其中双向链表的空间消耗会更大,所以通常使用单向链表,用两个指针分别记录头结点和尾结点的位置,方便插入和删除数据。
整体来说队列使用链表会更加好,时间比空间重要的多,链表的模式几乎完全符合队列的需要。通常来说也会选择链表作为队列的结构基础。
2.2. 队列的实现代码
2.2.1. 队列的整体结构
根据2.1. 中所述方式,选择链表作为队列的结构,整体梗概如下:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef int QDataType;
// 链式结构:表示队列
typedef struct QListNode
{
struct QListNode* _next;
QDataType _data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* _front;
QNode* _rear;
}Queue;
// 初始化队列
void QueueInit(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q);
上述代码规定了数据结构的类型、储存的数据类型以及各种函数的作用。
2.2.2. 初始化队列
很简单,就是把代表队列的两个指针指向空,代码如下:
// 初始化队列
void QueueInit(Queue* q)
{
assert(q);
q->_front = q->_rear = NULL;
}2.2.3. 销毁队列
遍历链表并清空申请的空间,代码如下:
// 销毁队列
void QueueDestroy(Queue* q)
{
assert(q);
//用cur遍历链表
QNode* cur = q->_front;
//遍历
while(cur)
{
//保存下一个位置节点
QNode* next = cur->_next;
free(cur);//释放内存
//移动
cur = next;
}
//队列中指针置为NULL
q->_front = q->_rear = NULL;
}2.2.4. 判断队列内数据是否有数据
检查队列中指针是否为空,这里选择的是头指针,代码如下:
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* q)
{
assert(q);
return q->_front == NULL;
}2.2.5. 获取队列中有效数据个数
遍历链表,检查有多少个节点,当然也可以在链表的结构体中定义一个记录数据个数的变量,方便检测,这样就不用遍历了。
// 获取队列中有效元素个数
int QueueSize(Queue* q)
{
assert(q);
if(QueueEmpty(q))
{
return 0;
}
else
{
QNode* cur = q->_front;
int count = 0;
while(cur)
{
++count;
cur = cur->_next;
}
return count;
}
}2.2.6. 向队列中存储数据——入队列
分为两种情况,队列中没有数据,那么就需要将两个指针全部重新指定。另一种,已有数据,就直接插入数据到尾指针之后,然后移动尾指针到尾部。当然其中需要向内存申请节点,并初始化节点。代码如下:
// 队尾入队列
void QueuePush(Queue* q, QDataType data)
{
assert(q);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if(newnode == NULL)
{
perror("QueuePush malloc fail");
return;
}
newnode->_data = data;
newnode->_next = NULL;
if(q->_front == NULL)
{
q->_front = q->_rear = newnode;
}
else
{
q->_rear->_next = newnode;
q->_rear = q->_rear->_next;
}
}2.2.7. 队头出数据——出队列
首先需要判断队列是否为空,其次删除数据分为两种情况,队列中只有一个数据,那就释放节点,头尾指针全部置为空。另一种就是有多个数据,就记录下一个指针的位置,释放头指针位置的内存,然后移动头指针到下一位。
// 队头出队列
void QueuePop(Queue* q)
{
assert(q);
assert(!QueueEmpty(q));
if(q->_front == q->_rear)
{
free(q->_front);
q->_front = q->_rear = NULL;
}
else
{
QNode* next = q->_front->_next;
free(q->_front);
q->_front = next;
}
}2.2.8. 获取头部数据
用头指针查找即可,代码如下:
// 获取队列头部元素
QDataType QueueFront(Queue* q)
{
assert(q);
assert(!QueueEmpty(q));
return q->_front->_data;
}2.2.9. 获取尾部数据
用尾指针查找即可,代码如下:
// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{
assert(q);
assert(!QueueEmpty(q));
return q->_rear->_data;
}3. 测试队列
3.1. 测试内容
检测以上代码的所有内容,初始化、存储数据、输出数据、销毁链表。
3.2. 测试代码
根据3.1. 代码如下:
void TestQueue()
{
Queue qu;
QueueInit(&qu);
QueuePush(&qu, 1);
QueuePush(&qu, 2);
QueuePush(&qu, 3);
QueuePush(&qu, 4);
QueuePush(&qu, 5);
while(!QueueEmpty(&qu))
{
printf("%d ", QueueFront(&qu));
QueuePop(&qu);
}
printf("\n");
QueueEmpty(&qu);
}
int main()
{
TestQueue();
return 0;
}
3.3. 测试结果
根据3.2. 代码,测试结果如下:
![]()
根据测试代码分析结果并无差错。
作者结语
队列和栈,是数据结构中继顺序表链表以来又一个大章,是链表、顺序表的具体应用方式。他们是相互关联的,不同之处在于队列和栈离实际的应用更近一步。在本文中我们分析了队列和栈的实际存储方式以及结构,接下来下一篇的博客会提到一些相关的练习题,方便读者熟系这两种结构。
整体阅读下来,栈和队列相当于是在炒顺序表和链表的“闲饭”,所以对于理解链表和顺序表结构的读者会更好理解本文的含义。
最后希望大家喜欢我的写作风格,如果有错误或者建议欢迎指正。
吐槽:弹夹的图片还显示不让发,违规。我直接乐了。