本文分享自华为云社区《【MySQL技术专栏】GaussDB(for MySQL) Big IN查询优化》,作者:GaussDB 数据库。

1 背景介绍
在生产环境中,SQL查询中经常包含带有IN表达式的过滤条件,特别是当IN列表涉及大量值时,性能问题尤为突出。以在线商店为例,假设你需要查询在特定的一组产品ID中哪些产品已经被购买过,而这个产品ID列表可能包含成千上万个ID。
SELECT product_id, purchase_date FROM purchases WHERE product_id IN (1, 2, 3, ..., 100000); -- 假设有10万个产品ID当product_id是一个索引列时,MySQL优化器通常会尝试使用索引来加速查询。然而,当IN列表中的值非常多时,优化器可能需要花费大量的内存和CPU时间来处理这些值,这可能导致查询性能下降。
MySQL提供了一个系统变量range_optimizer_max_mem_size,用于限制优化器在range查询优化过程中可使用的最大内存量。如果优化器在尝试进行range优化时超出了这个限制,它可能会选择不使用索引,转而使用全表扫描或其他不太高效的查询策略,这进一步降低了查询性能。
为了解决这个问题,GaussDB(for MySQL)引入了一个名为Big IN优化的特性。这个特性专门针对长IN列表进行了优化,旨在减少因处理大量IN值而导致的性能下降。通过GaussDB的Big IN优化,数据库系统可以更高效地处理包含大量值的IN列表,减少内存和CPU的消耗,从而加快查询速度。
使用GaussDB的Big IN优化,用户可以期望在遇到长IN列表的查询时获得更好的性能,减少查询执行时间,并提高系统的整体稳定性。这对于处理大量数据的生产环境至关重要,因为它能够确保数据库在高负载下仍然保持高效运行。
2 MySQL优化
开源MySQL在处理column IN (const1, const2, .... )时,如果column上面有索引,优化器会选择Range scan进行扫描,否则会使用全表扫描方式。range_optimizer_max_mem_size系统变量控制range优化分析过程中可使用的最大内存。如果IN谓词的列表元素非常多,IN中的每个内容会被视为OR,每个OR大约占用230字节,如果元素个数很多,则使用更多的内存。如果使用的内存会超过定义的最大内存,会使得range优化失效,优化器将会改变策略,如转换为全表扫描,从而引发查询的性能下降。
对于此优化问题,可以通过调整range_optimizer_max_mem_size来处理。range_optimizer_max_mem_size定义的内存是session级别的,每个session执行该类型的语句,都会占用同样的内存,在大并发场景下,会导致实例内存升高,引入实例OOM风险。
对于范围查询,MySQL定义了eq_range_index_dive_limit系统变量,来控制在处理等值范围查询时,优化器是否进行索引潜水(index dive)。index dive是利用索引完成元组数的估算,可以得到更精确的信息,从而做出更好的查询优化策略,但是耗时也长。在IN组合数超过一定数量时候就不适用index dive,系统采用静态索引统计信息值来选择索引,这种方法得到的结果未必精确。这可能导致MySQL不能很好的利用索引,导致性能回退。
3 GaussDB(for MySQL)的Big IN优化
GaussDB(for MySQL)解决Big IN性能问题的方法是将大IN谓词转换为IN子查询。也就是说,IN谓词的形式为
column IN (const1, const2, ....)转换为等效的IN子查询:
column IN (SELECT ... FROM temporary_table)经过上述的变化,IN函数查询变成了一个IN子查询,并且该子查询是非相关子查询。
对于IN非相关子查询,mysql优化器提供了semi-join materialization策略进行优化处理。Semi-join Materialization策略就是把子查询结果物化成临时表,然后和外表进行联接。如下图所示。
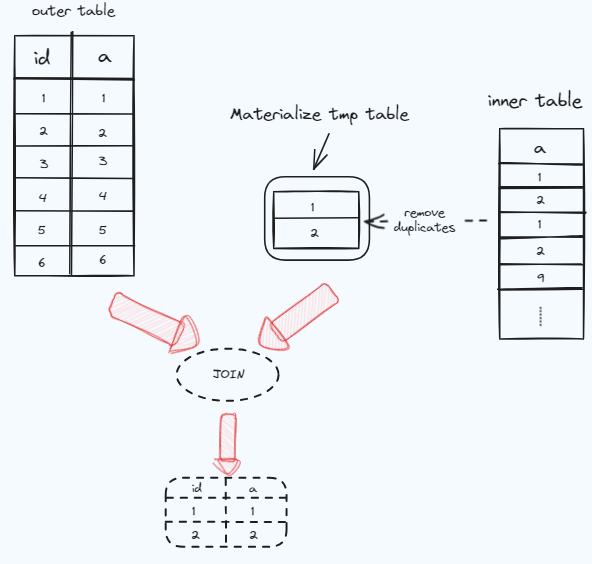
联接可以有两个顺序:
- Materialization-scan :表示从物化表到外表,会对物化表进行全表扫描。
- Materialization-lookup :表示从外表到物化表,在物化表中查找数据时候可以使用主建进行查找。
Materialization-scan
- 执行子查询,走索引auto_distinct_key,同时会对结果进行去重;
- 将上一步的结果保存在临时表template1里;
- 从临时表中取一行数据,到外表中查找满足联接条件的行;
- 重复步骤3,直到遍历临时表结束。
Materialization-lookup
- 先执行子查询;
- 将上一步得到的结果保存到临时表中;
- 从外表中取出一行数据,到物化临时表中去查找满足联接条件的行,走物化表的主键,每次扫描1行;
- 重复3,直到遍历整个外表。
优化器会根据内外表的大小来选择不同的联接顺序。真实场景中,一般单表查询的表的数据量很大,上千万甚至上亿;IN列表中的元素个数远小于表数量,优化器会选择Materialization-scan方式进行扫描,外表查询时候如果走主键索引,则优化后的总的扫描行数为N,当M远大于N时,性能提升会非常明显。
4 使用方法
rds_in_predicate_conversion_threshold参数是IN谓词转子查询功能开关,当SQL语句的IN谓词列表中的元素个数超过该参数的取值时,将启动该优化策略。通过修改该变量的值来使用该功能。下面通过一个简单的例子说明该优化的使用。
表结构
create table t1(id int, a int, key idx1(a)); 查询语句
select * from t1 where a in (1,2,3,4,5);设置set rds_in_predicate_conversion_threshold = 0 和 set range_optimizer_max_mem_size=1关闭大IN谓词优化功能和range scan优化策略,查看上述查询语句的执行计划,结果如下:
> set rds_in_predicate_conversion_threshold = 0; > set range_optimizer_max_mem_size=1; > explain select * from t1 where a in (1,2,3,4,5);
结果如下:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t3 | NULL | ALL | key1 | NULL | NULL | NULL | 3 | 50.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 2 warnings (0.00 sec)
show warnings; +---------+------+---------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+---------------------------------------------------------------------------------------------------------------------------+ | Warning | 3170 | Memory capacity of 1 bytes for 'range_optimizer_max_mem_size' exceeded. Range optimization was not done for this query. | | Note | 1003 | /* select#1 */ select `test`.`t3`.`id` AS `id`,`test`.`t3`.`a` AS `a` from `test`.`t3` where (`test`.`t3`.`a` in (3,4,5)) | +---------+------+---------------------------------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec)
发现上述语句执行时候报了warning, warning的信息显示因为range optimization过程中使用的内存超过了range_optimizer_max_mem_size限制导致对于该语句不使用range optimization。从而扫描的type变为了ALL, 退化为全表扫描。
设置set rds_in_predicate_conversion_threshold = 3开启大IN谓词优化选项,表示当IN谓词列表元素超过3个时候,启动Big IN转子查询优化策略。执行EXPLAIN FORMAT=TREE语句可以查看优化是否生效。
> set rds_in_predicate_conversion_threshold = 3; > explain format=tree select * from t1 where a in (1,2,3,4,5); +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPLAIN | +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | -> Nested loop inner join (cost=0.70 rows=1) -> Filter: (t1.a is not null) (cost=0.35 rows=1) -> Table scan on t1 (cost=0.35 rows=1) -> Single-row index lookup on <in_predicate_2> using <auto_distinct_key> (a=t1.a) (cost=0.35 rows=1) | +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
执行计划中的<in_predicate_*>(*为数字)表为Big INT优化中构造的临时表,存储了IN谓词列表中的所有数据。
5 使用限制
Big IN优化支持的查询语句包括如下列表的语句:
- SELECT
- INSERT ... SELECT
- REPLACE ... SELECT
- 支持视图
- PREPARED STMT
约束与限制
Big IN转子查询,借助mysql提供的子查询优化方案来实现高性能,因此在使用上有如下限制,否则反而会降低性能。
- 不支持无法使用索引的场景
- 只支持常量IN LIST(包括NOW(), ? 等不涉及表查询的语句)。
- 不支持STORED PROCEDURE/FUNCTION/TRIGGER。
- 不支持NOT IN。
6 典型场景测试对比
测试表结构如下:
CREATE TABLE `sbtest1` ( `id` int NOT NULL AUTO_INCREMENT, `k` int NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB;
表的数据量为1000w。
> select count(*) from sbtest1; +----------+ | count(*) | +----------+ | 10000000 | +----------+
查询语句如下,where条件字段是有索引,IN列表里包含1万个常量数字。
select count(*) from sbtest1 where k in (2708275,5580784,7626186,8747250,228703,4589267,5938459,6982345,2665948,4830545,4929382,8723757,354179,1903875,5111120,5471341,7098051,3113388,2584956,6550102,2842606,2744112,7077924,4580644,5515358,1787655,6391388,6044316,2658197,5628504,413887,6058866,3321587,1430333,445303,7373496,9133196,6760595,4735642,4756387,9845147,9362192,7271805,4351748,6625915,3813276,4236692,8308973,4407131,9481423,3301846,432577,810938,3830320,6120078,6765157,6456566,6649509,1123840,2906490,9965014,3725748, ... );
性能对比如下图所示:
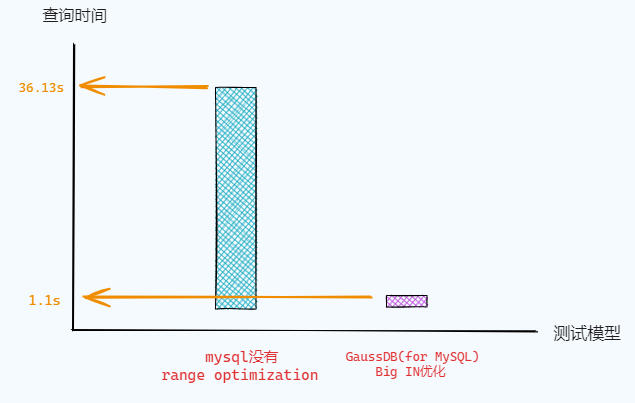
可以看出in-list优化后比原生的方式性能提高了36倍。

























![[正则表达式]正则表达式语法与运用(Regular Expression, Regex)](https://img-blog.csdnimg.cn/img_convert/84744fc37c0b78e84ad1eaec0277574e.png)