1 Introduction
这一章,karpathy通过分析参数初始化对模型的收敛的影响作为一个引子,让我们看到神经网络这一个复杂的系统,对grad非常敏感,以及有一些技巧可以解决grad敏感的问题。
2 准备工作
2.1 dataloader
import torch
block_size = 3
def generate_datasets(words):
X = []
Y = []
for w in words:
context = [0] * block_size
for char in w + '.':
ix = stoi[char]
X.append(context)
Y.append(ix)
context = context[1:] + [ix]
Xb = torch.tensor(X)
Yb = torch.tensor(Y)
return Xb, Yb
import random
random.shuffle(words)
total_size = len(words)
n_train = int(0.8 * total_size)
n_val = int(0.9 * total_size)
Xtr, Ytr = generate_datasets(words[:n_train])
Xdev, Ydev = generate_datasets(words[n_train:n_val])
Xte, Yte = generate_datasets(words[n_val:])
2.2 embedding
我们要复现这个网络,这里embedding采用了一个Matrix C。并且在这个系列的第二部分,我们也看到了字符和Matrix中的映射关系。
从字符转换成字符索引
stoi = {char : i + 1 for i, char in enumerate(sorted(set(''.join(words))))}
stoi['.'] = 0
itos = {i : char for char, i in stoi.items()}
vocab_size = len(itos)
print(vocab_size)
从字符索引转换成embedding, 这里
n_batch = 32
n_emb = 10
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb = Xtr[ix]
Xb
C = torch.randn(vocab_size, n_emb, generator=g)
emb = C[Xb]
print(emb.shape)
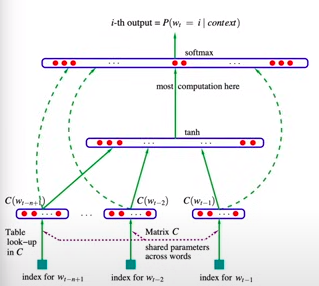
2.3 定义网络结构
初始化参数
n_hidden = 200
W1 = torch.randn(n_emb * block_size, n_hidden, generator=g)
b1 = torch.randn(n_hidden, generator=g)
W2 = torch.randn(n_hidden, vocab_size, generator=g)
b2 = torch.randn(vocab_size, generator=g)
parameters = [C, W1, b1, W2, b2]
for p in parameters:
p.requires_grad = True
开始训练
import torch.nn.functional as F
max_iter = 200000
lossi = []
for i in range(max_iter):
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix]
emb = C[Xb]
hprect = torch.tanh(emb.view(n_batch, -1) @ W1 + b1)
logits = hprect @ W2 + b2
loss = F.cross_entropy(logits, Yb)
for p in parameters:
p.grad = None
loss.backward()
lr = 0.1 if i < 100000 else 0.01
with torch.no_grad():
for p in parameters:
p.data -= lr * p.grad.data
lossi.append(loss.item())
if i % 1000 == 0:
print(f"Iteration: {i}/{max_iter}, Loss: {loss.item()}")
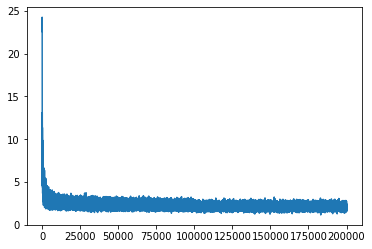
对比一下训练集和测试集的差距
@torch.no_grad()
def batch_infer(datasets):
X, Y = {
'train' : (Xtr, Ytr),
'val' : (Xdev, Ydev),
'test' : (Xte, Yte),
}[datasets]
emb = C[X]
hprect = emb.view(-1, block_size * n_emb) @ W1 + b1
logits = torch.tanh(hprect) @ W2 + b2
loss = F.cross_entropy(logits, Y)
print(f"{datasets} loss is {loss.item()}")
batch_infer('train')
batch_infer('val')
train loss is 2.1050491333007812
val loss is 2.1596949100494385
观察一下目前的网络输出的结果怎么样
for _ in range(20):
context = [0] * block_size
ch = []
while(True):
X = torch.tensor(context)
emb = C[X]
hprect = emb.view(-1, block_size * n_emb) @ W1 + b1
logits = torch.tanh(hprect) @ W2 + b2
probs = torch.softmax(logits, dim=-1).squeeze(0)
ix = torch.multinomial(probs, num_samples=1).item()
context = context[1:] + [ix]
ch.append(itos[ix])
if ix == 0:
break
print(''.join(ch))
输出的结果是:
dar.
charia.
arlonathana.
jana.
avietaviannee.
dex.
aarion.
laron.
westishawmyraddia.
julatamyae.
sharha.
gius.
daviyan.
laydi.
sha.
rudya.
hal.
masiel.
aari.
kelya.
3 参数初始化诊断
3.1 分析参数初始化的结果
- step1: 理论分析初始的loss
torch.tensor([1/28]).log()
tensor([3.3322])
目前的第一次迭代的loss是22.5远大于3.33
分析一下为什么会这样
主要看一下logits的结果是如何影响loss的
logits = torch.tensor([1., 1., 1., 1.])
log_softmax = F.softmax(logits, dim=0)
loss = -log_softmax[1].log()
print(loss.item())
1.3862943649291992
logits = torch.tensor([1., -2., 1., 2.])
log_softmax = F.softmax(logits, dim=0)
loss = -log_softmax[1].log()
print(loss.item())
4.561941146850586
也就是说logits如果有出现负数的情况,就很容易导致初始的误差非常大
这个分布非常的不好,太宽了
import matplotlib.pyplot as plt
# 绘制直方图
plt.figure(figsize=(8, 6))
plt.hist(logits.flatten().detach(), bins=50)
plt.title("Logits Distribution")
plt.xlabel("Value")
plt.ylabel("Frequency")
plt.show()
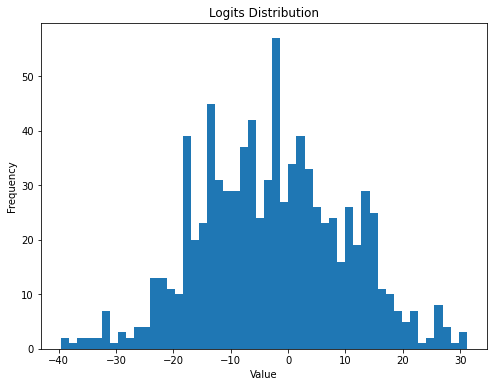
那么我们就可以将我们的W2和b2 修改一下
W2 = torch.randn(n_hidden, vocab_size, generator=g) * 0.1
b2 = torch.randn(vocab_size, generator=g) * 0
Iteration: 0/200000, Loss: 4.399700164794922
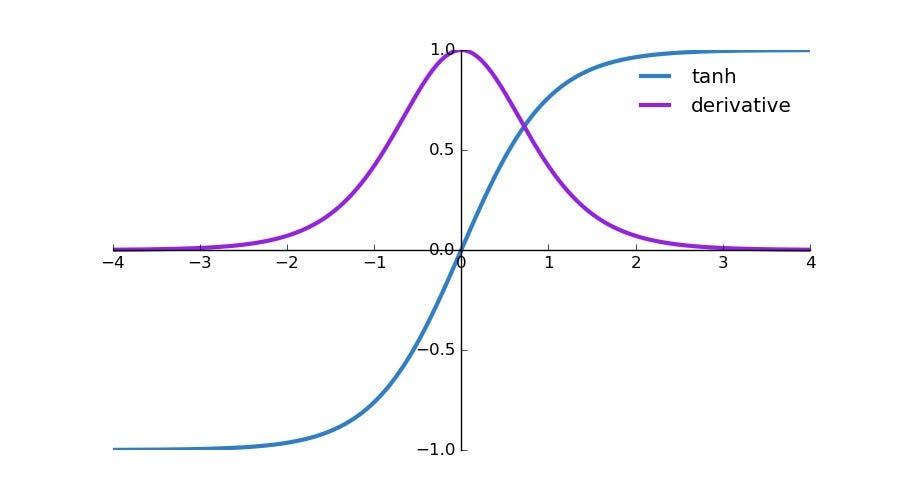
- step2: 关注激活函数
这里使用的是tanh作为激活函数,如果初始的时候,tanh的数值很大,那么很有可能grad就变得很小,后续即使迭代了,也没法更新参数。
方式1: 直接查看hprect的直方图以及输入的直方图
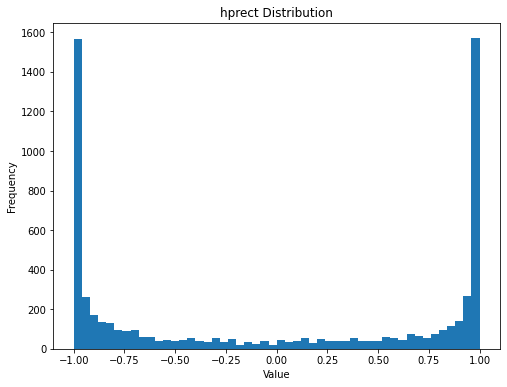
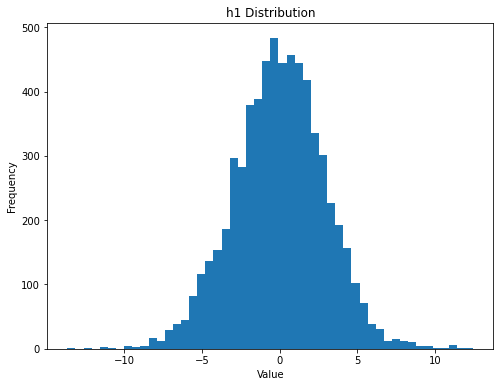
可以看到是因为输入到tanh的数值分布太广了,至少还需要缩小0.1。
我们还有一个工具,可以查看激活函数的输入输出对整体的batch_size的结果:
可以看到有一列完全都是白的,也就是kernel dead
import numpy as np
# 绘制灰度图
plt.figure(figsize=(8, 6))
plt.imshow(hprect.abs() > 0.99, cmap='gray', interpolation='nearest')
plt.show()

更正修改W1的参数到0.2
实际上来说我这个参数还是不太好
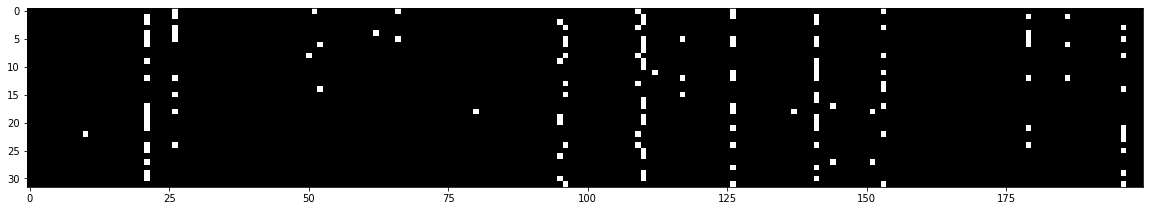
- 理论分析
随着网络深度的加深,方差会越来越大。
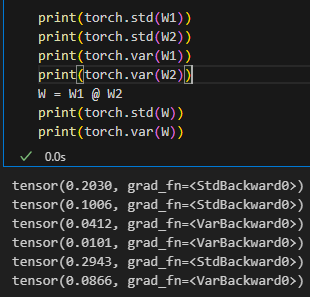
所以需要对参数要进行系数进行缩放。
3.2 手动进行缩放
kaiming的论文[1],
W1 = torch.randn(n_emb * block_size, n_hidden, generator=g) * (5/3) / (n_emb * block_size) ** 0.5
b1 = torch.randn(n_hidden, generator=g) * 0.01
W2 = torch.randn(n_hidden, vocab_size, generator=g) * 0.01
b2 = torch.randn(vocab_size, generator=g) * 0
这一次的loss分布是
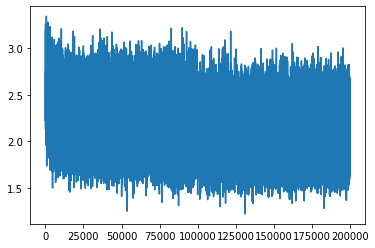
已经分不太出来趋势了,需要处理一下,
avg_lossi = np.mean(np.array(lossi[:len(lossi)//1000*1000]).reshape(-1,1000), axis=1)
plt.figure(figsize=(8, 6))
plt.plot(avg_lossi)
plt.xlabel('Iterations (x1000)'), plt.ylabel('Average Loss'), plt.title('Training Loss')
plt.show()
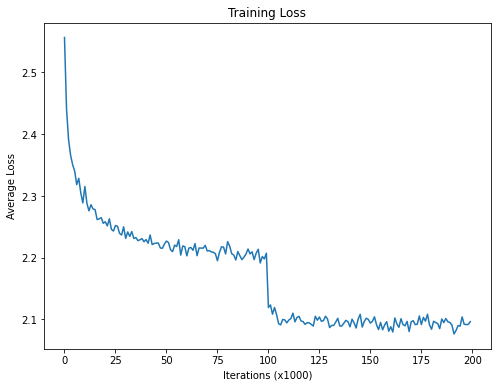
在迭代100000万次的时候loss发生了突变,因为这个时候我们的学习率发生了较大的变化。
3.3 通过batchnorm
思想也很简单,在第一次进入activation的时候,我们希望对输入做一次标准化处理,防止数据过于集中,或者过于分散。
- 用统计的方法计算均值和方差,然后再进入activation的时候去.
但是这样的结果有一个问题,设计上来说我们只希望在初始的时候,进行batchnorm,后面每次迭代的时候并不希望还继续batchnorm。
n_hidden = 200
W1 = torch.randn(n_emb * block_size, n_hidden, generator=g)
b1 = torch.randn(n_hidden, generator=g) * 0
W2 = torch.randn(n_hidden, vocab_size, generator=g) * 0.01
b2 = torch.randn(vocab_size, generator=g) * 0
bngain = torch.ones((1, n_hidden))
bnbias = torch.zeros((1, n_hidden))
bnmean_running = torch.zeros((1, n_hidden))
bnstd_running = torch.ones((1, n_hidden))
parameters = [C, W1, b1, W2, b2, bngain, bnbias]
for p in parameters:
p.requires_grad = True
import torch.nn.functional as F
max_iter = 200000
lossi = []
for i in range(max_iter):
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix]
emb = C[Xb]
hpreact = emb.view(n_batch, -1) @ W1 + b1
bnmeani = hpreact.mean(0, keepdim=True)
bnstdi = hpreact.std(0, keepdim=True)
hpreact = bngain * (hpreact - bnmeani) / bnstdi + bnbias
with torch.no_grad():
bnmean_running = 0.999 * bnmean_running + 0.001 * bnmeani
bnstd_running = 0.999 * bnstd_running + 0.001 * bnstdi
h = torch.tanh(hpreact)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, Yb)
for p in parameters:
p.grad = None
loss.backward()
lr = 0.1 if i < 100000 else 0.01
with torch.no_grad():
for p in parameters:
p.data -= lr * p.grad
lossi.append(loss.item())
if i % 1000 == 0:
print(f"Iteration: {i}/{max_iter}, Loss: {loss.item()}")
# break
这里比较麻烦的地方在于,(hp - hp_mean_running) / (hp_var_running + 1e-5),因为这里采用的是batchnorm,采用广播方式,对于每个batch 样本进行归一化处理。
h = gamma * ((hp - hp_mean_running) / (hp_var_running + 1e-5)) + beta
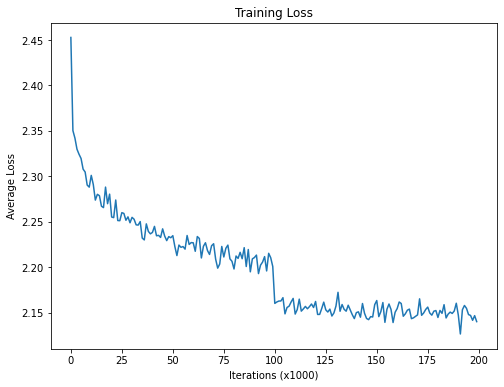
进行校验:
@torch.no_grad()
def batch_infer(datasets):
X, Y = {
'train' : (Xtr, Ytr),
'val' : (Xdev, Ydev),
'test' : (Xte, Yte),
}[datasets]
emb = C[X]
hpreact = emb.view(emb.shape[0], -1) @ W1
hpreact = bngain * (hpreact - bnmean_running) / bnstd_running + bnbias
h = torch.tanh(hpreact) # (N, n_hidden)
logits = h @ W2 + b2 # (N, vocab_size)
loss = F.cross_entropy(logits, Y)
print(f'{datasets}, loss is: {loss}')
batch_infer('train')
batch_infer('val')
这次的结果
train, loss is: 2.1178481578826904
val, loss is: 2.1550681591033936
4 使用torch的高级语法
我们现在的网络比较简单,在我们将网络扩展到更深的网络之前,我们需要将之前代码按照torch开发模式,进行转换
4.1定义一个最基础的网络
import torch
class Linear:
def __init__(self, in_features, out_features, bias=True):
self.weight = torch.randn(in_features, out_features, generator=g) / in_features ** 0.5
self.bias = torch.zeros(out_features) if bias else None
def __call__(self, x):
self.out = x @ self.weight
if self.bias is not None:
self.out += self.bias
return self.out
def parameters(self):
return [self.weight] + ([] if self.bias is None else [self.bias])
class Tanh:
def __call__(self, x):
self.out = torch.tanh(x)
return self.out
def parameters(self):
return []
class BatchNorm1D:
def __init__(self, n_layers, eps=1e-5, momentum = 0.1):
self.gain = torch.ones(n_layers)
self.bias = torch.zeros(n_layers)
self.bn_mean_running = torch.zeros(n_layers)
self.bn_std_running = torch.ones(n_layers)
self.training = True
self.momentum = momentum
self.eps = eps
def __call__(self, x):
if self.training:
bn_meani = x.mean(0, keepdim=True)
bn_stdi = x.var(0, keepdim=True)
else:
bn_meani = self.bn_mean_running
bn_stdi = self.bn_std_running
self.out = self.gain * (x - bn_meani) / (bn_stdi + self.eps) + self.bias
if self.training:
with torch.no_grad():
self.bn_mean_running = (1 - self.momentum) * self.bn_mean_running + self.momentum* self.bn_meani
self.bn_std_running = (1 - self.momentum) * self.bn_std_running + self.momentum * self.bn_stdi
return self.out
def parameters(self):
return [self.gain, self.bias]
参数初始化
layers = [Linear(block_size*n_emb, n_hidden), Tanh(),
Linear(n_hidden, n_hidden), Tanh(),
Linear(n_hidden, n_hidden), Tanh(),
Linear(n_hidden, n_hidden), Tanh(),
Linear(n_hidden, vocab_size)
]
# 设置参数属性
C = torch.randn(vocab_size, n_emb, generator=g)
parameters = [C] + [p for layer in layers for p in layer.parameters()]
with torch.no_grad():
# layers[-1].gamma *= 0.1
layers[-1].weight *= 0.1
for layer in layers[:-1]:
if isinstance(layer, Linear):
layer.weight *= 5/3
for p in parameters:
p.requires_grad = True
进行网络训练
import torch.nn.functional as F
max_iter = 200000
lossi = []
for i in range(max_iter):
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix]
emb = C[Xb]
x = emb.view(-1, block_size*n_emb)
for layer in layers:
x = layer(x)
logits = x
loss = F.cross_entropy(logits, Yb)
for p in parameters:
p.grad = None
loss.backward()
lr = 0.1 if i < 100000 else 0.01
for p in parameters:
p.data -= lr * p.grad
lossi.append(loss.item())
if i % 1000 == 0:
print(f"Iteration: {i}/{max_iter}, Loss: {loss.item()}")
break
接下来我们还是一样,希望看一下激活函数的输出分布
import matplotlib.pyplot as plt
# visualize histograms
plt.figure(figsize=(20, 4)) # width and height of the plot
legends = []
for i, layer in enumerate(layers[:-1]): # note: exclude the output layer
if isinstance(layer, Tanh):
t = layer.out
print('layer %d (%10s): mean %+.2f, std %.2f, saturated: %.2f%%' % (i, layer.__class__.__name__, t.mean(), t.std(), (t.abs() > 0.97).float().mean()*100))
hy, hx = torch.histogram(t, density=True)
plt.plot(hx[:-1].detach(), hy.detach())
legends.append(f'layer {i} ({layer.__class__.__name__}')
plt.legend(legends);
plt.title('activation distribution')
layer 1 ( Tanh): mean +0.01, std 0.71, saturated: 11.75%
layer 3 ( Tanh): mean -0.01, std 0.68, saturated: 7.56%
layer 5 ( Tanh): mean +0.02, std 0.67, saturated: 6.77%
layer 7 ( Tanh): mean +0.02, std 0.67, saturated: 7.23%
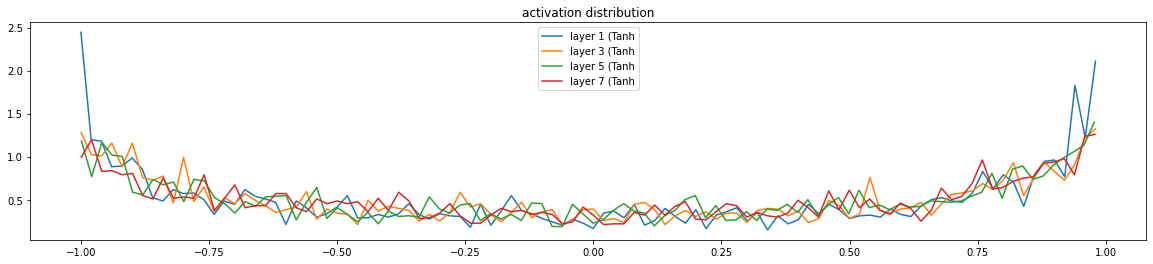
从图中可以按出来第一层还是出现很多激活函数的输出在边界,在来看一下grad的分布
这里需要注意,如果需要查看中间的grad结果,需要在正向传播的时候,retain_grad这样才能查看
for layer in layers:
layer.out.retain_grad() # AFTER_DEBUG: would take out retain_graph
整体的grad还是非常小的
layer 1 ( Tanh): mean -0.000008, std 2.809027e-04
layer 3 ( Tanh): mean +0.000006, std 2.608607e-04
layer 5 ( Tanh): mean -0.000004, std 2.412728e-04
layer 7 ( Tanh): mean -0.000004, std 2.213307e-04
整体看一下所有参数grad的分布,如果大量的分布在0附近,表示参数出现dead的情况很多
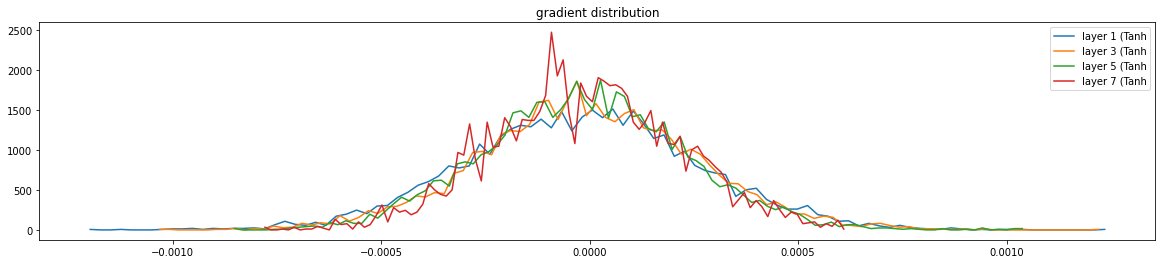
#整体看一下grad
# visualize histograms
plt.figure(figsize=(20, 4)) # width and height of the plot
legends = []
for i, p in enumerate(parameters):
t = p.grad
if p.ndim == 2:
print('weight %10s | mean %+f | std %e | grad:data ratio %e' % (tuple(p.shape), t.mean(), t.std(), t.std() / p.std()))
hy, hx = torch.histogram(t, density=True)
plt.plot(hx[:-1].detach(), hy.detach())
legends.append(f'{i} {tuple(p.shape)}')
plt.legend(legends)
plt.title('weights gradient distribution')
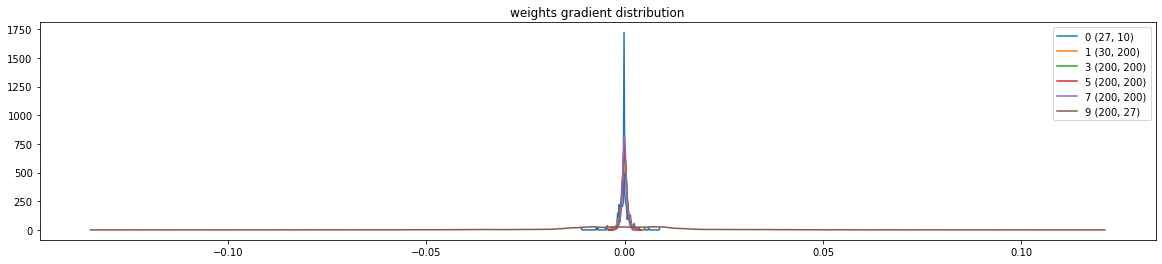
我们现在这个参数初始化还是不太好,需要加上batchNorm1D
g = torch.Generator().manual_seed(2147483647)
n_hidden = 100
n_emb = 10
layers = [
Linear(block_size*n_emb, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size, bias=False), BatchNorm1d(vocab_size),
]
# 设置参数属性
C = torch.randn(vocab_size, n_emb, generator=g)
parameters = [C] + [p for layer in layers for p in layer.parameters()]
with torch.no_grad():
layers[-1].gamma *= 0.1
# layers[-1].weight *= 0.1
for layer in layers[:-1]:
if isinstance(layer, Linear):
layer.weight *= 1.0
for p in parameters:
p.requires_grad = True
import torch.nn.functional as F
max_iter = 200000
lossi = []
for i in range(max_iter):
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix]
emb = C[Xb]
x = emb.view(-1, block_size*n_emb)
for layer in layers:
x = layer(x)
logits = x
loss = F.cross_entropy(logits, Yb)
for layer in layers:
layer.out.retain_grad() # AFTER_DEBUG: would take out retain_graph
for p in parameters:
p.grad = None
loss.backward()
lr = 0.1 if i < 100000 else 0.01
for p in parameters:
p.data -= lr * p.grad
lossi.append(loss.item())
if i % 1000 == 0:
print(f"Iteration: {i}/{max_iter}, Loss: {loss.item()}")
break
激活函数的输出饱和程度好了很多
layer 2 ( Tanh): mean +0.01, std 0.63, saturated: 2.94%
layer 5 ( Tanh): mean -0.00, std 0.63, saturated: 3.25%
layer 8 ( Tanh): mean -0.01, std 0.64, saturated: 2.69%
layer 11 ( Tanh): mean -0.00, std 0.63, saturated: 3.03%
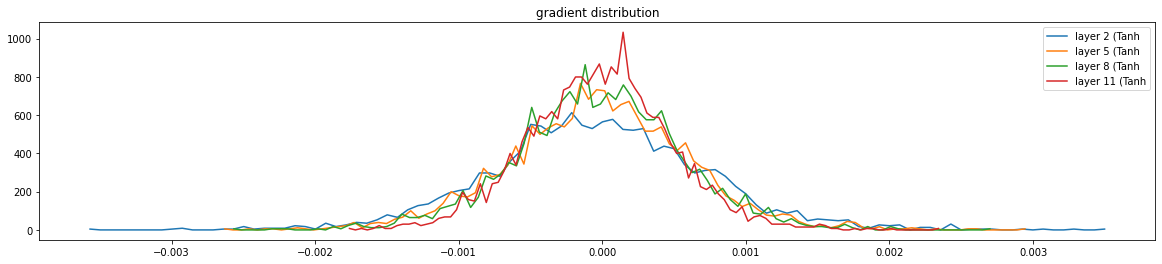
激活函数的grad
方差和标准差是一个量级的
layer 2 ( Tanh): mean +0.000000, std 7.608066e-04
layer 5 ( Tanh): mean +0.000000, std 6.368941e-04
layer 8 ( Tanh): mean -0.000000, std 5.829208e-04
layer 11 ( Tanh): mean +0.000000, std 4.975214e-04
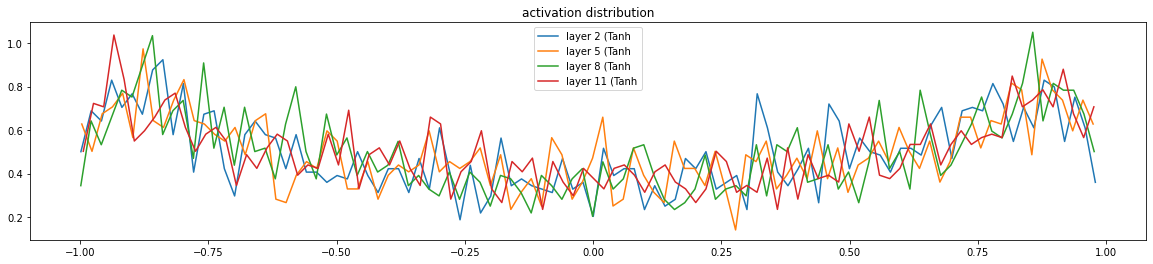
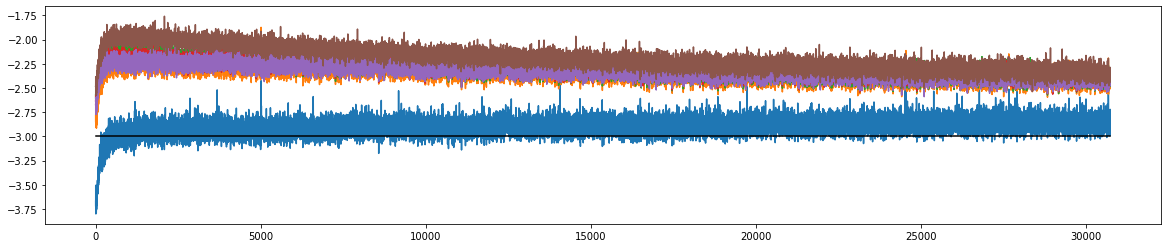
4.2 如何查看学习的速度
查看grad和参数值的比值
import torch.nn.functional as F
max_iter = 200000
lossi = []
ud = []
for i in range(max_iter):
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix]
emb = C[Xb]
x = emb.view(-1, block_size*n_emb)
for layer in layers:
x = layer(x)
logits = x
loss = F.cross_entropy(logits, Yb)
for layer in layers:
layer.out.retain_grad() # AFTER_DEBUG: would take out retain_graph
for p in parameters:
p.grad = None
loss.backward()
lr = 0.1 if i < 100000 else 0.01
for p in parameters:
p.data -= lr * p.grad
lossi.append(loss.item())
with torch.no_grad():
ud.append([((-lr * p.grad).std() / p.data.std()).log10().item() for p in parameters])
if i % 1000 == 0:
print(f"Iteration: {i}/{max_iter}, Loss: {loss.item()}")
# break
显示图像
plt.figure(figsize=(20, 4))
legends = []
for i,p in enumerate(parameters):
if p.ndim == 2:
plt.plot([ud[j][i] for j in range(len(ud))])
legends.append('param %d' % i)
plt.plot([0, len(ud)], [-3, -3], 'k') # these ratios should be ~1e-3, indicate on
References
[1] Kaiming init" paper: https://arxiv.org/abs/1502.01852


![[Godot<span style='color:red;'>3</span>.<span style='color:red;'>3</span>.<span style='color:red;'>3</span>] - 过渡动画](https://img-blog.csdnimg.cn/img_convert/99bf312fca21e060513affbac9528022.png)