教学目标
1>认识Elasticsearch
2>了解全文搜索引擎
3>了解Elasticsearch安装与基本操作
4>了解Elasticsearch文档CRUD操作
5>了解Elasticsearch全文搜索
6>了解SpringBoot集成Elasticsearch
认识Elasticsearch
搜索引擎
概念
所谓搜索引擎,就是根据用户需求与一定算法,运用特定策略从互联网检索出指定信息反馈给用户的一门检索技术。搜索引擎依托于多种技术,如网络爬虫技术、检索排序技术、网页处理技术、大数据处理技术、自然语言处理技术等,为信息检索用户提供快速、高相关性的信息服务。搜索引擎技术的核心模块一般包括爬虫、索引、检索和排序等,同时可添加其他一系列辅助模块,以为用户创造更好的网络使用环境。
分类
全文搜索引擎
一般网络用户适用于全文搜索引擎。这种搜索方式方便、简捷,并容易获得所有相关信息。但搜索到的信息过于庞杂,因此用户需要逐一浏览并甄别出所需信息。尤其在用户没有明确检索意图情况下,这种搜索方式非常有效。
元搜索引擎
元搜索引擎适用于广泛、准确地收集信息。不同的全文搜索引擎由于其性能和信息反馈能力差异,导致其各有利弊。元搜索引擎的出现恰恰解决了这个问题,有利于各基本搜索引擎间的优势互补。而且本搜索方式有利于对基本搜索方式进行全局控制,引导全文搜索引擎的持续改善。
垂直搜索引擎
垂直搜索引擎适用于有明确搜索意图情况下进行检索。例如,用户购买机票、火车票、汽车票时,或想要浏览网络视频资源时,都可以直接选用行业内专用搜索引擎,以准确、迅速获得相关信息。
目录搜索引擎
目录搜索引擎是网站内部常用的检索方式。本搜索方式指在对网站内信息整合处理并分目录呈现给用户,但其缺点在于用户需预先了解本网站的内容,并熟悉其主要模块构成。总而观之,目录搜索方式的适应范围非常有限,且需要较高的人工成本来支持维护。
新网页搜索引擎
2022年6月3日消息,苹果将推出以用户为中心的新网页搜索引擎。
发展趋势
1、社会化搜索
社交网络平台和应用占据了互联网的主流,社交网络平台强调用户之间的联系和交互,这对传统的搜索技术提出了新的挑战。
传统搜索技术强调搜索结果和用户需求的相关性,社会化搜索除了相关性外,还额外增加了一个维度,即搜索结果的可信赖性。对某个搜索结果,传统的结果可能成千上万,但如果处于用户社交网络内其他用户发布的信息、点评或验证过的信息则更容易信赖,这是与用户的心里密切相关的。社会化搜索为用户提供更准确、更值得信任的搜索结果。
2、实时搜索
对搜索引擎的实时性要求日益增高,这也是搜索引擎未来的一个发展方向。
实时搜索最突出的特点是时效性强,越来越多的突发事件首次发布在微博上,实时搜索核心强调的就是“快”,用户发布的信息第一时间能被搜索引擎搜索到。不过在国内,实时搜索由于各方面的原因无法普及使用,比如Google的实时搜索是被重置的,百度也没有明显的实时搜索入口。
3、移动搜索
随着智能手机的快速发展,基于手机的移动设备搜索日益流行,但移动设备有很大的局限性,比如屏幕太小,可显示的区域不多,计算资源能力有限,打开网页速度很慢,手机输入繁琐等问题都需要解决。
目前,随着智能手机的快速普及,移动搜索一定会更加快速的发展,所以移动搜索的市场占有率会逐步上升,而对于没有移动版的网站来说,百度也提供了“百度移动开放平台”来弥补这个缺失。
4、个性化搜索
个性化搜索主要面临两个问题:如何建立用户的个人兴趣模型?在搜索引擎里如何使用这种个人兴趣模型? [3]
个性化搜索的核心是根据用户的网络行为,建立一套准确的个人兴趣模型。而建立这样一套模型,就要全民收集与用户相关的信息,包括用户搜索历史、点击记录、浏览过的网页、用户E-mail信息、收藏夹信息、用户发布过的信息、博客、微博等内容。比较常见的是从这些信息中提取出关键词及其权重。为不同用户提供个性化的搜索结果,是搜索引擎总的发展趋势,但现有技术有很多问题,比如个人隐私的泄露,而且用户的兴趣会不断变化,太依赖历史信息,可能无法反映用户的兴趣变化。
5、地理位置感知搜索
目前,很多手机已经有GPS的应用了,这是基于地理位置感知的搜索,而且可以通过陀螺仪等设备感知用户的朝向,基于这种信息,可以为用户提供准确的地理位置服务以及相关搜索服务。目前,此类应用已经大行其道,比如手机地图APP。
6、跨语言搜索
如何将中文的用户查询翻译为英文查询,目前主流的方法有3种:机器翻译、双语词典查询和双语语料挖掘。对于一个全球性的搜索引擎来说,具备跨语言搜索功能是必然的发展趋势,而其基本的技术路线一般会采用查询翻译加上网页的机器翻译这两种技术手段。
7、多媒体搜索
目前,搜索引擎的查询还是基于文字的,即使是图片和视频搜索也是基于文本方式。那么未来的多媒体搜索技术则会弥补查询这一缺失。多媒体形式除了文字,主要包括图片、音频、视频。多媒体搜索比纯文本搜索要复杂许多,一般多媒体搜索包含4个主要步骤:多媒体特征提取、多媒体数据流分割、多媒体数据分类和多媒体数据搜索引擎。
8、情境搜索
情境搜索是融合了多项技术的产品,上面介绍的社会化搜索、个性化搜索、地点感知搜索等都是支持情境搜索的,目前Google在大力提倡这一概念。所谓情境搜索,就是能够感知人与人所处的环境,针对“此时此地此人”来建立模型,试图理解用户查询的目的,根本目标还是要理解人的信息需求。比如某个用户在苹果专卖店附近发出“苹果”这个搜索请求,基于地点感知及用户的个性化模型,搜索引擎就有可能认为这个查询是针对苹果公司的产品,而非对水果的需求。
常见全文搜索引擎框架
主要介绍13款现有的开源搜索引擎,你可以将它们用在你的项目中以实现检索功能。
原文:https://www.open-open.com/lib/view/open1433383682182.html
Lucene
Lucene的开发语言是Java,也是Java家族中最为出名的一个开源搜索引擎,在Java世界中已经是标准的全文检索程序,它提供了完整的查询引擎和索引引擎,没有中文分词引擎,需要自己去实现,因此用Lucene去做一个搜素引擎需要自己去架构.另外它不支持实时搜索,但linkedin和 推ter有分别对Lucene改进的实时搜素. 其中Lucene有一个C++移植版本叫CLucene,CLucene因为使用C++编写,所以理论上要比lucene快.
官方主页:http://lucene.apache.org/
Lucene官方主页:http://sourceforge.net/projects/clucene/
Sphinx
Sphinx是一个用C++语言写的开源搜索引擎,也是现在比较主流的搜索引擎之一,在建立索引的事件方面比Lucene快50%,但是索引文件比 Lucene要大一倍,因此Sphinx在索引的建立方面是空间换取事件的策略,在检索速度上,和lucene相差不大,但检索精准度方面Lucene要优于Sphinx,另外在加入中文分词引擎难度方面,Lucene要优于Sphinx.其中Sphinx支持实时搜索,使用起来比较简单方便.
官方主页:http://sphinxsearch.com/about/sphinx/
Xapian
Xapian是一个用C++编写的全文检索程序,它的api和检索原理和lucene在很多方面都很相似,算是填补了lucene在C++中的一个空缺.
官方主页:http://xapian.org/
Nutch
Nutch是一个用java实现的开源的web搜索引擎,包括爬虫crawler,索引引擎,查询引擎. 其中Nutch是基于Lucene的,Lucene为Nutch提供了文本索引和搜索的API.
对于应该使用Lucene还是使用Nutch,应该是如果你不需要抓取数据的话,应该使用Lucene,最常见的应用是:你有数据源,需要为这些数据提供一个搜索页面,在这种情况下,最好的方式是直接从数据库中取出数据,并用Lucene API建立索引.
官方主页:http://nutch.apache.org/
DataparkSearch
DataparkSearch是一个用C语言实现的开源的搜索引擎. 其中网页排序是采用神经网络模型. 其中支持HTTP,HTTPS,FTP,NNTP等下载网页.包括索引引擎,检索引擎和中文分词引擎(这个也是唯一的一个开源的搜索引擎里有中文分词引擎).能个性化定制搜索结果,拥有完整的日志记录.
官方主页:http://www.dataparksearch.org/
Zettair
Zettair是根据Justin Zobel的研究成果为基础的全文检索实验系统.它是用C语言实现的. 其中Justin Zobel在全文检索领域很有名气,是业界第一个系统提出倒排序索引差分压缩算法的人,倒排列表的压缩大大提高了检索和加载的性能,同时空间膨胀率也缩小到相当优秀的水平. 由于Zettair是源于学术界,代码是由RMIT University的搜索引擎组织写的,因此它的代码简洁精炼,算法高效,是学习倒排索引经典算法的非常好的实例. 其中支持linux,windows,mac os等系统.
官方主页:http://www.seg.rmit.edu.au/zettair/about.html
Indri
Indri是一个用C语言和C++语言写的全文检索引擎系统,是由University of Massachusetts和Carnegie Mellon University合作推出的一个开源项目. 特点是跨平台,API接口支持Java,PHP,C++.
官方主页:http://www.lemurproject.org/indri/
Terrier
Terrier是由School of Computing Science,Universityof Glasgow用java开发的一个全文检索系统.
官方主页:http://terrier.org/
Galago
Galago是一个用java语言写的关于文本搜索的工具集. 其中包括索引引擎和查询引擎,还包括一个叫TupleFlow的分布式计算框架(和google的MapReduce很像).这个检索系统支持很多Indri查询语言.
官方主页:http://www.galagosearch.org/
Zebra
Zebra是一个用C语言实现的检索程序,特点是对大数据的支持,支持EMAIL,XML,MARC等格式的数据.
官方主页:https://www.indexdata.com/zebra
Solr
Solr是一个用java开发的独立的企业级搜索应用服务器,它提供了类似于Web-service的API接口,它是基于Lucene的全文检索服务器,也算是Lucene的一个变种,很多一线互联网公司都在使用Solr,也算是一种成熟的解决方案.
官方主页:http://lucene.apache.org/solr/
Elasticsearch
Elasticsearch是一个采用java语言开发的,基于Lucene构造的开源,分布式的搜索引擎. 设计用于云计算中,能够达到实时搜索,稳定可靠. Elasticsearch的数据模型是JSON.
官方主页:http://www.elasticsearch.org/
Whoosh
Whoosh是一个用纯python写的开源搜索引擎.
官方主页:https://bitbucket.org/mchaput/whoosh/wiki/Home
选择
Lucene
Lucene的开发语言是Java,也是Java家族中最为出名的一个开源搜索引擎,在Java世界中已经是标准的全文检索程序,它提供了完整的查询引擎和索引引擎,没有中文分词引擎,需要自己去实现,因此用Lucene去做一个搜素引擎需要自己去架构,另外它不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装。
1.2 优点
成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索。
1.3 缺点
需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善.
Apache Solr
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
2.2 优点
(1)Solr有一个更大、更成熟的用户、开发和贡献者社区。
(2)支持添加多种格式的索引,如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等纯文本格式。
(3)Solr比较成熟、稳定。
(4)不考虑建索引的同时进行搜索,速度更快。
2.3 缺点
建立索引时,搜索效率下降,实时索引搜索效率不高
ElasticSearch
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。支持通过HTTP使用JSON进行数据索引。
3.2 优点
(1)Elasticsearch是分布式的。不需要其他组件,分发是实时的,被叫做”Push replication”。
(2)Elasticsearch 完全支持 Apache Lucene 的接近实时的搜索。
(3)处理多租户(multitenancy)不需要特殊配置,而Solr则需要更多的高级设置。
(4)Elasticsearch 采用 Gateway 的概念,使得完备份更加简单。
各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作。
3.3 缺点
还不够自动(不适合当前新的Index Warmup API)索引预热API
究竟选哪一个呢?
ES or Solr
这里有篇文章做了很详细的比对:https://www.cnblogs.com/jajian/p/9801154.html
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社区和开发者 | Apache 软件基金和社区支持 | 单一商业实体及其员工 |
| 节点发现 | Apache Zookeeper,在大量项目中成熟且经过实战测试 | Zen内置于Elasticsearch本身,需要专用的主节点才能进行分裂脑保护 |
| 碎片放置 | 本质上是静态,需要手动工作来迁移分片,从Solr 7开始 - Autoscaling API允许一些动态操作 | 动态,可以根据群集状态按需移动分片 |
| 高速缓存 | 全局,每个段更改无效 | 每段,更适合动态更改数据 |
| 分析引擎性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据放置 |
| 全文搜索功能 | 基于Lucene的语言分析,多建议,拼写检查,丰富的高亮显示支持 | 基于Lucene的语言分析,单一建议API实现,高亮显示重新计算 |
| DevOps支持 | 尚未完全,但即将到来 | 非常好的API |
| 非平面数据处理 | 嵌套文档和父-子支持 | 嵌套和对象类型的自然支持允许几乎无限的嵌套和父-子支持 |
| 查询DSL | JSON(有限),XML(有限)或URL参数 | JSON |
| 索引/收集领导控制 | 领导者安置控制和领导者重新平衡甚至可以节点上的负载 | 不可能 |
| 机器学习 | 内置 - 在流聚合之上,专注于逻辑回归和学习排名贡献模块 | 商业功能,专注于异常和异常值以及时间序列数据 |
流行程度来看
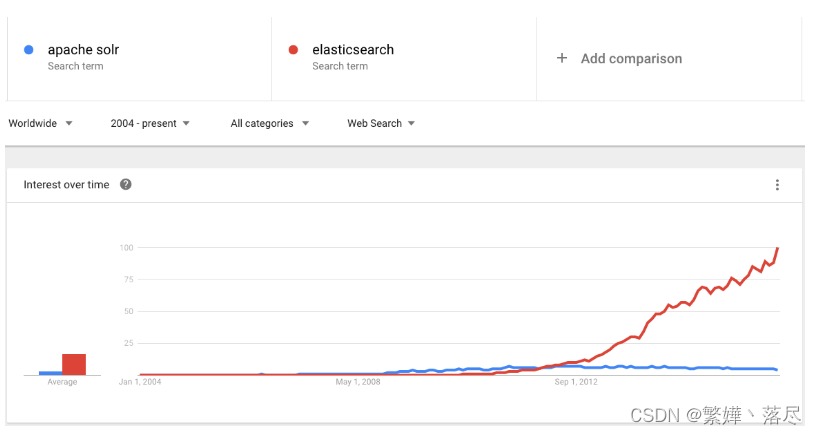
根据上面综合分析,最终选择:Elasticsearch
Elasticsearch
概念
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
1>基于Apache Lucene 构建的开源搜索引擎
2>采用java编写的,提供简单易用的RESTFul API
3>轻松的横向拓展, 可以支持PB级的结构化或非结构化数据处理
在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
定位
狭义的上的理解:
专注于 搜索 的 非关系型 数据库
类似于mongodb
应用场景
多条件搜索,站内搜索,地理位置搜索,ELK
Elasticsearch安装
对Elasticsearch有了大体之后,我们看下如何实现Elasticsearch的安装。
安装相关文件下载路径:https://elasticsearch.cn/download/
本教程使用的Elasticsearch 是 7.10.2
服务端
安装
步骤1:下载Elasticsearch安装包
下载Elasticsearch版本:elasticsearch-7.10.2-windows-x86_64.zip
步骤2:检查Elasticsearch安装环境
Elasticsearch是使用Java编写的解压即用的软件,安装是需要有Java的运行环境即可。
检查是否配置了java环境:
打开cmd命令框,输入: set java_home
步骤3:启动Elasticsearch程序
环境检查后,把压缩包解压后,进入到bin目录运行elasticsearch.bat
步骤4:输入地址,检查
浏览器输入:http://localhost:9200,看到浏览器输出服务器的信息,表示安装成功,可以使用了
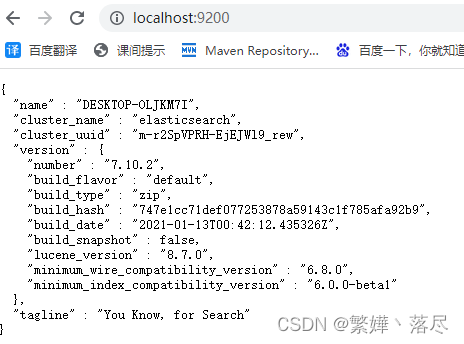
版本说明
Elasticsearch 目前拥有的版本:1.x 2.x 5.x 6.x 7.x 8.x
留意看,发现没有3.x 4.x 这是为何??
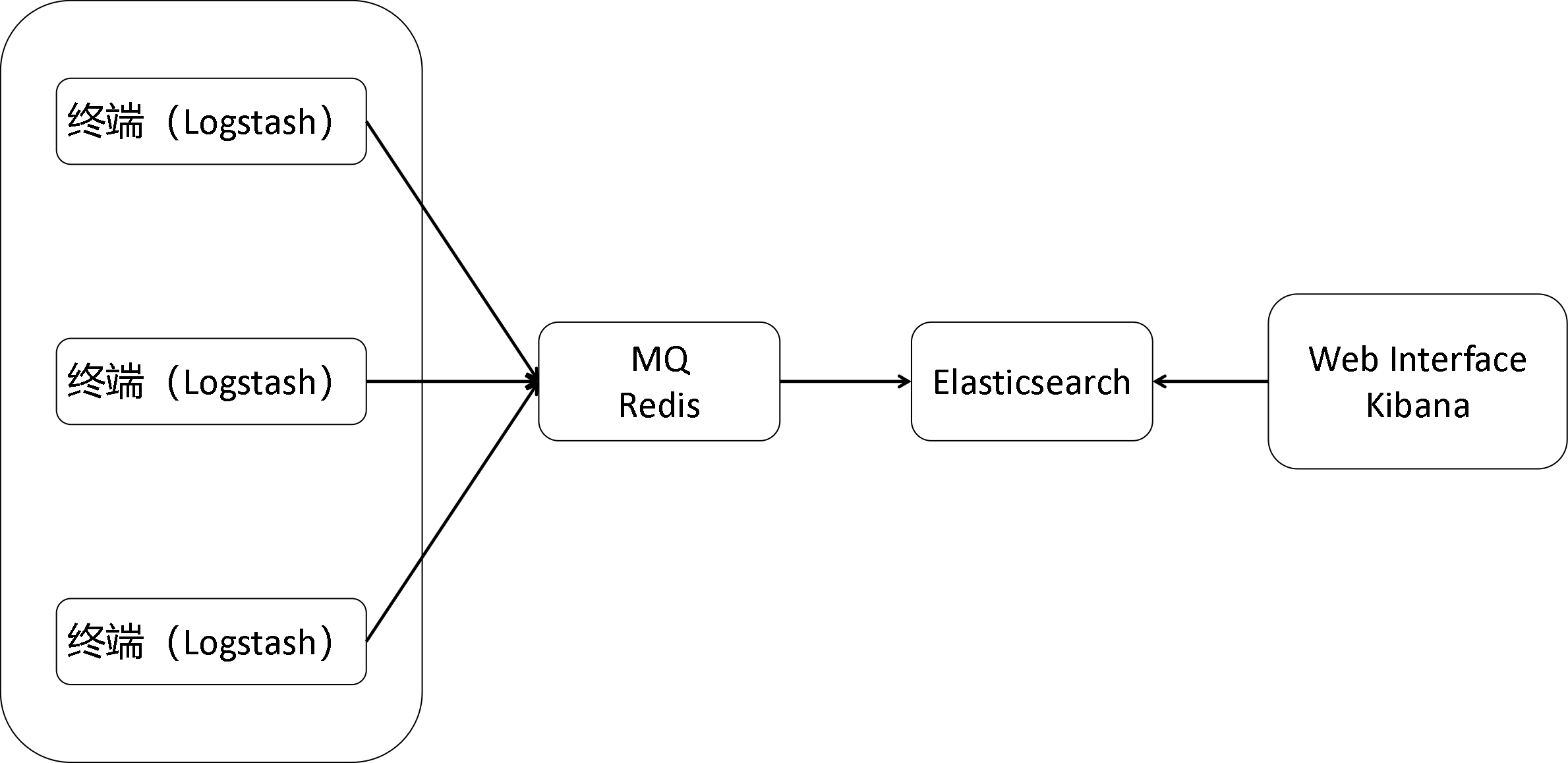
原因:ELK技术组合
ELK是官方主导的一个非常好用的日志监控技术组合,有点类似SSM组合。其中
E -->Elasticsearch是一个高度可扩展的全文搜索和分析引擎,基于Apache Lucence(事实上,Lucence也是百度所采用的搜索引擎)构建,能够对大容量的数据进行接近实时的存储、搜索和分析操作。
L —>Logstash是一个数据收集引擎,它可以动态的从各种数据源搜集数据,并对数据进行过滤、分析和统一格式等操作,并将输出结果存储到指定位置上。Logstash支持普通的日志文件和自定义Json格式的日志解析。
K—>Kibana是一个数据分析和可视化平台,通常与Elasticsearch配合使用,用于对其中的数据进行搜索、分析,并且以统计图标的形式展示。
它们工作流程:
总结:ELK技术组合时,要求版本必须一致,否则报错, 当初Elasticsearch跟上面lk组合时,版本才到2.x,后续同一个升级,从5.x开始。
客户端
本教程使用的客户端有两个: 1>Elasticsearch-head插件 2>kibana
为啥用2个?
原因:
Elasticsearch-head插件 查看Elasticsearch数据非常方便,直接上手,kibana 查看数据相对麻烦
Elasticsearch-head插件 操作Elasticsearch命令非常不友好,跟记事本一样,没有任何代码提示与高亮显示,但是kibana有
综合起来:使用Elasticsearch-head插件 的数据查询 + kibana 命令操作
Elasticsearch-head插件
Elasticsearch-head插件 是一个chrome浏览器插件,直接安装离线插件即可

显式效果

kibana
kibana是一个大的组件,安装需要满足几个条件
1>安装路径必须是英文(非中文)
2>安装路径不允许有空格
kibana是一个绿色软件,解压即可,启动时,执行bin/kibana.bat即可
注意:启动kibana前,先启动Elasticsearch
启动成功之后访问路径: http://localhost:5601
IK分词器
当前暂时还没有用到IK分词器,后面讲全文搜索时,才会涉及到分词器的逻辑,这里是顺手装上而已。
将分词安装包复制到Elasticsearch安装目录的plugins文件夹

注意: ik分词器安装完成之后,必须重启Elastsearch才能生效。
Elasticsearch核心概念
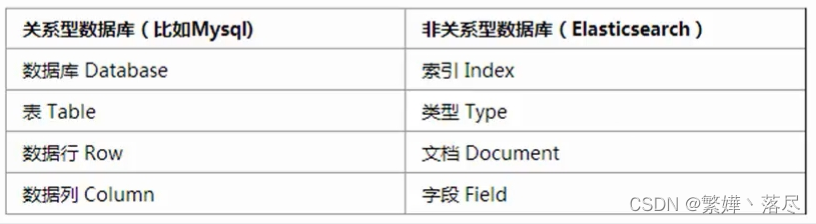
注意:Elasticsearch约定一个索引只能有一个类型type,并且类型名固定为(_doc)
索引操作
添加
无参数构造方式
语法
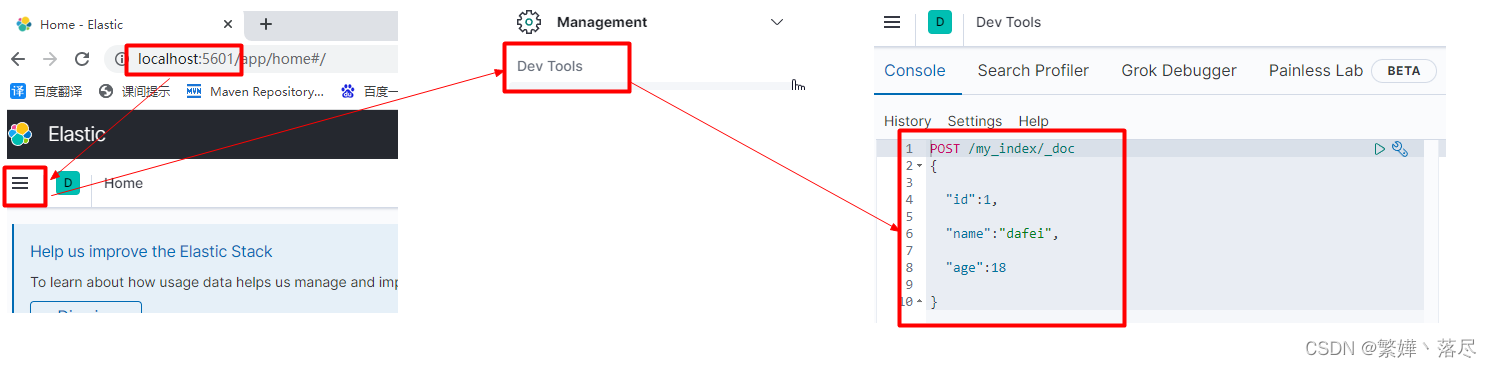
PUT my_index
练习
#需求:创建名为my_index的索引
PUT my_index
带类型type构造方式
语法
PUT /索引名
{
"mappings": {
"properties": {
字段名: {
"type": 字段类型,
"analyzer": 分词器类型,
"search_analyzer": 分词器类型,
...
},
...
}
}
}
练习
#需求:创建名为my_index的索引
PUT /my_index
{
"mappings": {
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
}
}
}
}
注意:
1:索引不能有大写字母
2:参数格式必须是标准的json格式
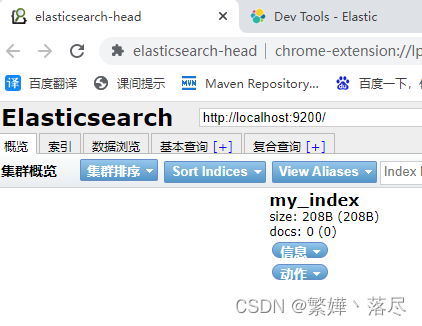
查看
命令
#看单个
GET /索引名
#看所有
GET _cat/indices
es-head
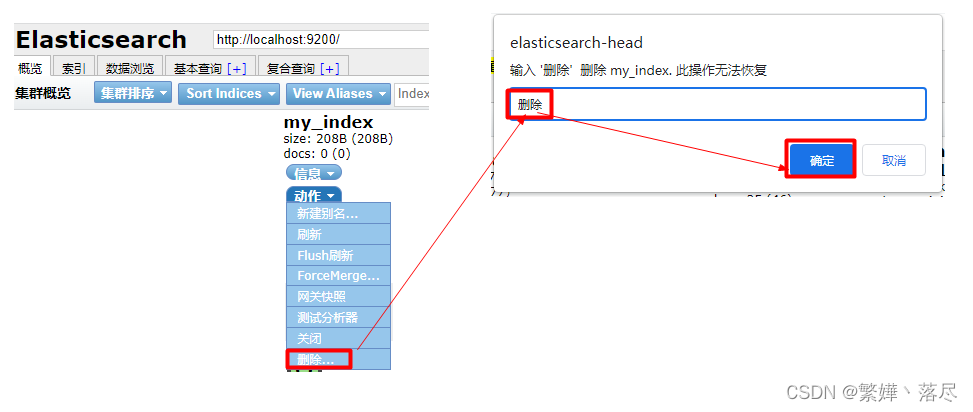
删除
命令
#语法:DELETE /索引名
DELETE /my_index
es-head
数据类型
Elasticsearch 是使用 Java 开发出来的,所以它很多类型给 Java 是一样的,比如:
byte short integer double float date boolean binary array object ip
这里有个比较特殊的类型: String, Elasticsearch 中 String 类型有种存在方式:
text 类型:当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
keyword 类型:适用于索引结构化的字段,比如 email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。
后续使用 Elasticsearch 做全文搜索时,要求条件列必须是:text类型。
文档操作
添加
语法1-指定ID
PUT /索引名/_doc/文档ID
{
field1: value1,
field2: value2,
...
}
语法2-不指定ID
POST /索引名/_doc
{
field1: value1,
field2: value2,
...
}
注意:
不指定指定id默认使用随机字符串,同时语法必须使用POST方式
当索引/映射不存在时,会使用默认设置自动添加
ES中的数据一般是从别的数据库导入的,所以文档的ID会沿用原数据库中的ID
操作时,如果指定文档id, 并且索引库中已经存在, 则执行更新操作, 否则执行添加
练习
#需求1:新增一个文档
PUT /my_index/_doc/1
{
"id":1,
"name":"dafei",
"age":18
}
结果字段解释:
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
| 字段 | 解释 |
|---|---|
| _index | 所属索引 |
| _type | 所属类型 |
| _id | 文档ID |
| _version | 乐观锁版本号 |
| _source | 数据内容 |
| result | 命令操作类型 |
| _shards | 分片相关信息 |
更新
语法1-全量更新
PUT /索引名/_doc/文档ID
{
field1: value1,
field2: value2,
...
}
练习
#需求2:替换一个文档
PUT /my_index/_doc/1
{
"id":1,
"name":"xiaofei",
"age":18
}
{
"_index" : "my_index",
"_type" : "users",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
全量更新,就是所有字段更新,必须明确指定每一个字段的value值,否则update之后,数据会丢失。
执行前:

PUT /my_index/_doc/1
{
"name":"xiaofei",
}
执行后,

语法2-部分更新
POST /索引名/_update/文档id
{
"doc":{
"要改动字段":"值"
}
}
练习
#只改名称
POST /my_index/_update/1/
{
"doc":{
"name":"xiaofei"
}
}
查询
语法
#查单个
GET /索引名/_doc/文档ID
#查所有
GET /索引名/_doc/_search
练习
#查单个
GET /my_index/_doc/1
#查所有
GET /my_index/_search
查单个
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 1,
"name" : "xiaofei",
"age" : 18
}
}
查所有
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "xiaofei",
"age" : 18
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "dafei",
"age" : 18
}
}
]
}
}
结果字段解释:
| 字段 | 解释 |
|---|---|
| took | 耗时 |
| _shards.total | 分片总数 |
| hits.total | 查询到的数量 |
| hits.max_score | 最大匹配度 |
| hits.hits | 查询到的结果 |
| hits.hits._score | 匹配度 |
删除
语法
DELETE /索引名/_doc/文档ID
练习
#需求1:根据文档ID删除一个文档
DELETE /my_index/_doc/1
#需求2:又添加刚刚删除的文档
PUT /my_index/_doc/1
{
"id":1,
"name":"dafei",
"age":18
}
注意:这里的删除并且不是真正意义上的删除,仅仅是清空文档内容而已,并且标记该文档的状态为删除
全文搜索
接下来就是做全文搜索啦,搜索前先进行数据初始化。
数据准备
PUT /product
{
"mappings": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"price": {"type": "integer"},
"intro": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"brand": {
"type": "keyword"
}
}
}
}
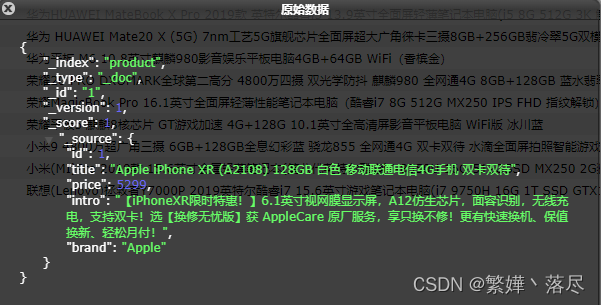
POST /product/_bulk
{"create":{"_id": 1}}
{"id":1,"title":"Apple iPhone XR (A2108) 128GB 白色 移动联通电信4G手机 双卡双待","price":5299,"intro":"【iPhoneXR限时特惠!】6.1英寸视网膜显示屏,A12仿生芯片,面容识别,无线充电,支持双卡!选【换修无忧版】获 AppleCare 原厂服务,享只换不修!更有快速换机、保值换新、轻松月付!","brand":"Apple"}
{"create":{"_id": 2}}
{"id":2,"title":"Apple 2019款 Macbook Pro 13.3【带触控栏】八代i7 18G 256G RP645显卡 深空灰 苹果笔记本电脑 轻薄本 MUHN2CH/A","price":15299,"intro":"【八月精选】Pro2019年新品上市送三重好礼,现在购买领满8000减400元优惠神劵,劵后更优惠!","brand":"Apple"}
{"create":{"_id": 3}}
{"id":3,"title":"Apple iPad Air 3 2019年新款平板电脑 10.5英寸(64G WLAN版/A12芯片/Retina显示屏/MUUL2CH/A)金色","price":3788,"intro":"8月尊享好礼!买iPad即送蓝牙耳机!领券立减!多款产品支持手写笔!【新一代iPad,总有一款适合你】选【换修无忧版】获 AppleCare 原厂服务,享只换不修!更有快速换机、保值换新、轻松月付!","brand":"Apple"}
{"create":{"_id": 4}}
{"id":4,"title":"华为HUAWEI MateBook X Pro 2019款 英特尔酷睿i5 13.9英寸全面屏轻薄笔记本电脑(i5 8G 512G 3K 触控) 灰","price":7999,"intro":"3K全面屏开启无界视野;轻薄设计灵动有型,HuaweiShare一碰传","brand":"华为"}
{"create":{"_id": 5}}
{"id":5,"title":"华为 HUAWEI Mate20 X (5G) 7nm工艺5G旗舰芯片全面屏超大广角徕卡三摄8GB+256GB翡冷翠5G双模全网通手机","price":6199,"intro":"【5G双模,支持SA/NSA网络,7.2英寸全景巨屏,石墨烯液冷散热】5G先驱,极速体验。","brand":"华为"}
{"create":{"_id": 6}}
{"id":6,"title":"华为平板 M6 10.8英寸麒麟980影音娱乐平板电脑4GB+64GB WiFi(香槟金)","price":2299,"intro":"【华为暑期购】8月2日-4日,M5青春版指定爆款型号优惠100元,AI语音控制","brand":"华为"}
{"create":{"_id": 7}}
{"id":7,"title":"荣耀20 PRO DXOMARK全球第二高分 4800万四摄 双光学防抖 麒麟980 全网通4G 8GB+128GB 蓝水翡翠 拍照手机","price":3199,"intro":"白条6期免息!麒麟980,4800万全焦段AI四摄!荣耀20系列2699起,4800万超广角AI四摄!","brand":"荣耀"}
{"create":{"_id": 8}}
{"id":8,"title":"荣耀MagicBook Pro 16.1英寸全面屏轻薄性能笔记本电脑(酷睿i7 8G 512G MX250 IPS FHD 指纹解锁)冰河银","price":6199,"intro":"16.1英寸无界全面屏金属轻薄本,100%sRGB色域,全高清IPS防眩光护眼屏,14小时长续航,指纹一健开机登录,魔法一碰传高速传输。","brand":"荣耀"}
{"create":{"_id": 9}}
{"id":9,"title":"荣耀平板5 麒麟8核芯片 GT游戏加速 4G+128G 10.1英寸全高清屏影音平板电脑 WiFi版 冰川蓝","price":1549,"intro":"【爆款平板推荐】哈曼卡顿专业调音,10.1英寸全高清大屏,双喇叭立体环绕音,配置多重护眼,值得拥有!","brand":"荣耀"}
{"create":{"_id": 10}}
{"id":10,"title":"小米9 4800万超广角三摄 6GB+128GB全息幻彩蓝 骁龙855 全网通4G 双卡双待 水滴全面屏拍照智能游戏手机","price":2799,"intro":"限时优惠200,成交价2799!索尼4800万广角微距三摄,屏下指纹解锁!","brand":"小米"}
{"create":{"_id": 11}}
{"id":11,"title":"小米(MI)Pro 2019款 15.6英寸金属轻薄笔记本(第八代英特尔酷睿i7-8550U 16G 512GSSD MX250 2G独显) 深空灰","price":6899,"intro":"【PCIE固态硬盘、72%NTSC高色域全高清屏】B面康宁玻璃覆盖、16G双通道大内存、第八代酷睿I7处理器、专业级调校MX150","brand":"小米"}
{"create":{"_id": 12}}
{"id":12,"title":"联想(Lenovo)拯救者Y7000P 2019英特尔酷睿i7 15.6英寸游戏笔记本电脑(i7 9750H 16G 1T SSD GTX1660Ti 144Hz)","price":9299,"intro":"超大1T固态,升级双通道16G内存一步到位,GTX1660Ti电竞级独显,英特尔9代i7H高性能处理器,144Hz电竞屏窄边框!","brand":"联想"}
搜索语句
全文搜索依靠2个语句:match multi_match
语法1-match
GET /索引/_search
{
"query": {
"match": {field: value}
}
}
match 用于单字段全文检索,value值会被分词器拆分,然后去倒排索引中匹配
练习
#需求:查询商品标题中符合"游戏 手机"的字样的商品 【暂时理解为模糊查询】
GET /product/_search
{
"query": {
"match":{
"title": "游戏 手机"
}
}
}
语法2-multi_match
GET /索引/_search
{
"query": {
"multi_match": {
“query”:关键词语,
"fields":[xxxxm,xxx]
}
}
}
multi_match用于多字段全文检索,value值会被分词器拆分,然后去倒排索引中匹配
练习
#需求:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品
GET /product/_search
{
"query": {
"multi_match":{
"query":"蓝牙 指纹 双卡",
"fields": ["title", "intro"]
}
}
}
中文分词器
留意观察上面全文搜索结果,大家会发现,全文搜索出来效果并没有想象那么好,关键词基本是一个字一个字匹配,这是怎么一回事呢?那就涉及到Elasticsearch分词器概念了。
概念
Elasticsearch 在没有明确指定分词器规则时,会使用 默认的 standard 分词器对关键词语拆词并匹配。
默认分词器分词规则:按照单词切分,内容转变为小写,去掉标点,如果遇到中文,那就当成1个单词处理(一个字一个字拆分)
#默认分词器:
GET /product/_analyze
{
"text":"I am Groot"
}
GET /product/_analyze
{
"text":"英特尔酷睿i7处理器"
}
很明显,上面的分词无法满足中文的分词,那怎么办?使用第三方:ik 中文分词器
安装方式,在: Elasticsearch 安装章节讲过了,这里不重复了。
分词策略
IK分词器有2种分词策略,操作时必须明确指定。
1、ik_max_word 【细粒度分词】
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart 【粗粒度分词】
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
GET /product/_analyze
{
"text":"I am Groot",
"analyzer":"ik_smart"
}
GET /product/_analyze
{
"text":"英特尔酷睿i7处理器",
"analyzer":"ik_smart"
}
GET /product/_analyze
{
"text":"英特尔酷睿i7处理器",
"analyzer":"ik_max_word"
}
从效果上看,这分词就正常多了。
分词词库
分词完之后,不禁会想,IK分词怎么做到的将长句拆分成词语的?那输入是 淘宝 会不会被拆分,叩丁狼 会不会被拆分?
GET /product/_analyze
{
"text":"淘宝",
"analyzer":"ik_smart"
}
GET /product/_analyze
{
"text":"叩丁狼",
"analyzer":"ik_max_word"
}
答案很显然,淘宝不会被分, 叩丁狼会被分。为啥?因为ik分词器的词库中有淘宝,而没有叩丁狼
打开:config/main.dic
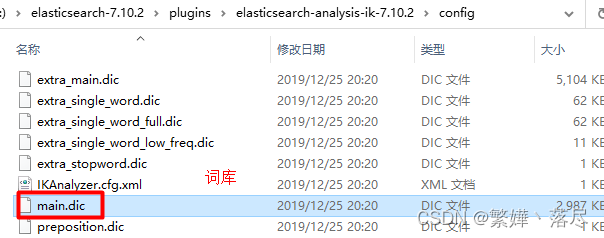

到这真相大白,只要词库维护好,IK自然好
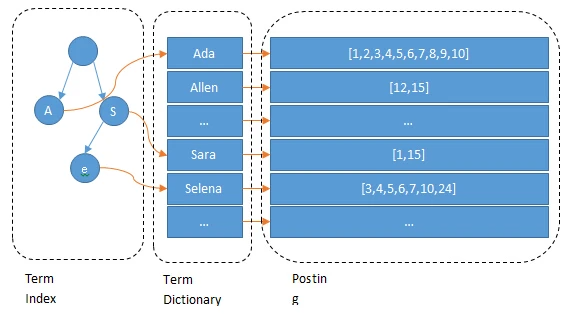
倒排索引
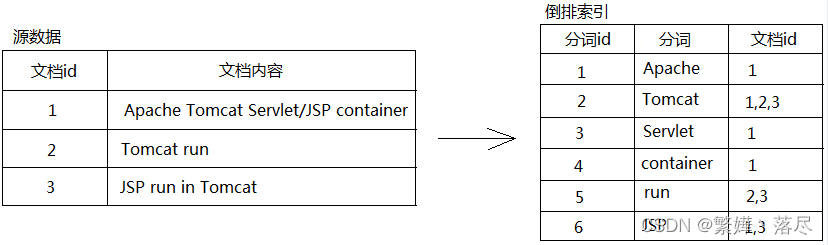
具体描述
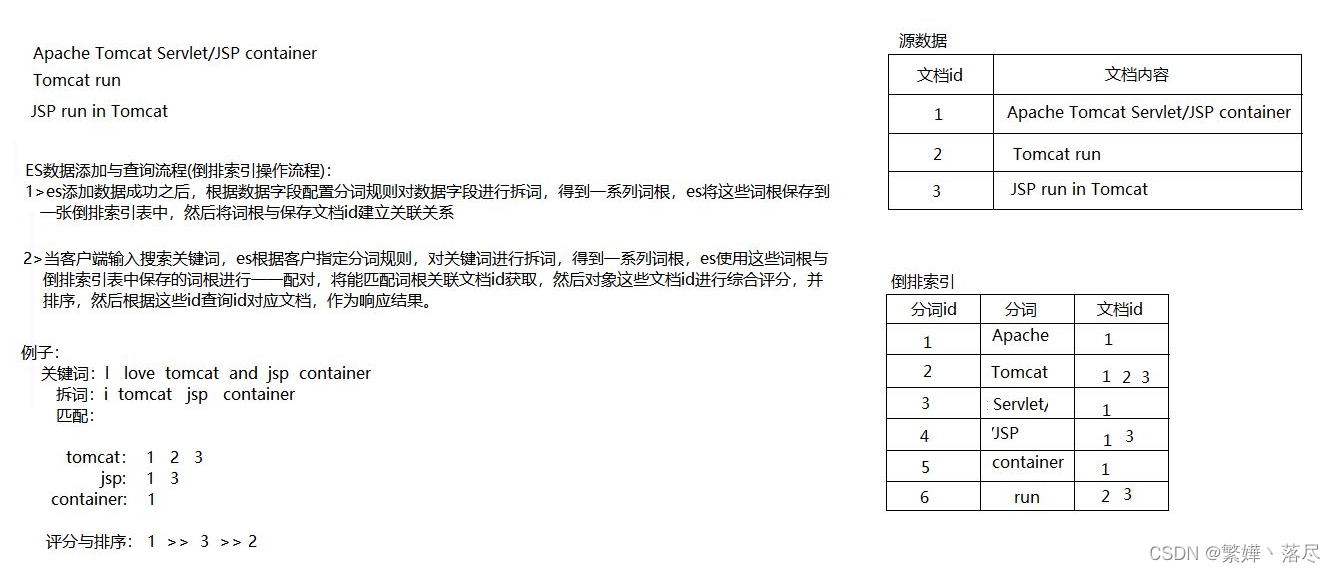
正排索引:先查询数据,然后赛选条件
倒排索引:先赛选条件,再查询数据
高亮显示
效果
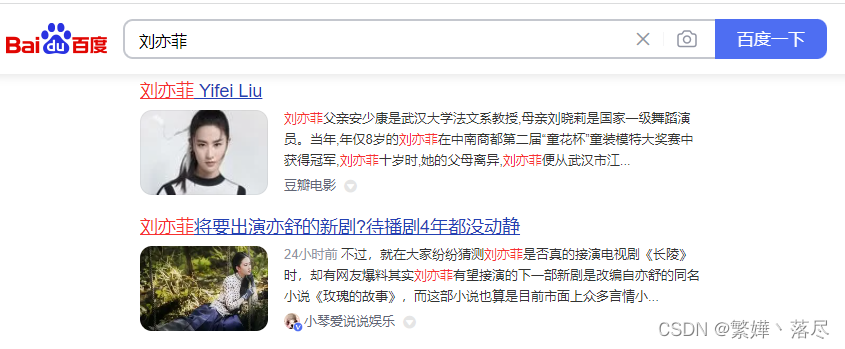
原理:所谓的高亮显示就是给全搜索匹配关键词加上高亮样式(加粗/改颜色)
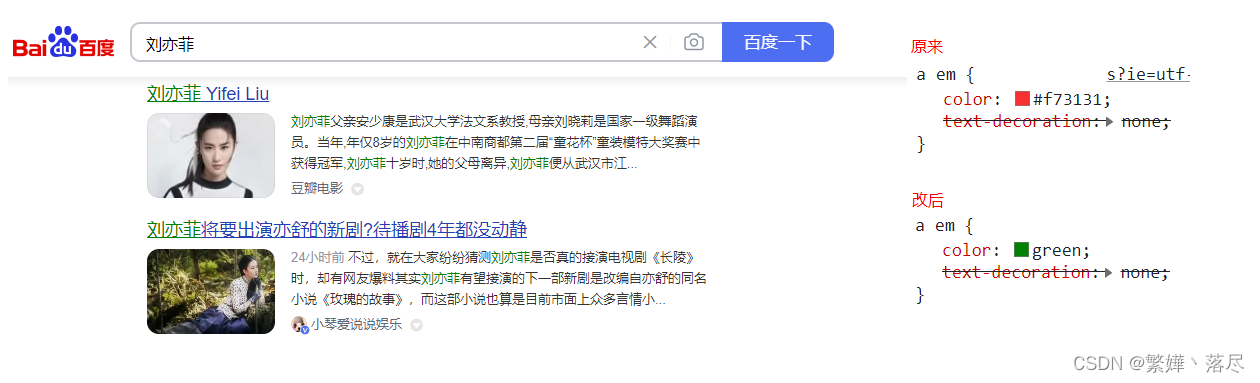
语法
GET /索引/_search
{
"query": { ... },
"highlight": {
"fields": {
"field1": {},
"field2": {},
...
},
"pre_tags": 开始标签,
"post_tags" 结束标签
}
}
highlight:表示高亮显示,需要在fields中配置哪些字段中检索到该内容需要高亮显示
必须配合 match/multi_match一起使用
练习
#需求:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品,并且高亮显示
GET /product/_search
{
"query": {
"multi_match":{
"query":"蓝牙 指纹 双卡",
"fields": ["title", "intro"],
"analyzer": "ik_smart"
}
},
"highlight": {
"fields": {
"title": {"type": "plain"},
"intro": {"type": "plain"}
},
"pre_tags": "<span style='color:red;'>",
"post_tags": "</span>"
}
}
Elasticsearch 编程
这里使用 SpringBoot data 的方式实现 Elasticsearch 编程操作
CRUD 操作
Elasticsearch 作为数据库,那肯定离不开 CRUD 的操作啦。
步骤1:创建标准的SpringBoot项目:es-demo
步骤2:导入相关依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.3</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
步骤3:配置ES
#application.properties
spring.elasticsearch.rest.uris=http://localhost:9200
步骤4:编写实体类
@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName="product")
public class Product {
@Id
private String id;
@Field(analyzer="ik_smart",searchAnalyzer="ik_smart",type = FieldType.Text)
private String title;
private Integer price;
@Field(analyzer="ik_smart",searchAnalyzer="ik_smart",type = FieldType.Text)
private String intro;
@Field(type=FieldType.Keyword)
private String brand;
}
步骤5:编写持久层代码
/**
* 1>自定义接口继承ElasticsearchRepository
* 2>明确指定2个泛型:
* 1:当前接口操作实体类: product
* 2:当前接口操作实体类主键类型:String
*
*/
public interface ProductRepository extends ElasticsearchRepository<Product, String>{
}
步骤6:编写Service接口与实现类
public interface IProductService {
void save(Product product);
void update(Product product);
void delete(String id);
Product get(String id);
List<Product> list();
}
@Service
public class ProductServiceImpl implements IProductService {
@Autowired
private ProductRepository repository;
@Autowired
private ElasticsearchRestTemplate template;
@Override
public void save(Product product) {
repository.save(product);
}
@Override
public void update(Product product) {
repository.save(product);
}
@Override
public void delete(String id) {
repository.deleteById(id);
}
@Override
public Product get(String id) {
return repository.findById(id).get();
}
@Override
public List<Product> list() {
Iterable<Product> all = repository.findAll();
List<Product> p = new ArrayList<>();
all.forEach(a->p.add(a));
return p;
}
}
步骤7:编写测试类
@SpringBootTest
public class ElasticsearchDemoApplicationTests {
@Autowired
private IProductService productService;
@Test
public void testSave() {
Product p = new Product();
p.setId("123")
p.setBrand("dafei");
p.setIntro("dafei手机");
p.setPrice(1000);
p.setTitle("全球最帅的手机");
productService.save(p);
}
@Test
public void testUpate() {
Product p = new Product();
p.setId("ue5r1m4BXlaPW5P0TegF");
p.setBrand("dafei");
p.setIntro("dafei手机");
p.setPrice(1000);
p.setTitle("全球最sb的手机");
productService.update(p);
}
@Test
public void testDelete() {
productService.delete("123");
}
@Test
public void testGet() {
System.out.println(productService.get("123"));
}
@Test
public void testList() {
System.err.println(productService.list());
}
}
全文搜索
步骤1:新建类:QueryTest
步骤2:编写2个全文搜索方法
// 查询商品标题中符合"游戏 手机"的字样的商品
@Test
public void testQuery4(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
/**
* {
* query:{
* match:{title:"游戏 手机"}
* }
* }
*/
builder.withQuery(
QueryBuilders.matchQuery("title", "游戏 手机")
);
builder.withPageable(PageRequest.of(0, 100));
Page<Product> search = repository.search(builder.build());
search.getContent().forEach(System.err::println);
}
// 查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品
@Test
public void testQuery7(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
/**
* {
* query:{
* multi_match:{
* "query":"蓝牙 指纹 双卡",
* "fields":["title", "intro"]
* }
* }
* }
*/
builder.withQuery(
QueryBuilders.multiMatchQuery("蓝牙 指纹 双卡", "title", "intro")
);
builder.withPageable(PageRequest.of(0, 100, Sort.Direction.DESC, "price"));
Page<Product> search = repository.search(builder.build());
search.getContent().forEach(System.err::println);
}
高亮显示[拓展]
@Test
public void testHighlight() throws Exception {
//定义索引库
SearchRequest searchRequest = new SearchRequest("product");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//定义query查询
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("蓝牙 指纹 双卡","title", "intro");
HighlightBuilder highlightBuilder = new HighlightBuilder(); // 生成高亮查询器
highlightBuilder.field("title");// 高亮查询字段
highlightBuilder.field("intro");// 高亮查询字段
highlightBuilder.requireFieldMatch(false); // 如果要多个字段高亮,这项要为false
highlightBuilder.preTags("<span style='color:red'>"); // 高亮设置
highlightBuilder.postTags("</span>");
highlightBuilder.fragmentSize(800000); // 最大高亮分片数
highlightBuilder.numOfFragments(0); // 从第一个分片获取高亮片段
Pageable pageable = PageRequest.of(0, 2); // 设置分页参数
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder) // match查询
.withPageable(pageable).withHighlightBuilder(highlightBuilder) // 设置高亮
.build();
SearchHits<Product> searchHits = template.search(searchQuery, Product.class);
List<Product> list = new ArrayList();
for (SearchHit<Product> searchHit : searchHits) { // 获取搜索到的数据
Product content = searchHit.getContent();
// 处理高亮
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
for (Map.Entry<String, List<String>> stringHighlightFieldEntry : highlightFields.entrySet()) {
String key = stringHighlightFieldEntry.getKey();
if (StringUtils.equals(key, "title")) {
List<String> fragments = stringHighlightFieldEntry.getValue();
StringBuilder sb = new StringBuilder();
for (String fragment : fragments) {
sb.append(fragment.toString());
}
content.setTitle(sb.toString());
}
if (StringUtils.equals(key, "intro")) {
List<String> fragments = stringHighlightFieldEntry.getValue();
StringBuilder sb = new StringBuilder();
for (String fragment : fragments) {
sb.append(fragment.toString());
}
content.setIntro(sb.toString());
}
}
list.add(content);
}
Page page = new PageImpl(list, pageable, searchHits.getTotalHits());
list.forEach(System.out::println);
}