原文链接:https://arxiv.org/abs/1909.11942
提出契机
背景:随着BERT模型在多想自然语言处理任务中取得优异表现,很多研究人员开始探索什么样的预训练方法能够帮助模型学习到更好的表示。
该文提出的目的为了降低模型的训练时所占用的内存,提升模型的训练速度。对此提出了两种参数减少的技巧。针对嵌入层进行分解,跨层参数共享。同时为了提升模型针对句子级别的语义理解,作者将将原始BERT中的NSP任务替换为了SOP任务。
创新点:
嵌入层(Embedding-layer)参数矩阵分解:
原始的bert-base-uncase模型的词表长度为30522,默认的维度为768。总的嵌入矩阵参数量为30522 × \times × 768,为了降低模型中token嵌入层的参数量,作者进行了矩阵分解,将原始的嵌入层矩阵分解为30522 × \times × h和h × \times × 768两个矩阵,albert-base模型默认的 h = 128 h = 128 h=128。
跨层参数共享:
模型共享单层的BERT块,将输出的hidden-state在重新输入同样的BERT块中。albert-base默认使用一层的BERT块,重复循环计算12次。这样相当于参数比原本的base-base-uncase降低12倍。
SOP任务:
作者将NSP任务替换为了SOP(句子顺序预测)任务,具体操作方式为将一个长句子从中间截断后进行顺序颠倒,原始顺序的标签为1,颠倒后的句子标签为0。(作者认为NSP无效的主要原因是因为NSP任务训练的难度不如MLM,NSP将主题预测和连贯性预测合并为了一个任务(由于负例段落来自不同的文档,因此在主题和连贯性方面都与原始段落不匹配。)。而SOP任务的正负样例的句子都来自同一个文档,模型无法通过主题分析进行句子区分,迫使模型学习句子之前的连贯性)
模型训练
训练任务
MLM + SOP
训练细节
数据集: 遵循BERT (Devlin et al., 2019)的做法,使用BOOKCORPUS (Zhu et al., 2015)和英文维基百科 (Devlin et al., 2019)作为预训练基线模型的数据。这两个语料库包含大约16GB的未压缩文本。
输入格式为:
词表:数量30000,采用wordpiece进行分词。
掩码方式: n - g r a m n\text{-}gram n-gram掩码,每个 n - g r a m n\text{-}gram n-gram长度随机选择。选择n的概率为:
p ( n ) = 1 / n ∑ k = 1 N 1 / k p(n) = \frac{1/ n}{\sum_{k=1}^N 1 / k} p(n)=∑k=1N1/k1/n
n-gram \text{n-gram} n-gram的最大长度为3(即MLM目标可以包含最多3个完整单词的3gram,如”White House correspondents”)。
实验
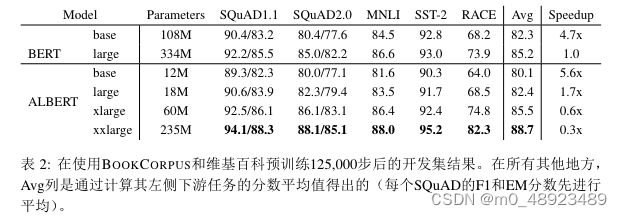
参 数 效 率 的 提 升 展 示 了ALBERT设 计 选 择 的 最 重 要 优 势, 如 表2所 示: 使 用 大 约70%的BERT-large参数,ALBERT-xxlarge在SQuAD v1.1(+1.9%)、SQuAD v2.0(+3.1%)、 MNLI(+1.4%)、SST-2(+2.2%)和RACE(+8.4%)等代表性下游任务的开发集得分上实 现了显著提升。
另一个有趣的观察是, 在相同的训练配置 (相同的TPU数量) 下, 训练时的数据吞吐量。 由于更少的通信和计算, ALBERT模型的数据吞吐量相比其对应的BERT模型更高。 如 果以BERT-large为基准, 我们发现ALBERT-large的数据迭代速度大约快1.7倍, 而ALBERTxxlarge因为更大的结构,速度大约慢3倍。
消融实验
FACTORIZED EMBEDDING PARAMETERIZATION
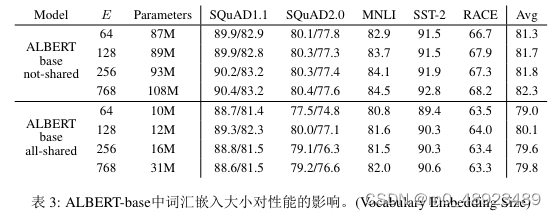
表3展示了在ALBERT基础配置(参见表1)下,改变词汇嵌入大小E的效果,使用同一组代 表性的下游任务。**在非共享条件(类似于BERT的设置)下,更大的嵌入尺寸能带来更好的性能,但提升并不显著。而在全共享条件(类似于ALBERT的设置)下,128维的嵌入似乎最为有效。**根据这些结果,我们在后续的所有设置中使用嵌入大小E = 128,这是进一步扩 展的必要步骤。
CROSS-LAYER PARAMETER SHARING
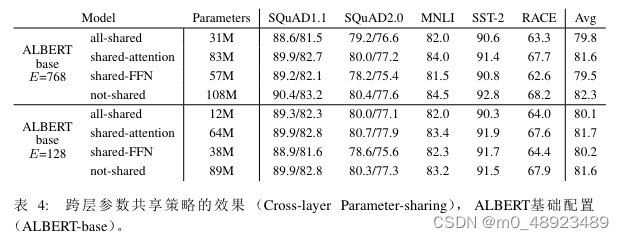
表 4 展示了不同层间参数共享策略的实验,使用了 ALBERT-base 配置(见表 1),两种嵌入大小 (E = 768 和 E = 128)。 我们比较了全共享策略(ALBERT 风格)、不共享策略(BERT 风格),以及仅共享注意力参数(不共享 FNN 参数)的中间策略,以及仅共享 FFN 参数(不共享注意力参数)的中间策略。全共享策略在两种情况下都会降低性能,但对 E = 128 的影响较小(平均下降1.5),而对 E = 768 的影响较大(平均下降2.5)。
此外,**大部分性能下降似乎源于共享 FFN 层参数,**而共享注意力参数时,当 E = 128 时没 有下降(平均增加0.1),当 E = 768 时略有下降(平均下降0.7)。
还有其他层间参数共享的方法,例如,可以将 L 层分为 N 个大小为 M 的组,每个大小为 M 的组共享参数。总的来说,我们的实验结果表明,组大小M越小,性能越好。然而,减 小组大小 M 也会显著增加总体参数量。我们选择全共享策略作为默认选项。
SENTENCE ORDER PREDICTION (SOP)
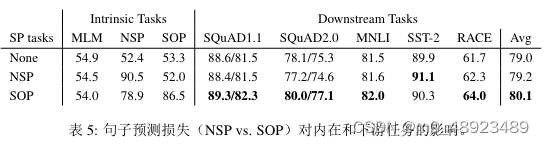
我们分别对比了三种额外的跨句损失实验设置:无(基于XLNet和RoBERTa的风格)、NSP (基于BERT的风格)和SOP(ALBERT的风格),使用ALBERT基础配置。实验结果见表5, 包括对内(MLM、NSP和SOP任务的准确性)和下游任务的表现。
句子对任务的结果表明,NSP损失并未为SOP任务带来区分力(准确率为52.0%,与”None”条 件下的随机猜测相当)。这表明NSP最终仅模型主题转换。相比之下,SOP损失在NSP任务 上的表现相对较好 (准确率为78.9%), 在SOP任务上更是如此 (准确率为86.5%)。 更为重要的是, SOP损失似乎持续提高了多句子编码任务的下游任务性能 (SQuAD1.1约+1%, SQuAD2.0约+2%,RACE约+1.7%),平均得分提高了约+1%。
总结
最后总结一下该篇论文得出的一些结论
1. 模型训练时采用多层参数共享能够显著降低模型的总参数量,同时保持模型的良好性能。
2. 针对token-embedding层进行矩阵分别能够降低模型的总参数量,同时保持模型的性能
3. NSP任务无效的原因:将主题预测和连贯性预测合并为了一个任务,其中主题预测和MLM任务存在重叠性,导致NSP任务的学习难度降低。
4. SOP任务替换为NSP任务是有效的,通过实验证明NSP任务训练对SOP下游任务无效果,而反之却有效果,在其他的下游任务上也出现了提升。
5. 进行参数共享时,FFN层的参数共享模型下游任务小将效果明显。(大部分性能下降似乎源于共享 FFN 层参数)
6. 移除dropout进行预训练下游任务的效果出现上升(原文仅针对albert进行了消融实验)