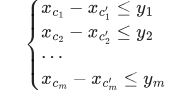要解决的问题:
1.之前based LLM的方法可能会忽视时间序列和自然语言的一致性,导致LLM潜力的利用不足
提出:
1.将LLM重新用作自回归时间序列预测器,他能够处理灵活的序列长度
2.提出token-wise prompting, 利用相应的时间戳使我们的方法适用于多模式场景
our approach establishes similar tokenization of
time series by the next token prediction, adopts the same au-
toregressive generation for inference, and freezes the blocks
of LLMs to fully reutilize the inherent token transition.
我们的方法通过下一个令牌预测建立了时间序列的类似令牌化,采用相同的自回归生成进行推理,并冻结LLM的块以充分利用固有的令牌转换。
优点:
1.继承了LLM的零值预测和上下文学习能力
2.表现出显著的方法通用性,并且可以通过更大的LLM,额外的文本或时间序列作为指令来实现增强的性能
方法Method:
时间序列编码:
补充:线性层和MLP
if configs.mlp_hidden_layers == 0:
if not configs.use_multi_gpu or (configs.use_multi_gpu and configs.local_rank == 0):
print("use linear as tokenizer and detokenizer")
self.encoder = nn.Linear(self.token_len, self.hidden_dim_of_llama)
self.decoder = nn.Linear(self.hidden_dim_of_llama, self.token_len)
else:
if not configs.use_multi_gpu or (configs.use_multi_gpu and configs.local_rank == 0):
print("use mlp as tokenizer and detokenizer")
self.encoder = MLP(self.token_len, self.hidden_dim_of_llama,
configs.mlp_hidden_dim, configs.mlp_hidden_layers,
configs.dropout, configs.mlp_activation)
self.decoder = MLP(self.hidden_dim_of_llama, self.token_len,
configs.mlp_hidden_dim, configs.mlp_hidden_layers,
configs.dropout, configs.mlp_activation)假设我们有一个简单的二维数据集,包含两个特征:X1 和 X2。我们想要使用线性变换和多层感知机来对这个数据集进行处理。
### 线性变换:
假设我们有一个线性变换模型,该模型由一个线性层组成,其形式为:
```
y = W * x + b
```
其中,W 是权重矩阵,b 是偏置向量,x 是输入特征向量,y 是输出特征向量。
在这个简单的例子中,我们的线性模型如下:
```
y = w1 * X1 + w2 * X2 + b
```
这个模型对应于一个二维平面上的一条直线,它可以捕捉到数据中的线性关系。例如,如果我们的数据集呈现出明显的线性关系,那么线性变换模型可以很好地拟合这个数据集。
### 多层感知机(MLP):
假设我们有一个包含一个隐藏层的多层感知机模型,该模型由多个全连接层和非线性激活函数组成。
```
h = activation(W1 * x + b1)
y = W2 * h + b2
```
其中,W1 和 W2 是权重矩阵,b1 和 b2 是偏置向量,activation 是非线性激活函数,x 是输入特征向量,h 是隐藏层输出特征向量,y 是最终输出特征向量。
在这个简单的例子中,我们的多层感知机模型如下:
```
h = tanh(w1 * X1 + w2 * X2 + b1)
y = w3 * h + b2
```
其中,tanh 是双曲正切激活函数。这个模型通过隐藏层中的非线性激活函数,可以学习到数据中更复杂的非线性关系。例如,如果我们的数据集不仅呈现出线性关系,还有一些非线性特征,那么多层感知机模型可以更好地拟合这个数据集。
### 总结:
- 线性变换适用于简单的线性数据,可以捕捉到数据中的线性关系。
- 多层感知机适用于处理更复杂的非线性数据,通过多个非线性激活函数可以学习到数据中更复杂的非线性特征。