开头说点题外话:这篇可谓是大咖云集啊,刘壮、谢赛宁、何凯明这些耳熟能详的名字,并且这篇论文一些人也觉得分析特别到位,不愧是大佬视角,配得上“解构”两个字;很巧的是,本科阶段的团队导师也是去噪方向的,但是跟大师兄去干目标检测了,因为当时觉得框框非常酷炫,而且大师兄的技术素养好像比导师更靠谱一点哈哈哈,哪知目标检测蛋糕越来越小,想要有好东西甚至水论文,都得涉及交叉领域,炼丹炉还时不时炸锅,丹一次比一次烂,深有感触啊(也有可能自己太菜了);废话不多说,开始论文盛宴!
论文地址:
https://arxiv.org/abs/2401.14404.pdf
摘要
在本研究中,作者们研究了最初用于图像生成的去噪扩散模型(DDM)的表示学习能力。作者们的理念是解构DDM,逐步将其转变为经典的去噪自动编码器(DAE)。
这种解构过程使作者们能够探索现代ddm的各个组成部分如何影响自监督表征学习。
作者们观察到,只有很少的现代模块对于学习良好的表示是至关重要的,而其他许多组件则是不必要的;作者们把多余的简化,化繁为简得出了一种高度简化的方法类似于经典的DAE。
引言
去噪是当前计算机视觉等领域生成模型发展趋势的核心,涉及到的算法通常被称为去噪扩散模型(Denoising Diffusion Models, DDM),例如学习一个去噪自动编码器(Denoising Autoencoder, DAE),大概原理是去除由扩散过程驱动的多级噪声(其实就是diffusion的单个阶段原理,加噪声然后再去噪,让模型学习学会生成图像);
对于高分辨率、逼真的图像有着效果出众的图像生成质量,这些生成墨香对于理解视觉内容似乎具有很强的识别表示(凯明大佬MIT第一课就说过,深度学习就是表征/表示学习)。
DAE与DDM的内容和区别
DAE虽然是生成模型的柱石,但是最初是为了以自监督的方式从数据中学习表示而提出的;最成功的DAE变体是基于“噪声掩膜(noise mask)”,比如预测文本缺失的BERT,预测图像缺失的MAE;这些变体与加噪声还是有很大区别:掩膜是明确了未知或已知的内容,但是去除人工加的噪声是没有清晰的信号可以用(可以理解为引导);所以这是DDM和DAEs的区别,DDM基于添加的噪声,可以在不明确标记未知/已知内容的情况下学习表示;
现在DDM模型百花齐放,一些数据结果都非常漂亮,但是这些模型都是为了生成设计的,不是为了识别,所以这些模型的表示能力是去噪过程获得的还是扩散过程获得的,这是一个疑问;
关于DDM到DAE的发现
所以作者们训练一个面向识别的模型,将DDM简化为DAE,以学习表示为目标,研究DDM的每个能想到的方面;
作者们发现关键模块是一个tokenizer(标记器),这个标记器创建一个低维潜在(latent)空间,后续由发现是这个空间让DAE更加优秀而不是标记器的其他细节构造;
作者们构建l-DAE时发现(大佬就是大佬,总是能发现东西),使用单级噪声也能让l-DAE表现不错,使用多级噪声类似于数据增强,可能有用但不是关键,所以作者们就认为:DDM的表示/表征能力是由去噪驱动过程获得的,而不是扩散。

l-DAE最终结果
- 高于基准算法(肯定是高的,毕竟是在基准上改)
- 低于对比学习的基准算法
- 高于基于掩膜的方法
相关工作
图像生成的方法概念上是无/自监督学习的形式,模型在没有标记数据的情况下进行训练,学习捕获输入数据的底层分布;
人们认为生成高质量的图像表面这个模型具有学习良好表示的能力,例如生成式对抗网络GAN、变分自编码器VAEs、上下文编码器、掩膜自编码器MAE等;作者们注意到,虽然DDM的生成能力表现出对图像的理解,但是不一定转化成对下游任务有用的表示;DAE基准表现的不好导致很少有关于加高斯噪声的经典DAE的工作出现;
去噪模型的背景
(这边的内容很适合不太了解去噪扩散领域的研究者,点赞)
扩散过程要用干净的数据,依次添加噪声,噪声随着时间步长变化而变化;
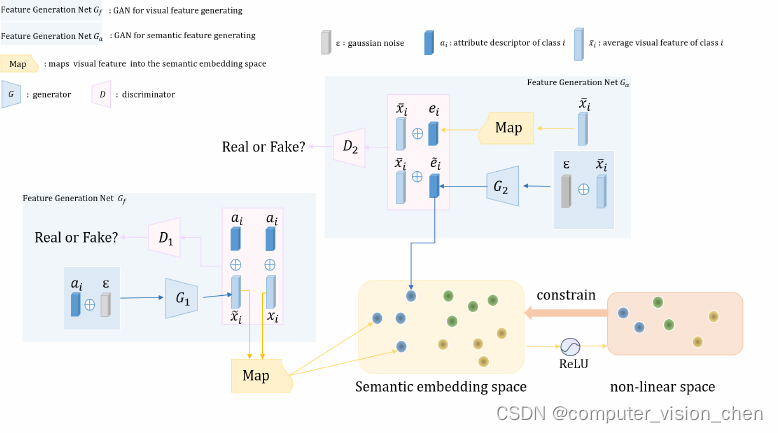
利用一个公式进行损失计算,对网络进行多个噪声级别的训练,一直迭代训练,直到得到干净的数据;DDM可以由两种选择,一种是原始图像作为干净数据,一种是在标记其生成的潜在空间上构建DDM,在图2b的情况下,标记器通常是一个预训练好的自编码器,如VQVAE;
(这边原论文是一大堆公式符号讲解,做笔记较困难,建议有兴趣的小伙伴看原文)。

扩散transformer(DIT)
作者们使用这个进行研究,出自以下原因:
- 基于transformer的DDM与其他基于unet的不同;
- 基于transformer的架构可以与更多的工作进行效果对比;
- DiT在编码器和解码器之间有更清晰的区分,而UNet的编码器和解码器通过跳跃连接,在评估编码器时可能需要额外的网络手术(也就是说需要自己额外加结构,增加了手工难度以及不确定性);
- DiT的训练速度比其他基于unet的DDMs快得多;
最终使用DiT-Large (DiT-L)作为DDM的基准,解码器和编码器涉及到的block一共24个,和ViT-L一样多;编码器是12个block,所以作者成为1/2L;
标记器Tokenizer
使用VQGAN标记器,256×256×3输入图像转换为32×32×4潜在图(latent map),其步长为8.
初始基准
在ImageNet上训练模型400epochs,分辨率为256×256像素;使用其1/2L编码器的线性探头精度为57.5%;该DiT-L型号的生成质量(FID-50K)为11.6。
解构去噪扩散模型
解构部分分为三个阶段,首先将DiT更倾向于自我监督学习,尽可能将DDM的很多设计简化成经典的DAE;
自监督学习的DDM重新定位
移除类条件反射:DDM通常在类标签上进行训练,很大程度上提高生成质量,但在自监督学习中是不合理的,所以在基准中删除类约束( class-conditioning);线性探针精度从57.5%大幅提高到62.1%,生成质量下降很多(FID从11.6到34.2),作者猜测移除类条件可以迫使模型学习更多的语义;
解构VQGAN:原标记器会使用多个损失,如自动动编码重建损失、KL-散度正则化损失、基于经过ImageNet分类训练的有监督VGG网的感知损失、带有鉴别器的对抗性损失;作者在表一删除后两个;感知损失是有监督的预训练,与现在的方案不合理,删除,线性探测精度从62.5%显著降低到58.4%;消除对抗性损失的VQGAN标记器,将线性探测精度从58.4%略微提高到59.0%(表1);至此,标记器本质上变成了VAE,并且,消除了任何一种损失都会影响生成质量;

替换噪声时间表:在生成任务中,目标是逐步将噪声图转化为图像。因此,原始噪声调度在噪声非常大的图像上花费了很多时间步(图3);作者的目标不是生成,所以使用了更简单的噪声线性衰减方法,极大地提高了线性探头精度,从59.0%提高到63.4%,生成能力进一步减少至FID=93.2

作者们总结,自监督学习的效果和其生成质量无关,DDM的表示能力和生成能力并不对标;
解构标记器(Tokenizer)
比较四种VAE标记器,每一种是前一种的简化;
卷积VAE:该VAE的编码器f和解码器g是深度卷积(conv)神经网络;

补丁VAE:其中VAE编码器和解码器都是线性投影,并且VAE输入x是一个patch,将补丁(patch)大小设置为16×16像素;

补丁AE:在VAE的基础上去掉正则化,编码器和解码器都是线性投影;

基于补丁的PCA:在patch空间上执行主成分分析(PCA),可以简单地在大量随机采样的patch上通过特征分解来计算,不需要基于梯度的训练,可以通过公式证明和AE相似;


作者还通过“每个标记”的潜在维度我们得出以下结论:
标记器的潜在维数是DDM在自监督学习中发挥作用的关键:标记器的所有四种变体都表现出类似的趋势,Conv VAE效果最差;KL正则化项是不必要的,因为AE和PCA变体表现不错;PCA标记器的表现效果出乎意料,并且作者们称这个是将DDM演变成经典DAE的关键;

高分辨率、基于像素的DDM不如自监督学习:使用一个“naıve标记器”对从调整大小的图像中提取的补丁进行映射,“token”是由patch的所有像素组成的平坦向量;当图像尺寸为256,patch尺寸为16 (d=768)时,线性探头精度急剧下降至23.6%;表明标记器和潜在空间对于DDM/DAE在自监督学习场景中很关键。(这边没看懂,有大佬看懂的指点一下迷津)

前往经典去噪自编码器
作者们删除当前基于PCA的DDM与经典DAE的有所差距的每个模块;在下表给出了结果,以下进行讨论;

- 预测干净的数据:目前的DDM通常预测噪声λ但经典DAE预测的是干净数据,在预测干净数据(而不是噪声)的修正下,线性探针精度从65.1%下降到62.4%,虽然数值下降,但是作者们想要将模型趋向于DAE;(这边是由公式讲解的,太复杂,有兴趣的看原文);
- 移除输入缩放:DDMs中输入按γt的因子进行缩放,在经典DAE中并不常见。接下来,我们研究去除输入标度,即设γt≡1。γt是固定的,需要直接在σt上定义一个噪声调度,经验地将Eq.(3)中的权重设置为λt = 1/(1 + σ2 t),这再次强调了更干净的数据(更小的σt)。在确定γt≡1后,我们获得了63.6%的精度,这与变化的γt对应的62.4%相比是有利的;在作者的场景中不需要按γt缩放数据。(算法本质数学体现的淋漓尽致!respect);
- 用逆PCA对图像空间进行操作:作者们希望DAE可以直接在图像空间上工作,同时仍然具有良好的准确性,可以通过逆主成分分析(invPCA)来实现;通过主成分基(即V)将输入图像投影到隐空间中,在隐空间中加入噪声,并通过逆主成分基(VT)将噪声隐投影回图像空间,随后应用一个标准的ViT网络直接对图像进行操作,省略掉标记器模块。最终效果为准确率63.9%;表明用invPCA对图像空间进行处理可以获得与对潜在空间进行处理相似的结果。
- 预测原始图像:虽然逆PCA可以在图像空间中产生预测目标,但该目标不是原始图像,因为PCA对于任何降维都是有损编码器,直接预测原始图像是一种更自然的解决方案;简单来说是其输入是带有噪声的图像,在PCA潜空间中加入噪声,其预测是原始的干净图像,精度达到64.5%;
- 单一噪音水平:由噪声调度给出的多层次噪声是由DDM中的扩散过程驱动的特性,在经典DAE中没有必要。我们将噪声级σ固定为常数(p 1/3),与多级噪声对应(64.5%)相比下降了3%。使用多级噪声类似于DAE中的一种数据增强形式:它是有益的,但不是促成因素。这也意味着DDM的表示能力主要是通过去噪驱动过程获得的,而不是扩散驱动过程;作者们后续保留这一个多级噪声操作。
上面的一些操作都整合在图中,这个图真的朴素但是内容丰富。

分析与比较
作者们将l-DAE与MAE进行一系列对比:
可视化潜在噪声:l-DAE是DAE的一种形式,它学习去除附加到潜在空间中的噪声。利用逆主成分分析可以很容易地将潜在噪声可视化(下图左是干净图像,中是高斯噪声图像,右是PCA噪声图像)。与像素噪声不同,潜在噪声在很大程度上与图像的分辨率无关。采用基于patch的PCA作为标记器,潜在噪声的模式主要由patch大小决定;作者们认为它是使用补丁而不是像素来解析图像,类似于MAE,对patch进行掩膜而不是单个像素。

去噪结果:尽管存在较大的噪声,仍能产生合理的预测结果。尽管如此,可视化可以帮助我们更好地理解l-DAE如何学习良好的表示;增加到潜在空间的重噪声为模型解决一个具有挑战性的借口任务,基于局部一个或几个有噪声的斑块来预测内容是很重要的(即使对人类来说也是如此。(这一段没看懂,大概就是找补效果差,不得不说这样的说法都挺说服人接受的)

数据增强:所有模型都没有数据增强:只使用图像的中心作物:没有随机调整大小或颜色抖动;作者们进一步探索了最终l-DAE的温和数据增强(随机调整大小);表明l-DAE的表示学习能力在很大程度上独立于对数据增强的依赖,MAE也是相似的结果;

训练轮数:所有的实验都是基于400 epoch的训练。为了遵循MAE,研究了800和1600epoch的训练;

模型大小:所有的型号都是基于DiT-L的变体,其编码器和解码器都是“ViT- 1/2L”(ViT- l的一半深度);进一步训练不同大小的模型,编码器分别为ViT-B或ViT-L(解码器始终与编码器大小相同);从VIT-b缩放到VIT-l有10.6%的增益。在MAE中VIT-b缩放到VIT-l的增益为7.8%。

与以前的基线比较:作者们使用属于对比学习的MoCov3,基于掩膜的MAE,与l-DAE进行对比;与MAE相比,l-DAE表现良好,显示出1.4% (ViT-B)或0.8% (ViT-L)的退化,但是仍然比不上对比学习的MoCo;

总结
l-DAE在很大程度上类似于经典DAE,可以在自监督学习中表现得很有竞争力,关键原因是加有噪声的低维潜在空间。
论文总结后面还有篇幅非常多的实验细节,笔记上就不附带了;个人在扩散模型这边也是一窍不通,所以对于这篇论文的一些概念和想法还是一知半解,就当作知识扩展吧哈哈。
结尾小废话:对于论文其实我更喜欢引言和相关工作去介绍大佬视角的各论文特点,所以关于引言会非常多,论文的实验效果我反而不太关心(神仙打架凡人望一眼的资格都没有),毕竟读论文是站在巨人的肩膀上看远处嘛。另外,今天的笔记篇幅好像也挺长的,不过谁让这篇论文是众多大佬的剖析范例呢?很多想法和思考都值得仔细学习啊哈哈哈。






















![【算法每日一练]-图论(保姆级教程篇16 树的重心 树的直径)#树的直径 #会议 #医院设置](https://img-blog.csdnimg.cn/direct/63ea7169076a4a5c843e22285c4e1b2e.png)