本文首发于公众号:机器感知
Dataset Distillation、Motion Mamba、StyleGaussian、Block-wise LoRA
One Category One Prompt: Dataset Distillation using Diffusion Models
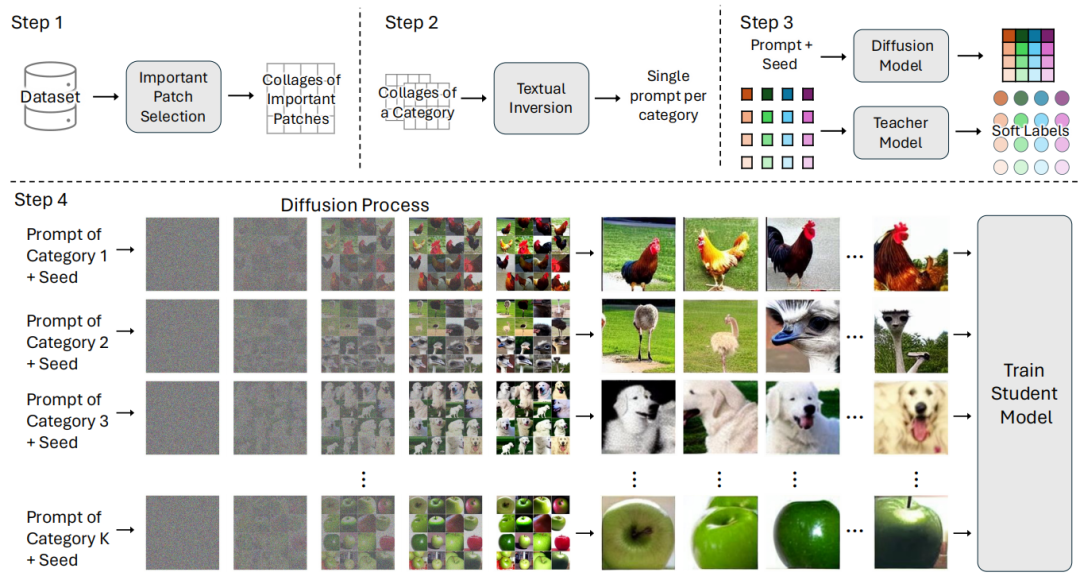
The extensive amounts of data required for training deep neural networks pose significant challenges on storage and transmission fronts. Dataset distillation has emerged as a promising technique to condense the information of massive datasets into a much smaller yet representative set of synthetic samples. However, traditional dataset distillation approaches often struggle to scale effectively with high-resolution images and more complex architectures due to the limitations in bi-level optimization. Recently, several works have proposed exploiting knowledge distillation with decoupled optimization schemes to scale up dataset distillation. Although these methods effectively address the scalability issue, they rely on extensive image augmentations requiring the storage of soft labels for augmented images. In this paper, we introduce Dataset Distillation using Diffusion Models (D3M) as a novel paradigm for dataset distillation, leveraging recent advancements in generative text-to-image foundation models. Our approach utilizes textual inversion, a technique for fine-tuning text-to-image generative models, to create concise and informative representations for large datasets. By employing these learned text prompts, we can efficiently store and infer new samples for introducing data variability within a fixed memory budget. We show the effectiveness of our method through extensive experiments across various computer vision benchmark datasets with different memory budgets.
It's All About Your Sketch: Democratising Sketch Control in Diffusion Models

This paper unravels the potential of sketches for diffusion models, addressing the deceptive promise of direct sketch control in generative AI. We importantly democratise the process, enabling amateur sketches to generate precise images, living up to the commitment of "what you sketch is what you get". A pilot study underscores the necessity, revealing that deformities in existing models stem from spatial-conditioning. To rectify this, we propose an abstraction-aware framework, utilising a sketch adapter, adaptive time-step sampling, and discriminative guidance from a pre-trained fine-grained sketch-based image retrieval model, working synergistically to reinforce fine-grained sketch-photo association. Our approach operates seamlessly during inference without the need for textual prompts; a simple, rough sketch akin to what you and I can create suffices! We welcome everyone to examine results presented in the paper and its supplementary. Contributions include democratising sketch control, introducing an abstraction-aware framework, and leveraging discriminative guidance, validated through extensive experiments.
Time-Efficient and Identity-Consistent Virtual Try-On Using A Variant of Altered Diffusion Models

This study discusses the critical issues of Virtual Try-On in contemporary e-commerce and the prospective metaverse, emphasizing the challenges of preserving intricate texture details and distinctive features of the target person and the clothes in various scenarios, such as clothing texture and identity characteristics like tattoos or accessories. In addition to the fidelity of the synthesized images, the efficiency of the synthesis process presents a significant hurdle. Various existing approaches are explored, highlighting the limitations and unresolved aspects, e.g., identity information omission, uncontrollable artifacts, and low synthesis speed. It then proposes a novel diffusion-based solution that addresses garment texture preservation and user identity retention during virtual try-on. The proposed network comprises two primary modules - a warping module aligning clothing with individual features and a try-on module refining the attire and generating missing parts integrated with a mask-aware post-processing technique ensuring the integrity of the individual's identity. It demonstrates impressive results, surpassing the state-of-the-art in speed by nearly 20 times during inference, with superior fidelity in qualitative assessments. Quantitative evaluations confirm comparable performance with the recent SOTA method on the VITON-HD and Dresscode datasets.
Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM

Human motion generation stands as a significant pursuit in generative computer vision, while achieving long-sequence and efficient motion generation remains challenging. Recent advancements in state space models (SSMs), notably Mamba, have showcased considerable promise in long sequence modeling with an efficient hardware-aware design, which appears to be a promising direction to build motion generation model upon it. Nevertheless, adapting SSMs to motion generation faces hurdles since the lack of a specialized design architecture to model motion sequence. To address these challenges, we propose Motion Mamba, a simple and efficient approach that presents the pioneering motion generation model utilized SSMs. Specifically, we design a Hierarchical Temporal Mamba (HTM) block to process temporal data by ensemble varying numbers of isolated SSM modules across a symmetric U-Net architecture aimed at preserving motion consistency between frames. We also design a Bidirectional Spatial Mamba (BSM) block to bidirectionally process latent poses, to enhance accurate motion generation within a temporal frame. Our proposed method achieves up to 50% FID improvement and up to 4 times faster on the HumanML3D and KIT-ML datasets compared to the previous best diffusion-based method, which demonstrates strong capabilities of high-quality long sequence motion modeling and real-time human motion generation. See project website https://steve-zeyu-zhang.github.io/MotionMamba/
SemGauss-SLAM: Dense Semantic Gaussian Splatting SLAM
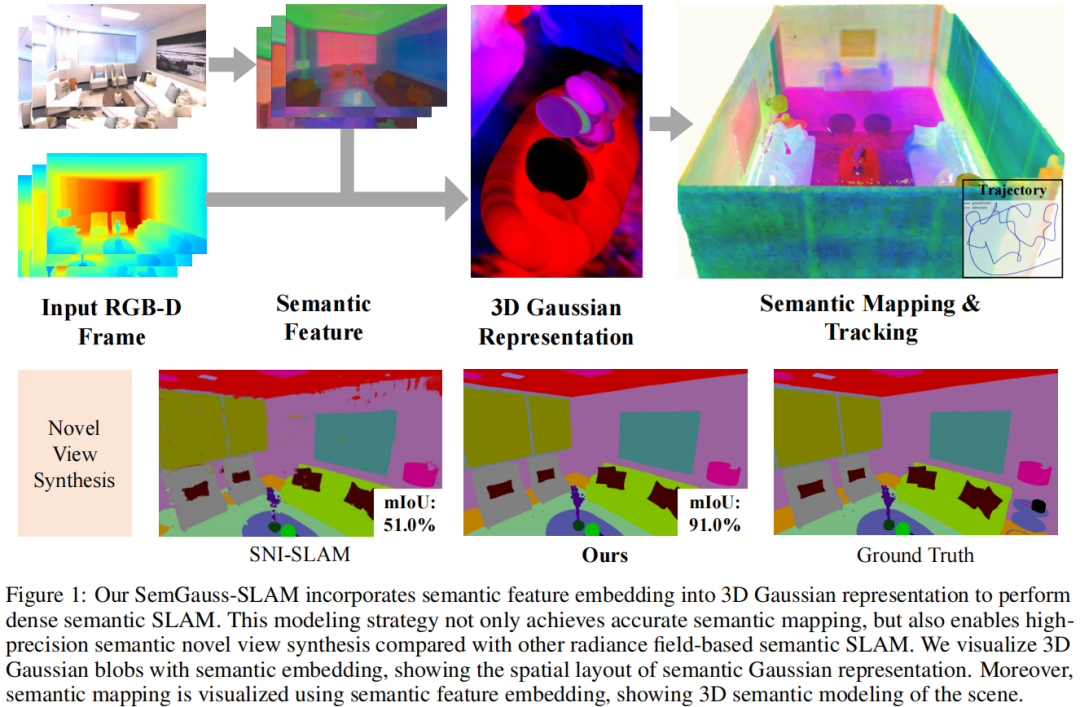
We propose SemGauss-SLAM, the first semantic SLAM system utilizing 3D Gaussian representation, that enables accurate 3D semantic mapping, robust camera tracking, and high-quality rendering in real-time. In this system, we incorporate semantic feature embedding into 3D Gaussian representation, which effectively encodes semantic information within the spatial layout of the environment for precise semantic scene representation. Furthermore, we propose feature-level loss for updating 3D Gaussian representation, enabling higher-level guidance for 3D Gaussian optimization. In addition, to reduce cumulative drift and improve reconstruction accuracy, we introduce semantic-informed bundle adjustment leveraging semantic associations for joint optimization of 3D Gaussian representation and camera poses, leading to more robust tracking and consistent mapping. Our SemGauss-SLAM method demonstrates superior performance over existing dense semantic SLAM methods in terms of mapping and tracking accuracy on Replica and ScanNet datasets, while also showing excellent capabilities in novel-view semantic synthesis and 3D semantic mapping.
Block-wise LoRA: Revisiting Fine-grained LoRA for Effective Personalization and Stylization in Text-to-Image Generation

The objective of personalization and stylization in text-to-image is to instruct a pre-trained diffusion model to analyze new concepts introduced by users and incorporate them into expected styles. Recently, parameter-efficient fine-tuning (PEFT) approaches have been widely adopted to address this task and have greatly propelled the development of this field. Despite their popularity, existing efficient fine-tuning methods still struggle to achieve effective personalization and stylization in T2I generation. To address this issue, we propose block-wise Low-Rank Adaptation (LoRA) to perform fine-grained fine-tuning for different blocks of SD, which can generate images faithful to input prompts and target identity and also with desired style. Extensive experiments demonstrate the effectiveness of the proposed method.
SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces

Given the remarkable achievements in image generation through diffusion models, the research community has shown increasing interest in extending these models to video generation. Recent diffusion models for video generation have predominantly utilized attention layers to extract temporal features. However, attention layers are limited by their memory consumption, which increases quadratically with the length of the sequence. This limitation presents significant challenges when attempting to generate longer video sequences using diffusion models. To overcome this challenge, we propose leveraging state-space models (SSMs). SSMs have recently gained attention as viable alternatives due to their linear memory consumption relative to sequence length. In the experiments, we first evaluate our SSM-based model with UCF101, a standard benchmark of video generation. In addition, to investigate the potential of SSMs for longer video generation, we perform an experiment using the MineRL Navigate dataset, varying the number of frames to 64 and 150. In these settings, our SSM-based model can considerably save memory consumption for longer sequences, while maintaining competitive FVD scores to the attention-based models. Our codes are available at https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models.
Stable-Makeup: When Real-World Makeup Transfer Meets Diffusion Model

Current makeup transfer methods are limited to simple makeup styles, making them difficult to apply in real-world scenarios. In this paper, we introduce Stable-Makeup, a novel diffusion-based makeup transfer method capable of robustly transferring a wide range of real-world makeup, onto user-provided faces. Stable-Makeup is based on a pre-trained diffusion model and utilizes a Detail-Preserving (D-P) makeup encoder to encode makeup details. It also employs content and structural control modules to preserve the content and structural information of the source image. With the aid of our newly added makeup cross-attention layers in U-Net, we can accurately transfer the detailed makeup to the corresponding position in the source image. After content-structure decoupling training, Stable-Makeup can maintain content and the facial structure of the source image. Moreover, our method has demonstrated strong robustness and generalizability, making it applicable to varioustasks such as cross-domain makeup transfer, makeup-guided text-to-image generation and so on. Extensive experiments have demonstrated that our approach delivers state-of-the-art (SOTA) results among existing makeup transfer methods and exhibits a highly promising with broad potential applications in various related fields.
SemCity: Semantic Scene Generation with Triplane Diffusion

We present "SemCity," a 3D diffusion model for semantic scene generation in real-world outdoor environments. Most 3D diffusion models focus on generating a single object, synthetic indoor scenes, or synthetic outdoor scenes, while the generation of real-world outdoor scenes is rarely addressed. In this paper, we concentrate on generating a real-outdoor scene through learning a diffusion model on a real-world outdoor dataset. In contrast to synthetic data, real-outdoor datasets often contain more empty spaces due to sensor limitations, causing challenges in learning real-outdoor distributions. To address this issue, we exploit a triplane representation as a proxy form of scene distributions to be learned by our diffusion model. Furthermore, we propose a triplane manipulation that integrates seamlessly with our triplane diffusion model. The manipulation improves our diffusion model's applicability in a variety of downstream tasks related to outdoor scene generation such as scene inpainting, scene outpainting, and semantic scene completion refinements. In experimental results, we demonstrate that our triplane diffusion model shows meaningful generation results compared with existing work in a real-outdoor dataset, SemanticKITTI. We also show our triplane manipulation facilitates seamlessly adding, removing, or modifying objects within a scene. Further, it also enables the expansion of scenes toward a city-level scale. Finally, we evaluate our method on semantic scene completion refinements where our diffusion model enhances predictions of semantic scene completion networks by learning scene distribution. Our code is available at https://github.com/zoomin-lee/SemCity.
StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting

We introduce StyleGaussian, a novel 3D style transfer technique that allows instant transfer of any image's style to a 3D scene at 10 frames per second (fps). Leveraging 3D Gaussian Splatting (3DGS), StyleGaussian achieves style transfer without compromising its real-time rendering ability and multi-view consistency. It achieves instant style transfer with three steps: embedding, transfer, and decoding. Initially, 2D VGG scene features are embedded into reconstructed 3D Gaussians. Next, the embedded features are transformed according to a reference style image. Finally, the transformed features are decoded into the stylized RGB. StyleGaussian has two novel designs. The first is an efficient feature rendering strategy that first renders low-dimensional features and then maps them into high-dimensional features while embedding VGG features. It cuts the memory consumption significantly and enables 3DGS to render the high-dimensional memory-intensive features. The second is a K-nearest-neighbor-based 3D CNN. Working as the decoder for the stylized features, it eliminates the 2D CNN operations that compromise strict multi-view consistency. Extensive experiments show that StyleGaussian achieves instant 3D stylization with superior stylization quality while preserving real-time rendering and strict multi-view consistency. Project page: https://kunhao-liu.github.io/StyleGaussian/
Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation

Text-to-image generation has made significant advancements with the introduction of text-to-image diffusion models. These models typically consist of a language model that interprets user prompts and a vision model that generates corresponding images. As language and vision models continue to progress in their respective domains, there is a great potential in exploring the replacement of components in text-to-image diffusion models with more advanced counterparts. A broader research objective would therefore be to investigate the integration of any two unrelated language and generative vision models for text-to-image generation. In this paper, we explore this objective and propose LaVi-Bridge, a pipeline that enables the integration of diverse pre-trained language models and generative vision models for text-to-image generation. By leveraging LoRA and adapters, LaVi-Bridge offers a flexible and plug-and-play approach without requiring modifications to the original weights of the language and vision models. Our pipeline is compatible with various language models and generative vision models, accommodating different structures. Within this framework, we demonstrate that incorporating superior modules, such as more advanced language models or generative vision models, results in notable improvements in capabilities like text alignment or image quality. Extensive evaluations have been conducted to verify the effectiveness of LaVi-Bridge. Code is available at https://github.com/ShihaoZhaoZSH/LaVi-Bridge.
Learning Correction Errors via Frequency-Self Attention for Blind Image Super-Resolution
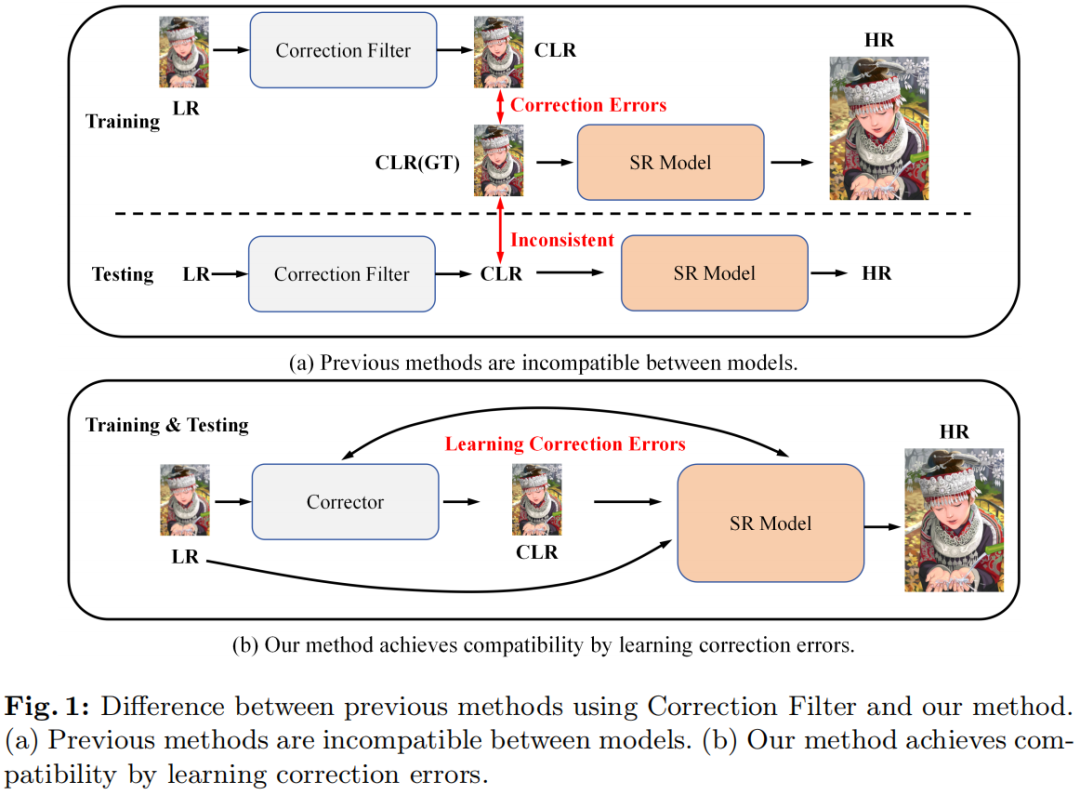
Previous approaches for blind image super-resolution (SR) have relied on degradation estimation to restore high-resolution (HR) images from their low-resolution (LR) counterparts. However, accurate degradation estimation poses significant challenges. The SR model's incompatibility with degradation estimation methods, particularly the Correction Filter, may significantly impair performance as a result of correction errors. In this paper, we introduce a novel blind SR approach that focuses on Learning Correction Errors (LCE). Our method employs a lightweight Corrector to obtain a corrected low-resolution (CLR) image. Subsequently, within an SR network, we jointly optimize SR performance by utilizing both the original LR image and the frequency learning of the CLR image. Additionally, we propose a new Frequency-Self Attention block (FSAB) that enhances the global information utilization ability of Transformer. This block integrates both self-attention and frequency spatial attention mechanisms. Extensive ablation and comparison experiments conducted across various settings demonstrate the superiority of our method in terms of visual quality and accuracy. Our approach effectively addresses the challenges associated with degradation estimation and correction errors, paving the way for more accurate blind image SR.






















![[Linux][CentOs][Mysql]基于Linux-CentOs7.9系统安装并配置开机自启Mysql-8.0.28数据库](https://img-blog.csdnimg.cn/direct/7cfe9f9d3a754645979449480298cb63.png)